
機器學習演算法——決策樹
一、機器學習中分類與預測演算法評估
1、準確率
2、速度
3、強壯性
4、可規模性
5、可解釋性
在機器學習演算法當中、評價一個演算法的好壞或者比較兩個演算法的優劣,主要以上5個方面進行評估。首先準確率是指演算法分類或者預測的準確程度,這是個非常重要的標準,而速度是指演算法的複雜度高不高,其次強壯行是指一個演算法在包含噪音、缺失值、異常值的資料中依然保持非常好的效率 ,可規模性是指一個演算法不僅可以在小規模資料上保持高效,在呈指數型增長的資料中依然能保持高效,最後可解釋性是指演算法在做出特徵值的選取和歸類能容易的解釋這種歸類和我們的直覺是相符的。
二、決策樹
1、什麼是決策樹/判定書(decision tree)?
決策樹是類似於流程圖的樹結構:其中,每個內部節點表示在一個屬性上的測試,每個分支表示一個屬性的輸出,而每個樹葉節點表示一個類或者類分佈。樹的最頂層是根節點。
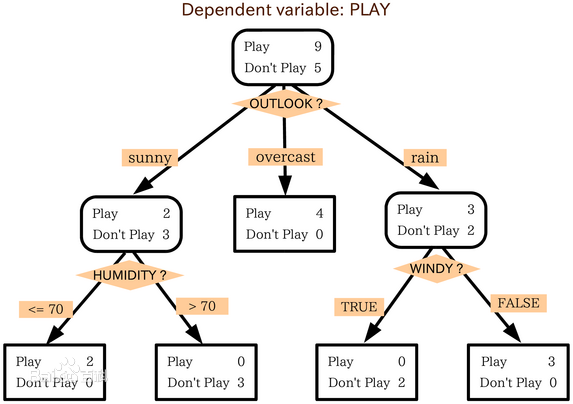
以上圖為例,該決策樹的屬性有:OUTLOOK、HUMIDITY、WINDY,以OUTLOOK屬性為根節點,OUTLOOK有三個取值,即sunny、overcast、rain,根節點的三個分支就是它三個值的輸出。決策樹有五個葉子,葉子代表已經分好的類,即Play或者Don't Play。
2、構造ID3決策樹基本演算法
概念
資訊熵(entropy):
資訊和抽象,如何度量?
1948年,夏農提出了 ”資訊熵(entropy)“的概念
一條資訊的資訊量大小和它的不確定性有直接的關係,要搞清楚一件非常非常不確定的事情,或者
是我們一無所知的事情,需要了解大量資訊==>資訊量的度量就等於不確定性的多少
所以資訊熵就是指資訊的不確定度,不確定度越高,資訊越複雜。
樣本D中第i個類樣本所佔的概率為pi(i=1,2,3,.....y),則資訊熵的定義公式為:

資訊增益(information gain)
我們繼續瞭解資訊增益
假定離散屬性a有V個可能的取值{a1,a2,a3.....av},比如性別有{男,女}兩個取值,若用a屬性對樣本集進行劃分,可以得到V個分支節點,其中第V個節點,包含了D所有再a屬性上取值為a v的樣本,記為Dv,我們根據上面的資訊熵的公式可以算出Dv的資訊熵,顯而易見,每個分支所包含的樣本數是不一樣的,所以給每個分支賦予權重|Dv|/|D|,就是說,分支的樣本數量多的對分支影響越大。則可以算出屬性a對樣本集D劃分所得到的“資訊增益”,以下為資訊增益的公式:
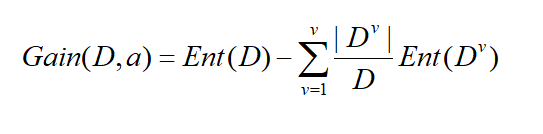
一般來說,資訊增益越大,屬性a對樣本集D劃分純度越到,因此資訊增益大的優先作為決策樹的屬性節點。所以以資訊增益為準則來選擇劃分屬性。
來,我們直接上例子

這是一個電腦銷售的記錄,表示為樣本D,顯而易見,表中有四個測試屬性,即age、income、student、credit_rating,一個分類屬性,即buys_computer 。age屬性取值有{youth ,middle_aged,senior}、income屬性取值有{low、medium、high}、student{yes、no}、credit_rating屬性取值為{fair、excellent}。現在·以各屬性的資訊增益為準則,選出決策樹的根節點。
現在以income屬性為例,income屬性取值有{low、medium、high},則將對樣本D劃分為三個分支,得到三個子集,分別記為D1={income=low} ,D2 ={income=medium},D3 ={income=high} 。D1包含的編號有{5,6,7,9}的4個樣例,buys_computer為yes的有3例,即p1=3/4,為no有1例,即p2=1/4,D2包含的編號有{4,8,10,11,12,14}的6個樣例,正例佔q1=4/6,反例佔q2=2/6,D3包含的編號有{1,2,3,13}的4個樣例,正例佔o1=2/4,反例佔o2=2/4。
根據資訊熵的公式,先計算根節點的資訊熵,樣本集D有14個樣例,正例佔p=9/14,反例佔q=5/14:

這裡忘記說明,資訊熵的單位是位元(bits)
現在算出根據income屬性劃分三個分支的資訊熵:
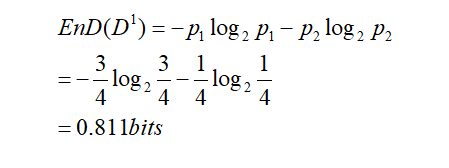
D2的資訊熵為:
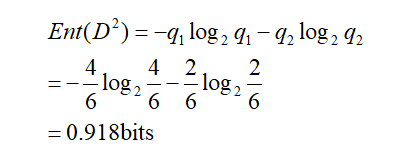
D3的資訊熵為:

於是 根據資訊增益公式,得出incomg屬性的資訊增益:

類似於同樣的原理,算出age、student、 credit_rating三個屬性的資訊增益,得Gain(age) =0.246 , Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,選擇age作為第一個根節點。
通過第一次劃分,得到下圖的結果

按照 同樣的原理,再算出各個屬性節點的資訊增益,對屬性節點再次劃分,劃分終點的依據是節點包含的樣本集都屬於一類。
以上就是ID3決策樹原理和例項演算的全過程。請讀者耐心去將例子演算完畢,得出最終的決策樹。
3 其他演算法: 在決策樹演算法中,ID3決策樹只是一種常用的演算法,還有更多的演算法
1、C4.5: Quinlan
2、Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)
著兩個演算法和ID3有共同點也有區別
共同點:都是貪心演算法,自上而下(Top-down approach)
區別:屬性選擇度量方法不同: C4.5 (gain ratio), CART(gini index), ID3 (Information Gain)
關於這兩個演算法,我再後續發表的文章會繼續講解,請繼續關注我的部落格。
4、決策樹的優缺點
決策樹的優點:
直觀,便於理解,小規模資料集有效
決策樹的缺點:
處理連續變數不好
類別較多時,錯誤增加的比較快
可規模性一般