
分類演算法-----決策樹
第一篇:從決策樹學習談到貝葉斯分類演算法、EM、HMM
(Machine Learning & Data Mining)
引言
最近在面試中,除了基礎 & 演算法 & 專案之外,經常被問到或被要求介紹和描述下自己所知道的幾種分類或聚類演算法(當然,這完全不代表你將來的面試中會遇到此類問題,只是因為我的簡歷上寫了句:熟悉常見的聚類 & 分類演算法而已),而我向來恨對一個東西只知其皮毛而不得深入,故寫一個有關資料探勘十大演算法的系列文章以作為自己備試之用,甚至以備將來常常回顧思考。行文雜亂,但僥倖若能對讀者起到一點幫助,則幸甚至哉。
本文借鑑和參考了兩本書,一本是Tom M.Mitchhell所著的機器學習,一本是資料探勘導論,這兩本書皆分別是機器學習 & 資料探勘領域的開山 or 槓鼎之作,讀者有繼續深入下去的興趣的話,不妨在閱讀本文之後,課後細細研讀這兩本書。除此之外,還參考了網上不少牛人的作品(文末已註明參考文獻或連結),在此,皆一一表示感謝(從本質上來講,本文更像是一篇讀書 & 備忘筆記)。
說白了,一年多以前,我在本blog內寫過一篇文章,叫做:資料探勘領域十大經典演算法初探(題外話:最初有個出版社的朋友便是因此文找到的我,儘管現在看來,我離出書日期仍是遙遙無期)。現在,我抽取其中幾個最值得一寫的幾個演算法每一個都寫一遍,以期對其有個大致通透的瞭解。OK,全系列任何一篇文章若有任何錯誤,漏洞,或不妥之處,還請讀者們一定要隨時不吝賜教 & 指正,謝謝各位。
分類與聚類,監督學習與無監督學習
在講具體的分類和聚類演算法之前,有必要講一下什麼是分類,什麼是聚類,以及都包含哪些具體演算法或問題。
- Classification (分類),對於一個 classifier ,通常需要你告訴它“這個東西被分為某某類”這樣一些例子,理想情況下,一個 classifier 會從它得到的訓練集中進行“學習”,從而具備對未知資料進行分類的能力,這種提供訓練資料的過程通常叫做 supervised learning (監督學習),
- 而Clustering(聚類),簡單地說就是把相似的東西分到一組,聚類的時候,我們並不關心某一類是什麼,我們需要實現的目標只是把相似的東西聚到一起,因此,一個聚類演算法通常只需要知道如何計算相似 度就可以開始工作了,因此 clustering 通常並不需要使用訓練資料進行學習,這在 Machine Learning 中被稱作 unsupervised learning (無監督學習).
常見的分類與聚類演算法
所謂分類分類,簡單來說,就是根據文字的特徵或屬性,劃分到已有的類別中。如在自然語言處理NLP中,我們經常提到的文字分類便就是一個分類問題,一般的模式分類方法都可用於文字分類研究。常用的分類演算法包括:決策樹分類法,樸素的貝葉斯分類演算法(native Bayesian classifier)、基於支援向量機(SVM)的分類器,神經網路法,k-最近鄰法(k-nearest neighbor,kNN),模糊分類法等等(所有這些分類演算法日後在本blog內都會一一陸續闡述)。
分類作為一種監督學習方法,要求必須事先明確知道各個類別的資訊,並且斷言所有待分類項都有一個類別與之對應。但是很多時候上述條件得不到滿足,尤其是在處理海量資料的時候,如果通過預處理使得資料滿足分類演算法的要求,則代價非常大,這時候可以考慮使用聚類演算法。
而K均值(K-means clustering)聚類則是最典型的聚類演算法(當然,除此之外,還有很多諸如屬於劃分法K-MEDOIDS演算法、CLARANS演算法;屬於層次法的BIRCH演算法、CURE演算法、CHAMELEON演算法等;基於密度的方法:DBSCAN演算法、OPTICS演算法、DENCLUE演算法等;基於網格的方法:STING演算法、CLIQUE演算法、WAVE-CLUSTER演算法;基於模型的方法,本系列後續會介紹其中幾種)。
監督學習與無監督學習
機器學習發展到現在,一般劃分為 監督學習(supervised learning),半監督學習(semi-supervised learning)以及無監督學習(unsupervised learning)三類。舉個具體的對應例子,則是比如說,在NLP詞義消岐中,也分為監督的消岐方法,和無監督的消岐方法。在有監督的消岐方法中,訓練資料是已知的,即每個詞的語義分類是被標註了的;而在無監督的消岐方法中,訓練資料是未經標註的。
上面所介紹的常見的分類演算法屬於監督學習,聚類則屬於無監督學習(反過來說,監督學習屬於分類演算法則不準確,因為監督學習只是說我們給樣本sample同時打上了標籤(label),然後同時利用樣本和標籤進行相應的學習任務,而不是僅僅侷限於分類任務。常見的其他監督問題,比如相似性學習,特徵學習等等也是監督的,但是不是分類)。
再舉個例子,正如人們通過已知病例學習診斷技術那樣,計算機要通過學習才能具有識別各種事物和現象的能力。用來進行學習的材料就是與被識別物件屬於同類的有限數量樣本。監督學習中在給予計算機學習樣本的同時,還告訴計算各個樣本所屬的類別。若所給的學習樣本不帶有類別資訊,就是無監督學習(淺顯點說:同樣是學習訓練,監督學習中,給的樣例比如是已經標註瞭如心臟病的,肝炎的;而無監督學習中,就是給你一大堆的樣例,沒有標明是何種病例的)。
而在支援向量機導論一書給監督學習下的定義是:當樣例是輸入/輸出對給出時,稱為監督學習,有關輸入/輸出函式關係的樣例稱為訓練資料。而在無監督學習中,其資料不包含輸出值,學習的任務是理解資料產生的過程。
第一部分、決策樹學習
1.1、什麼是決策樹
咱們直接切入正題。所謂決策樹,顧名思義,是一種樹,一種依託於策略抉擇而建立起來的樹。
機器學習中,決策樹是一個預測模型;他代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的物件的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。
從資料產生決策樹的機器學習技術叫做決策樹學習, 通俗點說就是決策樹,說白了,這是一種依託於分類、訓練上的預測樹,根據已知預測、歸類未來。
來理論的太過抽象,下面舉兩個淺顯易懂的例子:
第一個例子
套用俗語,決策樹分類的思想類似於找物件。現想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話:
女兒:多大年紀了?
母親:26。
女兒:長的帥不帥?
母親:挺帥的。
女兒:收入高不?
母親:不算很高,中等情況。
女兒:是公務員不?
母親:是,在稅務局上班呢。
女兒:那好,我去見見。
這個女孩的決策過程就是典型的分類樹決策。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上並且是高收入者或中等以上收入的公務員,那麼這個可以用下圖表示女孩的決策邏輯:
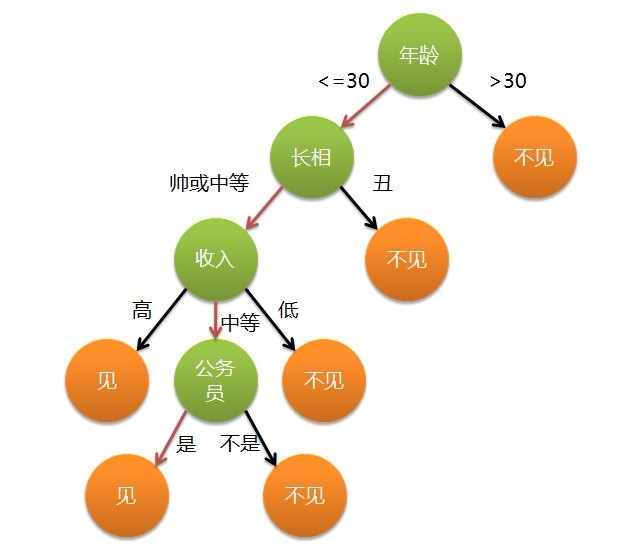
也就是說,決策樹的簡單策略就是,好比公司招聘面試過程中篩選一個人的簡歷,如果你的條件相當好比如說某985/211重點大學博士畢業,那麼二話不說,直接叫過來面試,如果非重點大學畢業,但實際專案經驗豐富,那麼也要考慮叫過來面試一下,即所謂具體情況具體分析、決策。但每一個未知的選項都是可以歸類到已有的分類類別中的。
第二個例子
此例子來自Tom M.Mitchell著的機器學習一書:
小王的目的是通過下週天氣預報尋找什麼時候人們會打高爾夫,他了解到人們決定是否打球的原因最主要取決於天氣情況。而天氣狀況有晴,雲和雨;氣溫用華氏溫度表示;相對溼度用百分比;還有有無風。如此,我們便可以構造一棵決策樹,如下(根據天氣這個分類決策這天是否合適打網球):
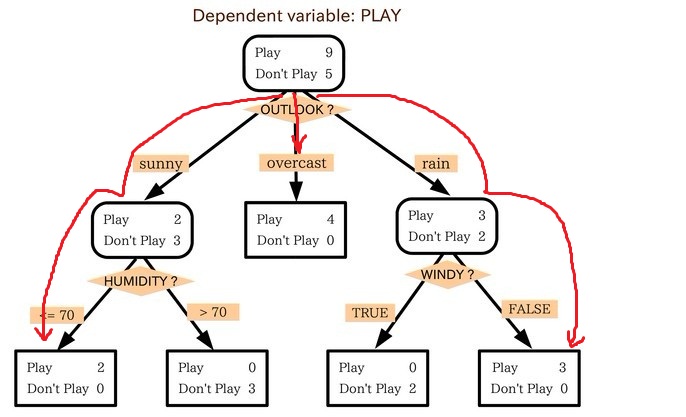
上述決策樹對應於以下表達式:
(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)
1.2、ID3演算法
1.2.1、決策樹學習之ID3演算法
ID3演算法是決策樹演算法的一種。想了解什麼是ID3演算法之前,我們得先明白一個概念:奧卡姆剃刀。
- 奧卡姆剃刀(Occam's Razor, Ockham's Razor),又稱“奧坎的剃刀”,是由14世紀邏輯學家、聖方濟各會修士奧卡姆的威廉(William of Occam,約1285年至1349年)提出,他在《箴言書注》2卷15題說“切勿浪費較多東西,去做‘用較少的東西,同樣可以做好的事情’。簡單點說,便是:be simple。
OK,從資訊理論知識中我們知道,期望資訊越小,資訊增益越大,從而純度越高。ID3演算法的核心思想就是以資訊增益度量屬性選擇,選擇分裂後資訊增益(很快,由下文你就會知道資訊增益又是怎麼一回事)最大的屬性進行分裂。該演算法採用自頂向下的貪婪搜尋遍歷可能的決策樹空間。
所以,ID3的思想便是:
- 自頂向下的貪婪搜尋遍歷可能的決策樹空間構造決策樹(此方法是ID3演算法和C4.5演算法的基礎);
- 從“哪一個屬性將在樹的根節點被測試”開始;
- 使用統計測試來確定每一個例項屬性單獨分類訓練樣例的能力,分類能力最好的屬性作為樹的根結點測試(如何定義或者評判一個屬性是分類能力最好的呢?這便是下文將要介紹的資訊增益,or 資訊增益率)。
- 然後為根結點屬性的每個可能值產生一個分支,並把訓練樣例排列到適當的分支(也就是說,樣例的該屬性值對應的分支)之下。
- 重複這個過程,用每個分支結點關聯的訓練樣例來選取在該點被測試的最佳屬性。
這形成了對合格決策樹的貪婪搜尋,也就是演算法從不回溯重新考慮以前的選擇。
下圖所示即是用於學習布林函式的ID3演算法概要:

1.2.2、哪個屬性是最佳的分類屬性
1、資訊增益的度量標準:熵上文中,我們提到:“ID3演算法的核心思想就是以資訊增益度量屬性選擇,選擇分裂後資訊增益(很快,由下文你就會知道資訊增益又是怎麼一回事)最大的屬性進行分裂。”接下來,咱們就來看看這個資訊增益是個什麼概念(當然,在瞭解資訊增益之前,你必須先理解:資訊增益的度量標準:熵)。 上述的ID3演算法的核心問題是選取在樹的每個結點要測試的屬性。我們希望選擇的是最有利於分類例項的屬性,資訊增益(Information Gain)是用來衡量給定的屬性區分訓練樣例的能力,而ID3演算法在增長樹的每一步使用資訊增益從候選屬性中選擇屬性。
為了精確地定義資訊增益,我們先定義資訊理論中廣泛使用的一個度量標準,稱為熵(entropy),它刻畫了任意樣例集的純度(purity)。給定包含關於某個目標概念的正反樣例的樣例集S,那麼S相對這個布林型分類的熵為:
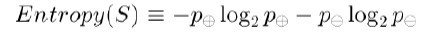
上述公式中,p+代表正樣例,比如在本文開頭第二個例子中p+則意味著去打羽毛球,而p-則代表反樣例,不去打球(在有關熵的所有計算中我們定義0log0為0)。
如果寫程式碼實現熵的計算,則如下所示:
- //根據具體屬性和值來計算熵
- double ComputeEntropy(vector <vector <string> > remain_state, string attribute, string value,bool ifparent){
- vector<int> count (2,0);
- unsigned int i,j;
- bool done_flag = false;//哨兵值
- for(j = 1; j < MAXLEN; j++){
- if(done_flag) break;
- if(!attribute_row[j].compare(attribute)){
- for(i = 1; i < remain_state.size(); i++){
- if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent記錄是否算父節點
- if(!remain_state[i][MAXLEN - 1].compare(yes)){
- count[0]++;
- }
- else count[1]++;
- }
- }
- done_flag = true;
- }
- }
- if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正例項或者負例項
- //具體計算熵 根據[+count[0],-count[1]],log2為底通過換底公式換成自然數底數
- double sum = count[0] + count[1];
- double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0);
- return entropy;
- }
舉例來說,假設S是一個關於布林概念的有14個樣例的集合,它包括9個正例和5個反例(我們採用記號[9+,5-]來概括這樣的資料樣例),那麼S相對於這個布林樣例的熵為:
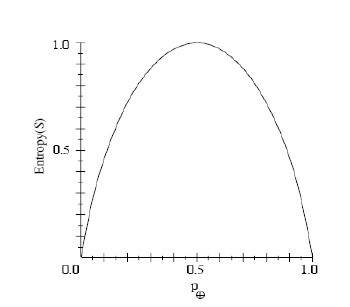
So,根據上述這個公式,我們可以得到:S的所有成員屬於同一類,Entropy(S)=0; S的正反樣例數量相等,Entropy(S)=1;S的正反樣例數量不等,熵介於0,1之間,如下圖所示:Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
資訊理論中對熵的一種解釋,熵確定了要編碼集合S中任意成員的分類所需要的最少二進位制位數。更一般地,如果目標屬性具有c個不同的值,那麼S相對於c個狀態的分類的熵定義為:
Pi為子集合中不同性(而二元分類即正樣例和負樣例)的樣例的比例。
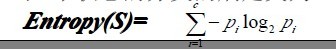
2、資訊增益度量期望的熵降低
資訊增益Gain(S,A)定義
已經有了熵作為衡量訓練樣例集合純度的標準,現在可以定義屬性分類訓練資料的效力的度量標準。這個標準被稱為“資訊增益(information gain)”。簡單的說,一個屬性的資訊增益就是由於使用這個屬性分割樣例而導致的期望熵降低(或者說,樣本按照某屬性劃分時造成熵減少的期望)。更精確地講,一個屬性A相對樣例集合S的資訊增益Gain(S,A)被定義為:

其中 Values(A)是屬性A所有可能值的集合,是S中屬性A的值為v的子集。換句話來講,Gain(S,A)是由於給定屬性A的值而得到的關於目標函式值的資訊。當對S的一個任意成員的目標值編碼時,Gain(S,A)的值是在知道屬性A的值後可以節省的二進位制位數。
接下來,有必要提醒讀者一下:關於下面這兩個概念 or 公式,
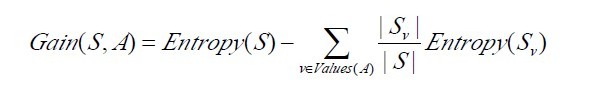
下面,舉個例子,假定S是一套有關天氣的訓練樣例,描述它的屬性包括可能是具有Weak和Strong兩個值的Wind。像前面一樣,假定S包含14個樣例,[9+,5-]。在這14個樣例中,假定正例中的6個和反例中的2個有Wind =Weak,其他的有Wind=Strong。由於按照屬性Wind分類14個樣例得到的資訊增益可以計算如下。
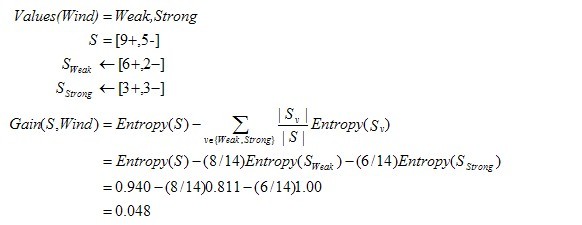
運用在本文開頭舉得第二個根據天氣情況是否決定打羽毛球的例子上,得到的最佳分類屬性如下圖所示:
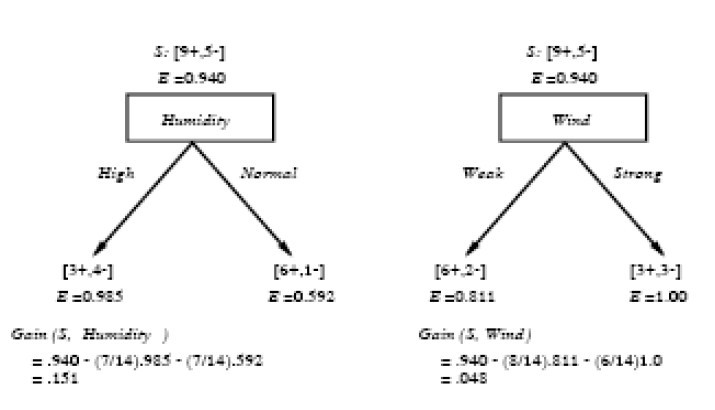
在上圖中,計算了兩個不同屬性:溼度(humidity)和風力(wind)的資訊增益,最終humidity這種分類的資訊增益0.151>wind增益的0.048。說白了,就是在星期六上午是否適合打網球的問題訣策中,採取humidity較wind作為分類屬性更佳,決策樹由此而來。
- //計算資訊增益,DFS構建決策樹
- //current_node為當前的節點
- //remain_state為剩餘待分類的樣例
- //remian_attribute為剩餘還沒有考慮的屬性
- //返回根結點指標
- Node * BulidDecisionTreeDFS(Node * p, vector <vector <string> > remain_state, vector <string> remain_attribute){
- //if(remain_state.size() > 0){
- //printv(remain_state);
- //}
- if (p == NULL)
- p = new Node();
- //先看搜尋到樹葉的情況
- if (AllTheSameLabel(remain_state, yes)){
- p->attribute = yes;
- return p;
- }
- if (AllTheSameLabel(remain_state, no)){
- p->attribute = no;
- return p;
- }
- if(remain_attribute.size() == 0){//所有的屬性均已經考慮完了,還沒有分盡
- string label = MostCommonLabel(remain_state);
- p->attribute = label;
- return p;
- }
- double max_gain = 0, temp_gain;
- vector <string>::iterator max_it;
- vector <string>::iterator it1;
- for(it1 = remain_attribute.begin(); it1 < remain_attribute.end(); it1++){
- temp_gain = ComputeGain(remain_state, (*it1));
- if(temp_gain > max_gain) {
- max_gain = temp_gain;
- max_it = it1;
- }
- }
- //下面根據max_it指向的屬性來劃分當前樣例,更新樣例集和屬性集
- vector <string> new_attribute;
- vector <vector <string> > new_state;
- for(vector <string>::iterator it2 = remain_attribute.begin(); it2 < remain_attribute.end(); it2++){
- if((*it2).compare(*max_it)) new_attribute.push_back(*it2);
- }
- //確定了最佳劃分屬性,注意儲存
- p->attribute = *max_it;
- vector <string> values = map_attribute_values[*max_it];
- int attribue_num = FindAttriNumByName(*max_it);
- new_state.push_back(attribute_row);
- for(vector <string>::iterator it3 = values.begin(); it3 < values.end(); it3++){
- for(unsigned int i = 1; i < remain_state.size(); i++){
- if(!remain_state[i][attribue_num].compare(*it3)){
- new_state.push_back(remain_state[i]);
- }
- }
- Node * new_node = new Node();
- new_node->arrived_value = *it3;
- if(new_state.size() == 0){//表示當前沒有這個分支的樣例,當前的new_node為葉子節點
- new_node->attribute = MostCommonLabel(remain_state);
- }
- else
- BulidDecisionTreeDFS(new_node, new_state, new_attribute);
- //遞迴函式返回時即回溯時需要1 將新結點加入父節點孩子容器 2清除new_state容器
- p->childs.push_back(new_node);
- new_state.erase(new_state.begin()+1,new_state.end());//注意先清空new_state中的前一個取值的樣例,準備遍歷下一個取值樣例
- }
- return p;
- }
1.2.3、ID3演算法決策樹的形成
OK,下圖為ID3演算法第一步後形成的部分決策樹。這樣綜合起來看,就容易理解多了。1、overcast樣例必為正,所以為葉子結點,總為yes;2、ID3無回溯,區域性最優,而非全域性最優,還有另一種樹後修剪決策樹。下圖是ID3演算法第一步後形成的部分決策樹:
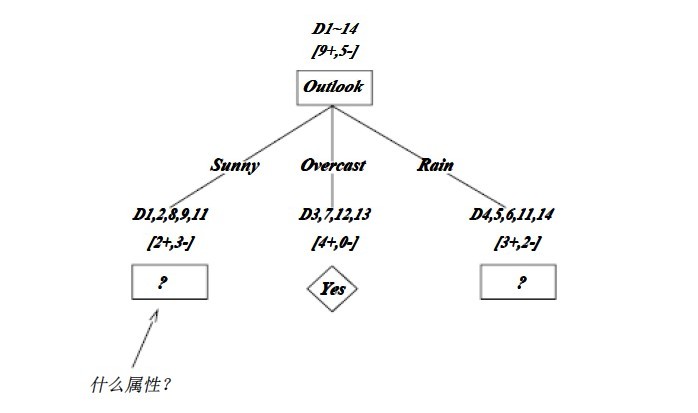
如上圖,訓練樣例被排列到對應的分支結點。分支Overcast的所有樣例都是正例,所以成為目標分類為Yes的葉結點。另兩個結點將被進一步展開,方法是按照新的樣例子集選取資訊增益最高的屬性。
1.3、C4.5演算法
1.3.1、ID3演算法的改進:C4.5演算法C4.5,是機器學習演算法中的另一個分類決策樹演算法,它是決策樹(決策樹也就是做決策的節點間的組織方式像一棵樹,其實是一個倒樹)核心演算法,也是上文1.2節所介紹的ID3的改進演算法,所以基本上了解了一半決策樹構造方法就能構造它。
決策樹構造方法其實就是每次選擇一個好的特徵以及分裂點作為當前節點的分類條件。
既然說C4.5演算法是ID3的改進演算法,那麼C4.5相比於ID3改進的地方有哪些呢?:
- 用資訊增益率來選擇屬性。ID3選擇屬性用的是子樹的資訊增益,這裡可以用很多方法來定義資訊,ID3使用的是熵(entropy,熵是一種不純度度量準則),也就是熵的變化值,而C4.5用的是資訊增益率。對,區別就在於一個是資訊增益,一個是資訊增益率。
- 在樹構造過程中進行剪枝,在構造決策樹的時候,那些掛著幾個元素的節點,不考慮最好,不然容易導致overfitting。
- 對非離散資料也能處理。
- 能夠對不完整資料進行處理
針對上述第一點,解釋下:一般來說率就是用來取平衡用的,就像方差起的作用差不多,比如有兩個跑步的人,一個起點是10m/s的人、其10s後為20m/s;另一個人起速是1m/s、其1s後為2m/s。如果緊緊算差值那麼兩個差距就很大了,如果使用速度增加率(加速度,即都是為1m/s^2)來衡量,2個人就是一樣的加速度。因此,C4.5克服了ID3用資訊增益選擇屬性時偏向選擇取值多的屬性的不足。
C4.5演算法之資訊增益率
OK,既然上文中提到C4.5用的是資訊增益率,那增益率的具體是如何定義的呢?:
是的,在這裡,C4.5演算法不再是通過資訊增益來選擇決策屬性。一個可以選擇的度量標準是增益比率gain ratio(Quinlan 1986)。增益比率度量是用前面的增益度量Gain(S,A)和分裂資訊度量SplitInformation(S,A)來共同定義的,如下所示:
其中,分裂資訊度量被定義為(分裂資訊用來衡量屬性分裂資料的廣度和均勻):
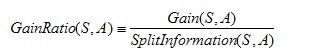
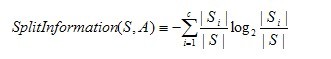
其中S1到Sc是c個值的屬性A分割S而形成的c個樣例子集。注意分裂資訊實際上就是S關於屬性A的各值的熵。這與我們前面對熵的使用不同,在那裡我們只考慮S關於學習到的樹要預測的目標屬性的值的熵。
請注意,分裂資訊項阻礙選擇值為均勻分佈的屬性。例如,考慮一個含有n個樣例的集合被屬性A徹底分割(譯註:分成n組,即一個樣例一組)。這時分裂資訊的值為log2n。相反,一個布林屬性B分割同樣的n個例項,如果恰好平分兩半,那麼分裂資訊是1。如果屬性A和B產生同樣的資訊增益,那麼根據增益比率度量,明顯B會得分更高。
使用增益比率代替增益來選擇屬性產生的一個實際問題是,當某個Si接近S(|Si|?|S|)時分母可能為0或非常小。如果某個屬性對於S的所有樣例有幾乎同樣的值,這時要麼導致增益比率未定義,要麼是增益比率非常大。為了避免選擇這種屬性,我們可以採用這樣一些啟發式規則,比如先計算每個屬性的增益,然後僅對那些增益高過平均值的屬性應用增益比率測試(Quinlan 1986)。
除了資訊增益,Lopez de Mantaras(1991)介紹了另一種直接針對上述問題而設計的度量,它是基於距離的(distance-based)。這個度量標準基於所定義的一個數據劃分間的距離尺度。具體更多請參看:Tom M.Mitchhell所著的機器學習之3.7.3節。
1.3.2、C4.5演算法構造決策樹的過程
- Function C4.5(R:包含連續屬性的無類別屬性集合,C:類別屬性,S:訓練集)
- /*返回一棵決策樹*/
- Begin
- If S為空,返回一個值為Failure的單個節點;
- If S是由相同類別屬性值的記錄組成,
- 返回一個帶有該值的單個節點;
- If R為空,則返回一個單節點,其值為在S的記錄中找出的頻率最高的類別屬性值;
- [注意未出現錯誤則意味著是不適合分類的記錄];
- For 所有的屬性R(Ri) Do
- If 屬性Ri為連續屬性,則
- Begin
- 將Ri的最小值賦給A1:
- 將Rm的最大值賦給Am;/*m值手工設定*/
- For j From 2 To m-1 Do Aj=A1+j*(A1Am)/m;
- 將Ri點的基於{< =Aj,>Aj}的最大資訊增益屬性(Ri,S)賦給A;
- End;
- 將R中屬性之間具有最大資訊增益的屬性(D,S)賦給D;
- 將屬性D的值賦給{dj/j=1,2...m};
- 將分別由對應於D的值為dj的記錄組成的S的子集賦給{sj/j=1,2...m};
- 返回一棵樹,其根標記為D;樹枝標記為d1,d2...dm;
- 再分別構造以下樹:
- C4.5(R-{D},C,S1),C4.5(R-{D},C,S2)...C4.5(R-{D},C,Sm);
- End C4.5
1.3.3、C4.5演算法實現中的幾個關鍵步驟
在上文中,我們已經知道了決策樹學習C4.5演算法中4個重要概念的表達,如下:
- double C4_5::entropy(int *attrClassCount, int classNum, int allNum){
- double iEntropy = 0.0;
- for(int i = 0; i < classNum; i++){
- double temp = ((double)attrClassCount[i]) / allNum;
- if(temp != 0.0)
- iEntropy -= temp * (log(temp) / log(2.0));
- }
- return iEntropy;
- }
- double C4_5::gainRatio(int classNum, vector<int *> attriCount, double pEntropy){
- int* attriNum = newint[attriCount.size()];
- int allNum = 0;
- for(int i = 0; i < (int)attriCount.size(); i++){
- attriNum[i] = 0;
-
for(
相關推薦
機器學習分類演算法---決策樹
決策樹: 樹結構,可以是二叉樹或非二叉樹,資料結構中的概念,只不過加上了判斷條件。 資訊熵: 1948年,夏農提出了“資訊熵”的概念。一條資訊的資訊量大小和它的不確定性有直接的關係,即對一件事,你不知道的越多,這件事對於你來說資訊熵越大,因為你需要學的東西更多。 &nb
分類演算法-----決策樹
第一篇:從決策樹學習談到貝葉斯分類演算法、EM、HMM (Machine Learning & Data Mining) 引言 最近在面試中,除了基礎 & 演算法 & 專案之外,經
[機器學習]詳解分類演算法--決策樹演算法
前言 演算法的有趣之處在於解決問題,否則僅僅立足於理論,便毫無樂趣可言; 不過演算法的另一特點就是容易嚇唬人,又是公式又是圖示啥的,如果一個人數學理論知識過硬,靜下心來看,都是可以容易理解的,紙老虎一個,不過這裡的演算法主要指的應用型演算法
javascript實現樸素貝葉斯分類與決策樹ID3分類
.com 訓練集 this ice map ive sum length roc 今年畢業時的畢設是有關大數據及機器學習的題目。因為那個時間已經步入前端的行業自然選擇使用JavaScript來實現其中具體的算法。雖然JavaScript不是做大數據處理的最佳語言,相比還沒有
R_Studio(cart演算法決策樹)對book3.csv資料用測試集進行測試並評估模型
對book3.csv資料集,實現如下功能: (1)建立訓練集、測試集 (2)用rpart包建立關於類別的cart演算法的決策樹 (3)用測試集進行測試,並評估模型 book3.csv資料集 se
R教材11.1 分類與決策樹
分類目的:根據一組預測變數來預測相對應的分類結果,實現對新出單元的準確分類 有監督學習:基於已知類的資料樣本,將全部資料分為訓練集和驗證集 用到的包:rpart,rpart.plot,party,randomForest,e1071 隨機抽樣: set.se
機器學習分類器---決策樹
一、決策樹 經常使用決策樹來處理分類問題,決策樹也是最經常使用的資料探勘演算法,不需要了解機器學習的知識,就能搞明白決策樹是如何工作的。 kNN演算法可以完成很多分類任務,但它最大的缺點就是無法給出資料的內在含義,決策樹的主要優勢在於資料形式非常容易理解 決策樹能夠讀取資
多分類問題決策樹資料分析-大資料ML樣本集案例實戰
版權宣告:本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。QQ郵箱地址:[email protected],如有任何學術交流,可隨時聯絡。 1 資料預處理 DF加上表頭
機器學習---演算法---決策樹
轉自:https://blog.csdn.net/qq_43208303/article/details/84837412 決策樹是一種機器學習的方法。決策樹的生成演算法有ID3, C4.5和CART等。決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的判斷,每個分支代表一個判斷結果的輸
機器學習演算法——決策樹
一、機器學習中分類與預測演算法評估 1、準確率 2、速度 3、強壯性 4、可規模性 5、可解釋性 在機器學習演算法當中、評價一個演算法的好壞或者比較
機器學習演算法--決策樹2
以機器學習實戰決策樹為例,實現具體的決策樹演算法: 1.資訊增益的實現 2.劃分資料集 3.遞迴構建決策樹 4.使用matplotlib構造決策樹 5.測試和儲存決策樹 6.例項--隱形眼鏡型別 1.資訊增益的實現 集合D中類別數y,各種類別概率為pk,則集合
分類:決策樹——樹的生長
att false 從數據 name 判斷 width 多個 data 集合 分類算法非常適合預測或描述標簽為二元或標稱類型的數據集,對於標簽為序數類型的數據集,分類技術則不太有效,因為分類技術不考慮隱藏在序數中的“序”關系,對於標簽其他形式的聯系如子類與超類
人工智慧演算法—決策樹
文/騰訊soso林世飛 決策樹方法最早產生於上世紀60年代,到70年代末。由J Ross Quinlan提出了ID3演算法,此演算法的目的在於減少樹的深度。但是忽略了葉子數目的研究。C4.5演算法在ID3演算法的基礎上進行了改進,對於預測變數的缺值處理、剪
模式識別:分類迴歸決策樹CART的研究與實現
摘 要:本實驗的目的是學習和掌握分類迴歸樹演算法。CART提供一種通用的樹生長框架,它可以例項化為各種各樣不同的判定樹。CART演算法採用一種二分遞迴分割的技術,將當前的樣本集分為兩個子樣本集,使得生成的決策樹的每個非葉子節點都有兩個分支。因此,CART演
[DataAnalysis]機器學習演算法——決策樹詳解(屬性劃分+剪枝+缺失值/連續值處理)
決策樹簡述 決策樹是一種用於對例項進行分類的樹形結構。決策樹由節點(node)和有向邊(directed edge)組成。節點分成根節點、內節點(表示一個特徵或者屬性的測試條件)和葉子節點(表示一個分類)。 決策樹的生成是一個遞迴過程。在決策樹演算法中,有三種情形會導致遞
ID3演算法 改進的C4.5演算法 決策樹演算法
最早的決策時演算法是由 Hunt 等人於 1966 年提出的 CLS 。當前最有影 響的決策樹演算法是 Quinlan 於 1986 年提出的 ID3 和 1993 年提出的 C4.5 。 ID3 只能處理離散型描述屬性,它選擇資訊增益最大的屬性劃分訓練樣本, 其目的是進行分枝時系統的熵最小,從而提高演算法
機器學習演算法 --- 決策樹ID3,C4.5
一、決策樹基本概念及演算法優缺點 1.什麼是決策樹 分類決策樹模型是一種描述對例項進行分類的樹形結構。決策樹由結點和有向邊組成。結點有兩種型別:內部結點和葉結點。內部結點表示一個特徵或屬性,葉結點表示一個類。 決策樹(Decision Tree),又稱判定
決策樹C4 5分類演算法的C++實現
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
決策樹(三)分類演算法小結
引言 本文主要是對分型別決策樹的一個總結。在分類問題中,決策樹可以被看做是if-then規則的結合,也可以認為是在特定特徵空間與類空間上的條件概率分佈。決策樹學習主要分為三個步驟:特徵選擇、決策樹的生成與剪枝操作。本文簡單總結ID3和C4.5演算法,之後是決策樹的修剪。 ID3演算法 ID3演算法和核
第4章 決策樹演算法【分類】(五 決策樹sklearn總結和視覺化總結)
4.7 決策樹sklearn總結 參考文件: 中文連結 英文連結 API: 中文連結 英文連結 scikit-learn決策樹演算法類庫內部實現是使用了調優過的CART樹演算法,既可以做分類,又可以做迴歸。分類決策樹的類對應的是DecisionTreeClass