
餘額支付風控 -- 風控評分模型篇
餘額支付風控
風控評分模型篇
by dylanfan at 2015-2-11
一 概述
餘額支付的風險識別模型分為兩類:(1)盜號交易識別風險 和 (2)盜卡交易識別風險。其中盜卡交易識別風險和餘額有關主要是由於騙子註冊號碼幫盜來的卡,然後進行充值到餘額,通過餘額支付銷贓。(1)和(2)兩種針對的情景不一樣,採用的特徵變數和變數的重要性很大程度是不一樣的。針對(1)的問題,主要是看當前交易相對使用者之前的行為是否存在異常。針對(2)的問題,主要看使用者資訊和綁卡的資訊匹配的一致性,可信性,以及當前賬號的可信度。
在整體篇,提到風險識別領域採用的常規的方法是專家規則系列和模型系列。規則體系中每個規則針更多對單一風險場景和問題來制定的,偏重精準性和稍微兼顧覆蓋率。模型系列更加覆蓋率,模型不斷學習來增加識別各種風險場景的能力。模型的一個好處就是可以不斷學習,對各種風險場景可以有個統一的量化評估,比如0-100
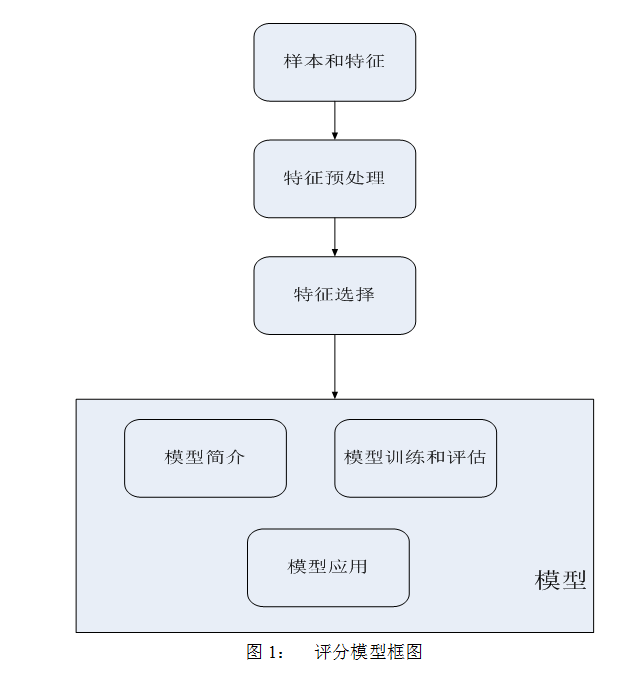
二 樣本和特徵
風險評分模型可以看成一個二分類問題,就是設計個模型能把好的交易樣本和壞的交易樣本儘可能區分出來。做風險評分模型這個專案前,先得積累足夠多的資料(樣本和特徵),不然真是巧婦難為無米之炊。所以,系統需要有套收集資料的機制,尤其是壞樣本的資料收集機制。對於交易而言,可以以訂單號來標記一條樣本,樣本由多個特徵變數組成,這些特徵變數基本可以包含交易維度的變數,交易雙方的特徵變數等。首先,系統需記錄整體交易這些相關的資料。然後,通過人工標記壞樣本的方式來記錄壞樣本訂單號,在支付領域壞樣本人工標記方式可以通過使用者報損反饋,也可以是人工通過相關黑資訊關聯找出來的標記樣本。系統設計是儘可能多的和並且儘可能精準的的收集到壞樣本。對於好樣本,如果樣本特徵變數中不包含某些週期性變數,可以負取樣過去幾天的交易樣本,最好有距離目前時間一週以上的時間間隔,方便使用者反饋,從裡面剔除壞樣本和某些設定規則下的過濾的樣本(存在異常樣本和沒有報損的樣本)。
在風控建模領域,一個典型的問題就是樣本有偏。舉個例子說明:假如你發現騙子符合某些聚集特徵,你指定策略1進行打擊後,騙子的這種欺詐手段被控制,以後的損失案例都不具備這樣的聚集特徵。如果你的壞樣本的收集時間在策略1上線之後,這個時候模型訓練的結果極有可能出現滿足聚集特徵的風險低,不滿足聚集特徵的交易反而風險高,也就是說聚集特徵的權重是負數。這時候模型的解釋性出了問題,這個也是模型訓練中一個過擬合問題的範疇。為了有效解決這個問題,可以根據業務經驗來檢視模型中變數的權重是否與經驗相悖,如果相悖,需要仔細評估。對於是樣本有偏帶來的問題,可以通過重新加入符合某些條件的樣本來彌補。對於這些彌補的樣本獲取方法一種可以從攔截樣本中選擇,一個可以根據經驗來人工生成樣本。
談談模型的不平衡學習。風控模型學習是個典型的不平衡學習問題,他同時具備不平衡學習領域兩個問題:(1)正負樣本比率懸殊,但是正負類樣本都足夠多;(2)正樣本樣本個數也很稀少。第一個問題是基本滿足樣本在特徵空間的覆蓋情況,只是比率較大導致某些學習模型應用會出現問題。第二個問題是樣本太少,導致樣本在特徵空間的覆蓋很小,極容易過擬合,不能覆蓋特徵空間和對欺詐場景的覆蓋。對於第二個問題,最好的方法還是先收集樣本+一些不平衡學習方法。對於正負樣本的比率問題,有的用1:1,有的人用1:10,有的說是1:13.這些大多都是經驗。我一般用,其實也是經驗,1:10。其實,對於比率這個問題,說到底就是負樣本該取樣多少的問題。我覺得只要保證負樣本也儘可能多滿足覆蓋特徵空間就好,因為很多負樣本(好的交易樣本)模式都是很相似的,對於相似的模式不用保留太多的樣本。但是本來正樣本就少,如果負樣本和正樣本一樣多,我個人認為隨機取樣的負樣本覆蓋的特徵空間會很小,所以,我個人不是很贊同1:1的比率。具體可以參考我的這篇部落格:http://blog.csdn.net/hero_fantao/article/details/35784773
三 特徵預處理
特徵大體可以分為連續特徵變數和類目特徵變數。特徵預處理主要會圍繞這兩類特徵來進行的。主要分為缺失值填充,異常值處理,連續特徵歸一化處理,連續特徵離散化處理。
3.1 缺失值填充
特徵的缺失值填充前,我們需要先統計特徵的缺失值比率。採用某個特徵來區別正常交易和異常交易前,這個特徵的缺失值比率不能超過一定的閾值。對於缺失值填充的常用方法有:均值,中值,0值等。
3.2 異常值處理
可能由於某些原因,導致系統在收集樣本時候,出現錯誤,特徵值過大或者過小。當然,這個可能本來資料就是這樣,但是,我們也需要做個處理。常用的方法:設定分位點做截斷,比如0.1%,99.9%分位點等。
3.3 連續特徵歸一化處理
對於連續特徵,比如使用者的註冊時間間隔,原來的值範圍各自不同,不在統一的尺度。有的連續特徵值範圍大,有的連續特徵值範圍小。如果不做歸一化處理,連續特徵中值範圍的大的特徵會淹沒值範圍小的連續特徵對模型的影響。所以,有必要對連續特徵做歸一化處理。
常用的連續特徵歸一化處理方法:(1)min-max方法; (2)z-score方法。
對於網際網路資料,很多特徵呈現長尾power-law分佈,所以,大多場景針對這種情況在做min-max 或者z-score之前,會對連續特徵先做log(x)變換。
3.4 連續特徵離散化處理
相對連續特徵歸一化處理,還可以對連續特徵進行離散化處理。在logistic regression中,大家經常會把連續特徵做離散化處理,好處:(1)是避免特徵因為和目標值非線性關係帶來的影響;(2)離散化也是種給lr線性模型帶來非線性的一種方法;(3)方便引入交叉特徵;(4)工程實現上的trick。
常見的離散化處理手法:非監督的方法和監督的方法。非監督的方法:等寬,等頻,經驗,分佈圖劃分等。監督方法:基於資訊增益或卡方檢驗的區間分裂演算法和基於資訊增益或卡方檢驗的區間合併演算法等。我個人常用的監督的方法是合併演算法,其中具體的介紹可以參考我的這篇部落格:http://blog.csdn.net/hero_fantao/article/details/34533533
在風控採用lr模型的時候,對於連續特徵採用離散化處理會有個這樣的問題:因為我們的壞樣本是針對過去的欺詐場景的,欺詐手法在長期博弈中不斷升級。我們不僅要讓模型儘可能多的覆蓋過去的欺詐手法,對未來產生欺詐對抗有一定的適應性,不至於失效太快。採用離散化處理後,就可能出現很大的跳變性。假設我們過去的的壞樣本都是剛註冊不久的使用者,那註冊時間間隔做離散化處理時候,就可能分為A,B兩段,離散化處理後可以看成0-1二值變數,落在A段為1,否則為0。 為1時候風險高,權重為正值。如果這個變數在過去對正負樣本區分度很高,可以看成核心變數的話,那如果騙子繞過A段,跳到B段的話,對模型的預測能力衰弱會是致命的。
四 特徵選擇
模型訓練前必不可少的一項工作就是特徵選擇,包括特徵重要性和決定最終哪些特徵會進入模型。對於一個領域專家來說,看你採用的特徵集合和以及特徵的重要性分佈基本就能看出你模型大體會對那些場景預測的準,哪些場景你是預測不出來的。在風控領域就相當於特徵集合決定你能覆蓋哪些欺詐場景,會對哪些場景的正常交易進行了誤判。對於一個風控領域新人來說,最快的進入領域就是看目前風控系統模型採用了哪些特徵集合以及特徵的重要程度。
談談在模型訓練前做特徵選擇的幾個好處:(1)去除冗餘,不相關特徵;(2)減少維度災難;(3)節省工程空間成本。常用的方法:(1)資訊值:information value,簡稱IV值;IV值越大,重要程度越高。(2)資訊增益: information gain; 是採用資訊熵的方法,資訊增益表示資訊熵的變化, 增益越大,說明特徵區分度越明顯。(3)前向後向選擇,依賴模型,通過AIC或者BIC來選擇最優特徵集合。
五 模型
5.1 模型簡介
這裡採用的模型是logistic regression ,簡稱LR模型。選擇這個模型的理由:(1)簡單,可解釋性強;(2)線上實施響應時間快,風控有線上實時響應時間限制,所以在特徵變數使用和模型複雜度上都有要求。
特徵變數方面:基於歷史的變數需要提前計算好,呼叫外部介面所需要的變數要麼在支付環節之前某個環節預獲取或者採用非同步方式(非同步方式會影響當前判斷的準確性)。
模型方面:最好選擇簡單和泛化能力強的模型,複雜或者ensemble model在離線實驗也許表現好,但是在線上未必好,複雜模型尤其是GBDT這種ensemble模型在風控資料下容易過擬合(風控資料小)。從我在風控應用模型的經驗來看,目前階段還不是拼模型的階段,更多是找到風險特徵。模型對惡意行為識別不好,更多可能是惡意特徵沒覆蓋或者突破了當前模型的幾個核心變數。
下圖是LR模型的簡介:

這是個預測函式,訓練樣本就是為了求解這個w。這裡面涉及損失函式設計問題和最優值求解問題。常用的損失函式是logloss:

模型中採用正則化是為了避免過擬合,我覺得風控建模上一個重要問題就是過擬合,避免幾個核心變數的權重過大。常用的最優求解方法有如下幾種:(1)batch 梯度下降法;(2)L-BFGS。具體細節可以參考:
5.2 模型訓練和評估
訓練: 劃分資料集為訓練集和測試集: 採用 k-fold cross-validation 交叉驗證。K可取5或者10等。選擇模型,如Logistic Regression 模型,調節引數,對訓練集進行訓練,直至模型收斂,然後對測試集進行預測。可以用k-fold的平均結果作為整體預測結果來衡量模型。
評估指標: AUC,準確率和召回率, F1-score等。
下圖是ROC曲線和風險評分預測分值的累積分佈:

這裡面再提一點:就是上面這些評估指標即使表現良好,但是也未必說明模型應用沒什麼問題。常見的一點:特徵的相關性影響(特徵相關性對模型抗噪性有影響)。對於強相關的特徵需要做下處理,能整合成一個變數最好。特徵相關性在模型結果的表現上可能會出現特徵的權重正負方向和大家認知相反,比如某個高風險特徵和預測結果應該呈現正相關,但是模型結果顯示卻呈現負相關。這個大多由於另外一個更強特徵和該特徵呈現相關性造成的。相關性導致的這些問題,會讓模型的解釋性出現問題。在風控領域,模型解釋性很重要。
5.3 風險評分的應用
計算線上不同分值段交易量大小,最好能給出不同分值段惡意交易比率。可以根據不同業務場景設定不同分數閾值,即使同一場景也可以根據不同分數閾值來進行不同的懲罰手段,分數很高的時候可以進行凍結賬號等。值得一提的是,交易行為中有一定數量的高危行為,但是這些高危行為未必都是欺詐行為,異常不代表欺詐。很多正常的人某些行為和欺詐很相似,同樣欺詐者隨著博弈對抗加劇,也越來越偽裝成正常交易。在風控,有時候為了增加對欺詐行為的覆蓋,犧牲一小部分使用者支付體驗,也是值得的。我認為,風控一個重要的工作就是在風險和支付體驗上獲取平衡,如果支付體驗不好,風險控制再好,也是沒有意義的。
風險評分應用一個重要的方面:對交易評分實時查詢,相應變數值展示,以及重要變數觸犯展示等一些列解釋行為。這塊叫做告訴別人為什麼你風險高或者為什麼風險低。