
特徵點匹配——FREAK演算法介紹
FREAK演算法是ICCV 2012上的一篇關於特徵點檢測與匹配的論文《FREAK: Fast Retina Keypoint》上提出的,從文章標題中可以看出來該演算法的一個特點是快速,另外一個特點就是該演算法是被人眼識別物體的原理上得到啟發提出的。
看過我之前博文的可能知道,我到現在已經把SIFT演算法、ORB演算法、BRIEF演算法和BRISK演算法都進行了介紹。可以看出BRIEF、ORB和BRISK都是特徵點周圍的鄰域畫素點對之間的比較形成的二進位制串作為特徵點的描述符,這種做法有著快速和佔用記憶體低的優點,在如今的移動計算中有很大的優勢,但是也遺留了一些問題。比如,如何確定特徵點鄰域中哪些畫素點對進行比較,如何匹配它們呢?作者提出,這種優化的趨勢與自然界中通過簡單的規則解決複雜的問題是相符的。作者提出的FREAK演算法就是通過模仿人眼視覺系統而完成的,下面我們來介紹一下FREAK演算法。
一、特徵點檢測
特徵點檢測是特徵點匹配的第一個階段,FAST演算法是一種可以快速檢測特徵點的演算法,而且有AGAST演算法對FAST演算法的加速版本。本文中特徵點檢測方法與BRISK中特徵點檢測方法相同,都是建立多尺度的影象,在不同影象中分別使用FAST演算法檢測特徵點,具體的做法見我的博文特徵點檢測——BRISK演算法介紹,這裡就不在詳細的說明了。
二、二進位制串特徵描述符
既然FREAK演算法是通過人眼的視覺系統得到啟發提出的演算法,那麼我們首先來看看人眼的視覺系統。
2.1 Human retina
作者提出,在人眼的視網膜區域中,感受光線的細胞的密度是不相同的。人眼的視網膜根據感光細胞的密度分成了四個區域:foveola、fovea、parafoveal和perifoveal,如下圖所示:
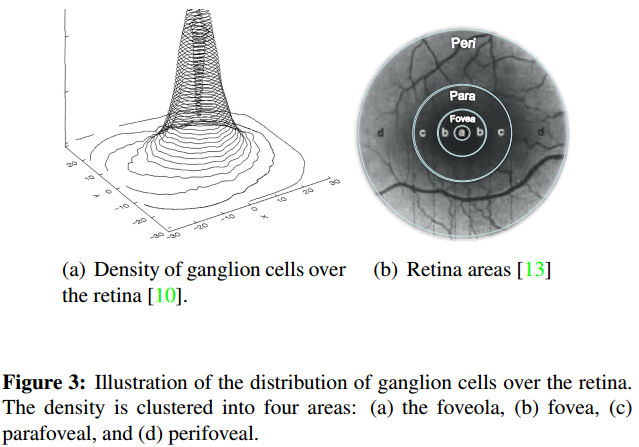
這裡面fovea區域是負責接收高解析度的影象,而低解析度的影象是perfoveal區域中形成的。
2.2 取樣模式
在我以前博文中提到的BRIEF、ORB演算法中特徵點鄰域中的取樣點對是隨機生成的,而BRISK演算法則是採用平均取樣的方式生成的這些取樣點。FREAK演算法中取樣模式與BRISK演算法中取樣模式類似,但是它的模式與人眼視覺系統中的模式更為接近,如下圖所示:
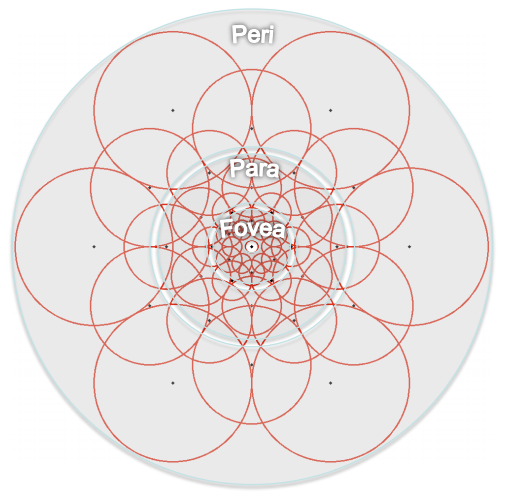
上圖中每一個黑點代表一個取樣點,每個圓圈代表一塊感受野,具體在處理時時對該部分影象進行高斯模糊處理,以降低噪聲的影響,而且每個圓圈的半徑表示了高斯模糊的標準差。這種取樣模式與BRISK演算法的不同之處在於,每個感受野與感受野之間有重疊的部分。與ORB和BRIEF演算法的不同之處在於,ORB和BRIEF演算法中的高斯模糊半徑都是相同的,而這裡採用了這種不同大小的高斯模糊的核函式。作者提出,正是這些不同之處,導致最後的結果更加優秀。通過重疊的感受野,可以獲得更多的資訊,這些資訊可以使最終的描述符更具有獨特性。而不同大小的感受野在人體的視網膜中也有這樣類似的結構。
最終FREAK演算法的取樣結構為6、6、6、6、6、6、6、1,這裡的6代表每層中有6個取樣點並且這6個取樣點在一個同心圓中,一共有7個同心圓,最後的1代表的是特徵點。
2.3 Coarse-to-fine descriptor
如上所述,FREAK演算法也是用二進位制串對特徵點進行描述,這裡用
由於一個特徵點中有數十個取樣點,那麼就有上千個候選的取樣點對,然後有些取樣點對對於特徵描述並沒有什麼用處,因此需要對特徵點對進行篩選,作者採用了一種與ORB演算法類似的演算法對特徵點對進行篩選:
(1)作者利用50000個特徵點建立了一個矩陣
(2)計算矩陣
(3)根據各列中的方差由大到小進行排序;
(4)取該矩陣的前
作者把得到的這512個取樣點對分成了4組,每128個為一組,把這些取樣點對進行連線,得到的效果如下:
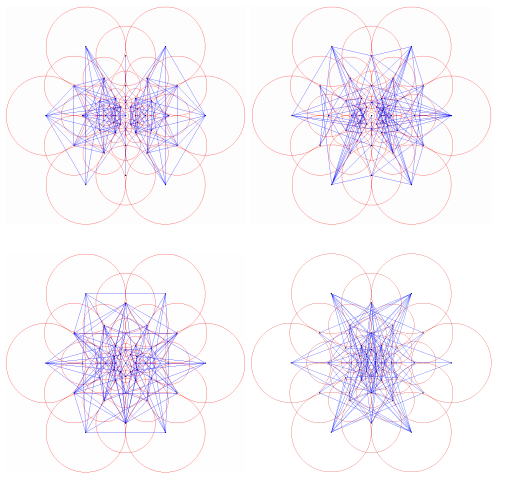
作者發現這四組的連線中第一組主要在外圍,之後的每一組連線逐漸內縮,最後一組的連線主要在中央部分,這與人眼視覺系統很相似。人眼視覺系統中也是首先通過perifoveal區域對感興趣的物體的位置進行估計,然後通過感光細胞更加密集的fovea區域進行驗證,最終確定物體的位置。
2.4 Saccadic search
人眼的fovea區域由於有比較密集的感光細胞,因此可以捕捉更加高解析度的影象,因此fovea區域在識別和匹配的過程中起著關鍵的作用。perifoveal區域的感光細胞則沒有那麼密集,因此它只能捕捉到模糊的影象,因此首先用他們來進行物體位置的估計。這就是人眼識別和匹配的大體流程,而作者就模仿這種流程對特徵點進行匹配。
首先使用前128個匹配點對,作為粗略資訊,如果距離小於某個閾值,再使用剩餘的匹配點對(精密資訊)進行匹配。這種級聯的操作在很大程度上加速了匹配的速度,大約有超過90%的候選點可以通過前128個匹配點對進行排除。這種級聯的操作的圖示如下圖所示:

2.5 Orientation
為了保證演算法具有方向不變性,需要為每個特徵點增加方向資訊,由於BRISK演算法與FREAK演算法對特徵點鄰域的取樣點格式相近,因此FREAK演算法特徵點方向的計算與BRISK演算法也比較相近。BRISK演算法是通過計算具有長距離的取樣點對的梯度來表示特徵點的方向(具體描述見我之前介紹BRISK演算法的博文),FREAK演算法則採用其中45個距離長的、對稱的取樣點計算其梯度,如下圖所示:
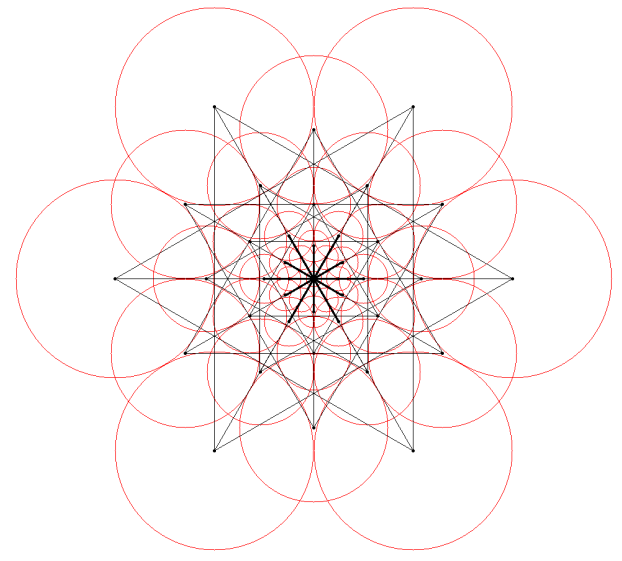
計算公式為
三、Opencv程式碼實現
下面是呼叫Opencv的FREAK演算法進行特徵點匹配的程式碼示例,使用了雙向驗證(即圖1中第i個點匹配圖2中第j個點,同時要求圖二中第j個點也要匹配圖1中的第i個點)以及RANSAN去除錯配點。
#include <iostream>
#include <opencv2\core\core.hpp>
#include <opencv2\highgui\highgui.hpp>
#include <opencv2\features2d\features2d.hpp>
#include <opencv2\legacy\legacy.hpp>
#include <time.h>
using namespace std;
using namespace cv;
void detectFREAK(Mat& img1, Mat& img2, vector<KeyPoint>& kp1,
vector<KeyPoint>& kp2, Mat& des1, Mat& des2)
{
//使用BRISK演算法中的特徵點檢測演算法檢測特徵點,存入kp1和kp2中
BRISK brisk(80,4); //40表示閾值,4表示有4個octave
brisk(img1, Mat(), kp1);
brisk(img2, Mat(), kp2);
//FREAK演算法,得到特徵點描述符,存入des1和des2中
FREAK freak;
freak.compute(img1, kp1, des1);
freak.compute(img2, kp2, des2);
}
void runRANSAC(vector<DMatch>& good_matches, const vector<KeyPoint>& kp1, const vector<KeyPoint>& kp2)
{
Mat image1Points(good_matches.size(), 2, CV_32F);//存放第一張影象的匹配點的座標
Mat image2Points(good_matches.size(), 2, CV_32F);
for (size_t i = 0; i < good_matches.size(); i++)
{
int sub_des1 = good_matches[i].queryIdx;
int sub_des2 = good_matches[i].trainIdx;
float *ptr1 = image1Points.ptr<float>(i);
float *ptr2 = image2Points.ptr<float>(i);
ptr1[0] = kp1[sub_des1].pt.x; ptr1[1] = kp1[sub_des1].pt.y;
ptr2[0] = kp2[sub_des2].pt.x; ptr2[1] = kp2[sub_des2].pt.y;
}
Mat fundamental;//基礎矩陣
vector<uchar> RANSAC_state;//RANSAC過濾後各匹配點對的狀態
//計算基礎矩陣,並記錄各個匹配點對的狀態,0為匹配不正確,1為正確
fundamental = cv::findFundamentalMat(image1Points, image2Points, RANSAC_state, cv::FM_RANSAC);
vector<DMatch>::iterator iter;
int i = 0;
for (iter = good_matches.begin(); iter != good_matches.end();)
{
if (RANSAC_state[i] == 0)
{
iter = good_matches.erase(iter);
}
else
iter++;
i++;
}
}
void matchFREAK(Mat& img1, Mat& img2, vector<KeyPoint>& kp1, vector<KeyPoint>& kp2,
Mat& des1, Mat& des2, string &str)
{
BruteForceMatcher<HammingLUT> matcher;
vector<DMatch> matches1to2;
vector<DMatch> matches2to1;
matcher.match(des1, des2, matches1to2);
matcher.match(des2, des1, matches2to1);
int* flag = new int[des2.rows];
for (int i = 0; i < des2.rows; i++)
{
flag[i] = matches2to1[i].trainIdx;
}
double max_dist = 0; double min_dist = 100;
for (int i = 0; i < des1.rows; i++)
{
double dist = matches1to2[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
cout << str << " " << max_dist << " " << min_dist << endl;
std::vector< DMatch > good_matches;
for (int i = 0; i < des1.rows; i++)
{
if (matches1to2[i].distance < max_dist)
{
if (matches2to1[matches1to2[i].trainIdx].trainIdx == i)
good_matches.push_back(matches1to2[i]);
}
}
for (size_t i = 0; i < kp1.size(); i++)
{
circle(img1, Point(kp1[i].pt.x, kp1[i].pt.y), 2, Scalar(0, 0, 255), 2);
}
for (size_t i = 0; i < kp2.size(); i++)
{
circle(img2, Point(kp2[i].pt.x, kp2[i].pt.y), 2, Scalar(0, 0, 255), 2);
}
runRANSAC(good_matches, kp1, kp2);
Mat img_matches;
drawMatches(img1, kp1, img2, kp2,
good_matches, img_matches, Scalar(0, 255, 0), Scalar(0, 0, 255),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
imwrite(str, img_matches);
}
int main()
{
Mat img1 = imread("1.jpg");
Mat img2 = imread("2.jpg");
vector<KeyPoint> kp1, kp2;
Mat des1, des2;
detectFREAK(img1, img2, kp1, kp2, des1, des2);
matchFREAK(img1, img2, kp1, kp2, des1, des2, string("matchImage.jpg"));
return 0;
}FREAK匹配的結果並不好,結果如下圖所示:
