
Storm-1.2.2完全分散式安裝
環境:zookeeper-3.4.10,ubuntu-16.0.4,jdk1.8.0_111
我這裡在四臺機器上安裝,分別是Desktop(Master),Server1,(Slave1),Server2(Slave2),Server3(Slave3)
可以將Storm中的nimbus看作是Hadoop中的Master,將supervisor看作是Slave。
安裝Storm之前,需要先安裝zookeeper,點選這裡檢視zookeeper安裝教程
1.解壓
將storm解壓到指定目錄:
[email protected]:~$ tar -zxvf apache-storm-1.2.2.tar.gz -C /usr/local
2.修改配置檔案
修改conf目錄中的storm.yaml檔案:
storm.local.dir: "/usr/local/apache-storm-1.2.2/localdir" storm.zookeeper.port: 2181 storm.zookeeper.servers: - "Desktop" - "Server1" - "Server2" - "Server3" nimbus.seeds: ["Desktop"] ui.host: 0.0.0.0 ui.port: 8080 supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
在設定引數時,不要使用製表符代替空格。
3.新建目錄
mkdir -p /usr/local/apache-storm-1.2.2/localdir4.分發檔案
[email protected]:/usr/local$ scp -r ./apache-storm-1.2.2 [email protected]:/usr/local
[email protected]:/usr/local$ scp -r ./apache-storm-1.2.2 [email protected]:/usr/local
[email protected]:/usr/local$ scp -r ./apache-storm-1.2.2 5.新增環境變數
在每個節點的/etc/profile上新增以下內容:
export STORM_HOME=/usr/local/apache-storm-1.2.2
export PATH=${STORM_HOME}/bin:$PATH每個節點新增完後都執行:source /etc/profile
6.啟動storm
先啟動zkServer
a)在Desktop(Master)上啟動nimbus程序
[email protected]:~$ storm nimbus &
也可以使用:storm nimbus >/dev/null 2>&1 & 該命令下面會有解釋
b)在Desktop(Master)上啟動UI程序
[email protected]:~$ storm ui &
c)在所有的Slave上啟動supervisor程序
[email protected]:~$ storm supervisor &
[email protected]:~$ storm supervisor &
[email protected]:~$ storm supervisor &
7.web登入檢視
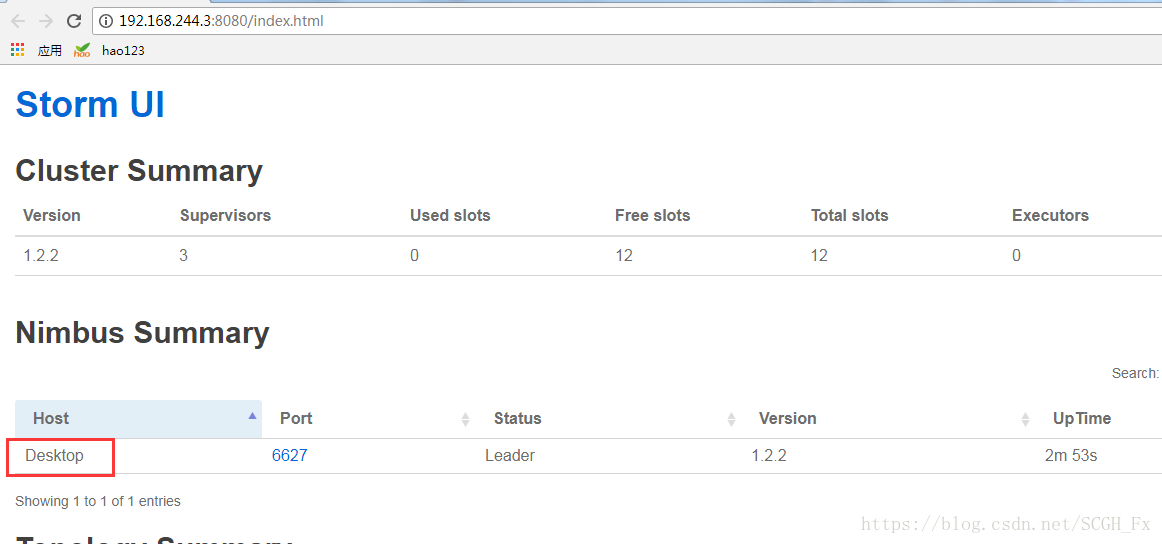
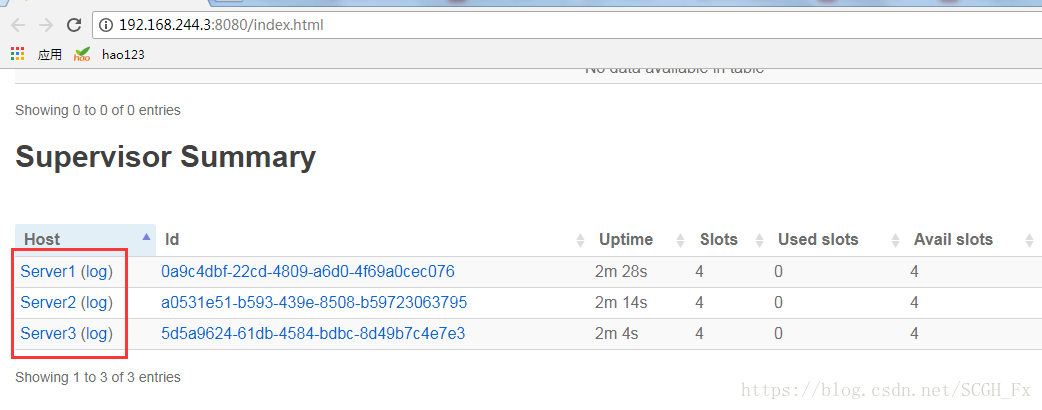
8.可能遇到的問題
a)web不能正常登入
如果登入web的時候,一直顯示loading summary,看不到任何明確的資訊。先檢視logs目錄下的日誌,一般是顯示超時之類的。這應該是某個程序沒有啟動成功。對叢集中的每個節點使用jps命令檢視,看是否有顯示config_value,config_value是沒有啟動成功,對該節點重新啟動(不是重啟主機,是重啟sotrm相關程序)。
如果登入web的時候,網頁進不去,看不到內容(連loading summary都看不到),一直在連結,也沒有提示超時之類的,換瀏覽器也不行,對所有節點全部重啟(不是重啟主機,是重啟sotrm相關程序)。
如果kill或者kill -9都殺不掉某個程序,我暫時沒有找到解決方法,直接重啟主機。
如果登入進去可以看到nimbus或者supervisor等資訊,某些資訊看不到(一直顯示loading summary)。可以換個瀏覽器試試,用谷歌可以正常顯示,用的360就不行,而且360每次都顯示loading summary。
以上幾個問題是我部署完啟動時遇到的問題。
b)nimbus或supervisor不能啟動
雖然執行了啟動命令但是在命令執行完後進程又退出了。首先檢視日誌。如果是nimbus不能啟動,檢視nimbus.log。
一般會有這樣的資訊:
2018-06-07 10:02:30.982 o.a.s.s.o.a.z.ClientCnxn main-SendThread(Desktop:2181) [INFO] Socket connection established to Desktop/192.168.244.3:2181, initiating session
2018-06-07 10:02:30.986 o.a.s.s.o.a.z.ClientCnxn main-SendThread(Desktop:2181) [INFO] Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect
2018-06-07 10:02:31.311 o.a.s.s.o.a.z.ClientCnxn main-SendThread(Desktop:2181) [INFO] Opening socket connection to server Server1/192.168.244.4:2181. Will not attempt to authenticate using SASL (unknown error)
這個是zkServer掛掉了。雖然執行jps可以看到QuorumPeerMain還在,但是實際上zkServer已經掛了。
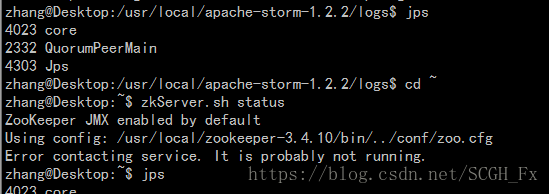
這個是zkServer存活數只有一半(或小於)配置數引起的。比如zookeeper部署了4臺,但是隻起了2臺,預設zkServer狀態就是掛掉了。當再起一臺zkServer,即存活數達到3臺,超過1半了,就可以檢視狀態了。也就是說zkServer叢集已經執行起來了。
前面的問題也就解釋通了,雖然可以看到zkServer程序,但是因為存活數不足,預設zkServer沒有執行起來,所以也就無法啟動nimbus或者supervisor了。
其他參考:
關於bin/storm nimbus >/dev/null 2>&1 &
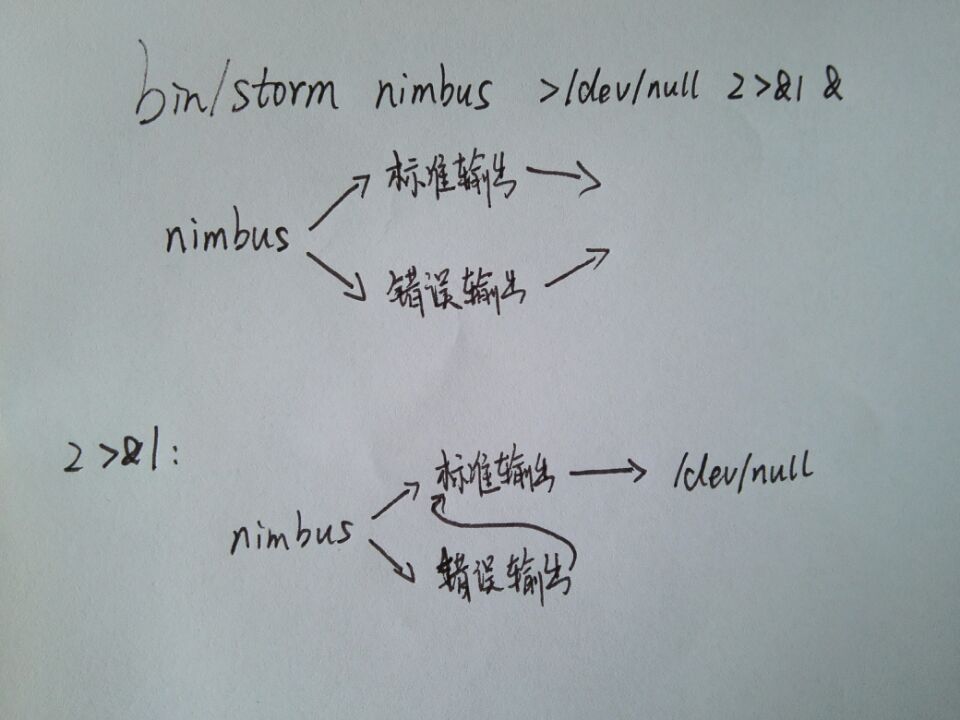
bin/storm nimbus >/dev/null 2>&1 &
如圖所示:
bin/storm nimbus會有兩個輸出,一個標準輸出,一個錯誤輸出
2>&1的作用是將 2即錯誤輸出 的內容重定向到&1即標準輸出中,然後>/dev/null是將兩者的結果輸入到/dev/null中,相當於拋棄掉。至於最後一個&,因為storm會一直執行,不會自動停掉,頁面上就會不停的有內容。&的作用就是將storm拿到後臺執行。
相關推薦
Storm-1.2.2完全分散式安裝
環境:zookeeper-3.4.10,ubuntu-16.0.4,jdk1.8.0_111我這裡在四臺機器上安裝,分別是Desktop(Master),Server1,(Slave1),Server2(Slave2),Server3(Slave3)可以將Storm中的nim
Storm-1.2.2介紹及完全分散式安裝
目錄 1 Storm是什麼 Apache Storm是一個分散式的、可靠的、容錯的實時資料流處理框架。Storm是Twitter開源的分散式實時大資料處理框架,最早開源於github,從0.9.1版本之後,歸於Apache社群,被業界稱為
hadoop2.7.3完全分散式安裝-docker-hive1.2.1-hiveserver2-weave1.9.3
0.環境介紹: 1)ubuntu14.04 docker映象 地址:https://github.com/gaojunhao/ubuntu14.04 2)hadoop2.7.3 地址:http://www.apache.org/dyn/closer.cgi/hadoop/c
HBase 1.2.6 完全分散式叢集安裝部署詳細過程
Apache HBase 是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,是NoSQL資料庫,基於Google Bigtable思想的開源實現,可在廉價的PC Server上搭建大規模結構化儲存叢集,利用Hadoop HDFS作為其檔案儲存系統,利用Hadoo
Hadoop完全分散式安裝2
hadoop簡介: 1.獨立模式(standalone|local)單機模式;所有的產品都安裝在一臺機器上且本地磁碟和副本可以在接下來的xml檔案中 nothing! &
基於hadoop-2.6.0的hbase完全分散式安裝
1.安裝環境:有一個完全分散式的hadoop-2.6.0。 2.安裝準備:需要在網上下一個hbase的壓縮包,我這兒用的是hbase-1.0.3-bin.tar.gz,下載地址here 3.解壓下載好的hbase到一個目錄下,並更改使用者及使用者組(我這兒用
基於hadoop1.2.1的hive偽分散式安裝
主要參考的這篇blog http://www.kankanews.com/ICkengine/archives/72851.shtml 使用的hive版本是hive-0.11.0-bin.tar.gz 作業系統是 ubuntu12.04 64位 1、下載
Hadoop 2.7 偽分散式安裝配置 Error: JAVA_HOME is not set and could not be found.
問題: 如果你明明安裝配置了 JAVA_HOME 卻還是報錯 如果遇到 Error: JAVA_HOME is not set and could not be found. 的錯誤,而你明
ubuntu 16.04 OpenCV3.2.0完全編譯安裝
Opencv可以直接從庫中安裝,也可以自己手動編譯安裝。1、從庫中安裝是最簡單的方式,直接執行下面命令: sudo apt-get install libopencv-dev python-opencv 如果安裝出錯,那麼可以更新一下源,或是換一個源。2、
Storm 1.0.2
單詞計數拓撲WordCountTopology實現的基本功能就是不停地讀入一個個句子,最後輸出每個單詞和數目並在終端不斷的更新結果,拓撲的資料流如下: 語句輸入Spout: 從資料來源不停地讀入資料,並生成一個個句子,輸出的tuple格式:{"sentence"
Hadoop2.7.5+Hbase1.2.6完全分散式搭建
1.叢集安裝主機名MasterzookeeperregionServerMaster11Slave1備份11Slave2112.ssh(在Hadoop分散式搭建中已經完成)3.修改Master中Hbase的conf目錄下regionservers檔案,類似於Hadoop修改s
java大資料最全課程學習筆記(2)--Hadoop完全分散式執行模式
> 目前[CSDN](https://blog.csdn.net/weixin_42208775),[部落格園](https://home.cnblogs.com/u/gitBook/),[簡書](https://www.jianshu.com/u/da41700fde04)同步發表中,更多精彩歡迎訪問
Hadoop完全分散式安裝Hive
編譯安裝 Hive 如果需要直接安裝 Hive,可以跳過編譯步驟,從 Hive 的官網下載編譯好的安裝包,下載地址為http://hive.apache.org/downloads.html。 Hive的環境配置需要MySQL的支援,所以首先需要安裝MySQL,
Hadoop完全分散式安裝zookeeper
D.1安裝 ZooKeeper D.1.1 下載 ZooKeeper ZooKeeper 是 Apache 基金會的一個開源、分散式應用程式協調服務,是 Google 的 Chubby一個開源的實現。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括配置維護、域名服務、分散式同步、
安裝HBase--單節點、偽分散式、完全分散式安裝
1.下載HBase 連結:http://mirrors.cnnic.cn/apache/hbase/ 選擇 stable 目錄,下載 bin 檔案: 在Linux上解壓,部落格中解壓在/home/hadoop 目錄下: 進入解壓目錄: 2.修改配置 修改JD
ZooKeeper完全分散式安裝與配置
Apache ZooKeeper是一個為分散式應用所設計開源協調服務,其設計目是為了減輕分散式應用程式所承擔的協調任務。可以為使用者提供同步、配置管理、分組和命名服務。 1.環境說明 在三臺裝有centos6.5(64位)伺服器上安裝ZooKeeper,官網建議至少3個節點,本
hadoop 完全分散式安裝
一個完全的hadoop分散式安裝至少需要3個zookeeper,3個journalnode,3個datanode,2個namenode組成。 也就是說需要11個節點,但是我雲主機有限,只有3個,所以把很多節點搭在了同一個伺服器上。 步驟: 1.關閉防火牆 service
HBase完全分散式安裝
環境 Linux:Centos Linux 7.3 JDK:jdk1.8.0_181 Hadoop:2.8.5 Zookeeper:3.4.13 HBase:1.4.8 伺服器 bigdata01:192.168.1.50 (主節點) bigdata02:192
Kafka叢集完全分散式安裝
一、上傳、解壓kafka壓縮包 將kafka壓縮包上傳到Linux系統中,並進行解壓 [[email protected] software]# pwd /home/software [[email protected] software]# ll
elasticsearch 完全分散式安裝
1. 首先master節點的配置,修改elasticsearch的配置檔案,config/elasticsearch.yml;新增如下配置 cluster.name 指定叢集的名稱,node.name指定節點的名稱,node.master: true指定該節點為主節點。