
深度學習之視訊人臉識別系列三:人臉表徵
作者 | 東田應子
本文是深度學習之視訊人臉識別系列的第三篇文章,介紹人臉表徵相關演算法和論文綜述。在本系列第一篇文章裡我們介紹了人臉識別領域的一些基本概念,分析了深度學習在人臉識別的基本流程,並總結了近年來科研領域的研究進展,最後分析了靜態資料與視訊動態資料在人臉識別技術上的差異;在第二篇文章中介紹了人臉檢測與對齊的相關演算法。
一、人臉表徵
把人臉影象通過神經網路,得到一個特定維數的特徵向量,該向量可以很好地表徵人臉資料,使得不同人臉的兩個特徵向量距離儘可能大,同一張人臉的兩個特徵向量儘可能小,這樣就可以通過特徵向量來進行人臉識別。

二、論文綜述
1. DeepFace
2014年論文DeepFace: Closing the Gap toHuman-Level Performance in Face Verification提出了DeepFace演算法,第一個真正將大資料和深度學習神經網路結合應用於人臉識別與驗證。在該人臉識別模型中分為四個階段:人臉檢測 => 人臉對齊 => 人臉表徵 => 人臉分類,在LFW資料集中可以達到97.00%的準確率。
(1)人臉檢測與對齊:該模型使用3D模型來將人臉對齊,該方法過於繁瑣,在實際應用中很少使用,經過3D對齊以後,形成的影象都是152×152的影象,具體步驟如下圖。
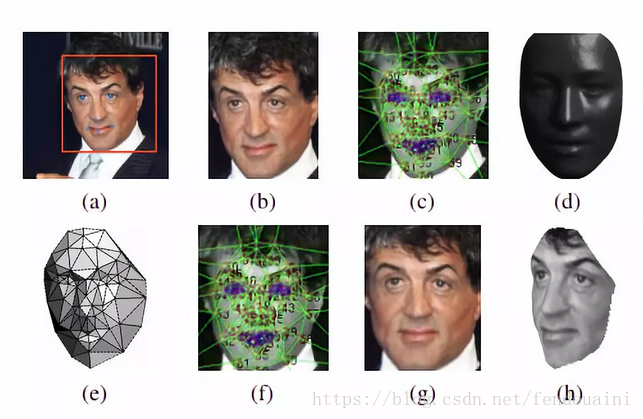
分為如下幾步:
a. 人臉檢測,使用6個基點
b. 二維剪下,將人臉部分裁剪出來
c. 67個基點,然後Delaunay三角化,在輪廓處新增三角形來避免不連續
d. 將三角化後的人臉轉換成3D形狀
e. 三角化後的人臉變為有深度的3D三角網
f. 將三角網做偏轉,使人臉的正面朝前。
g. 最後放正的人臉
h. 一個新角度的人臉(在論文中沒有用到)
(2)人臉表徵:人臉表徵使用了5個卷積層和1個最大池化層、1個全連線層,如下圖所示。前三層的目的在於提取低層次的特徵,為了網路保留更多影象資訊只使用了一層池化層;後面三層都是使用引數不共享的卷積核,因為主要是因為人臉不同的區域的特徵是不一樣的,具有很大的區分性,比如鼻子和眼睛所表示的特徵是不一樣的,但是使用引數不共享的卷積核也增加了模型計算量以及需要更多的訓練資料。最後輸出的4096維向量進行L2歸一化。

a. Conv:32個11×11×3的卷積核
b. max-pooling: 3×3, stride=2
c. Conv: 16個9×9的卷積核
d. Local-Conv: 16個9×9的卷積核,Local的意思是卷積核的引數不共享
e. Local-Conv: 16個7×7的卷積核,引數不共享
f. Local-Conv: 16個5×5的卷積核,引數不共享
g. Fully-connected: 4096維
h. Softmax: 4030維
(3)分類:論文介紹了兩種方法進行分類,加權的卡方距離和使用Siamese網路結構,設f1和f2為特徵向量,上一個步驟的輸出,則有:
①加權卡方距離:計算公式如下,加權引數由線性SVM計算得到:
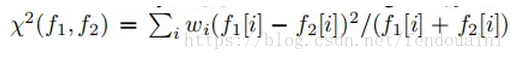
②Siamese網路:網路結構是成對進行訓練,得到的特徵表示再使用如下公式進行計算距離:
2. DeepID1:
DeepID1 是2014年Deep LearningFace Representation from Predicting 10,000 Classes一文提出的,是DeepID三部曲的第一篇。DeepID1 使用softmax多分類訓練,主要思想第一個是資料集的增大,包括訓練集使用celebface,包含87628張圖片,5436個人臉,增大了訓練集;使用多尺寸輸入,通過5個landmarks將每張人臉劃分成10regions,每張圖片提取60patches=10regions*3scales*2(RGB orgray),第二個是網路結構,DeepID提取的人臉特徵就是一個由連線第三層與第四層組成的全連線層特徵,如下圖所示,每個patches經過這個cnn網路,第四層的特徵更加全域性化(global),第三層的特徵更加細節,因此DeepID連線了兩者,以求同時包含全域性,細節資訊。
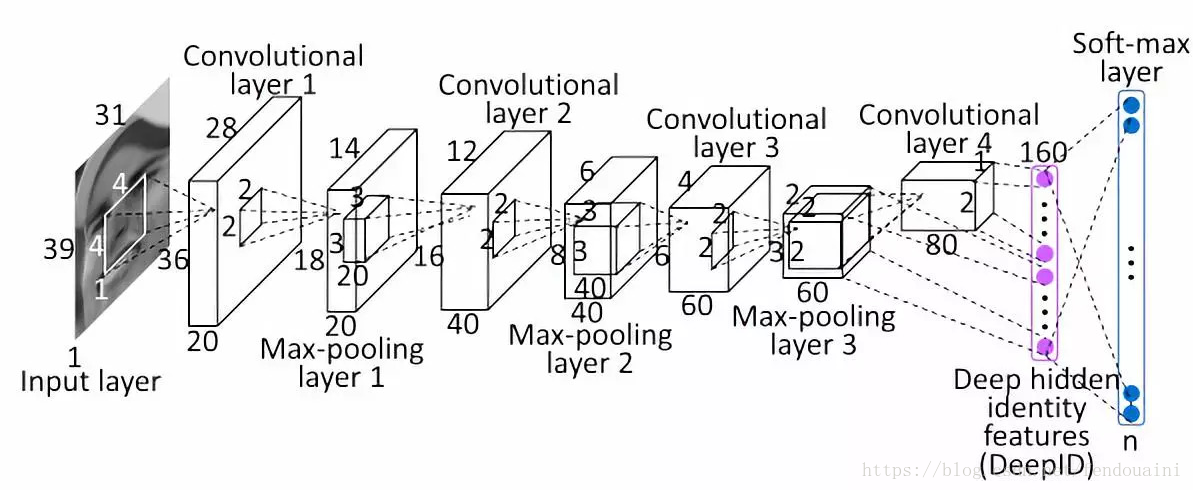
60個patches使用60個CNN,每個CNN提取2*160=320維特徵(與水平翻轉一起輸入),總網路模型如下圖所示,最後分別使用聯合貝葉斯演算法與神經網路進行分類,並比較結果。
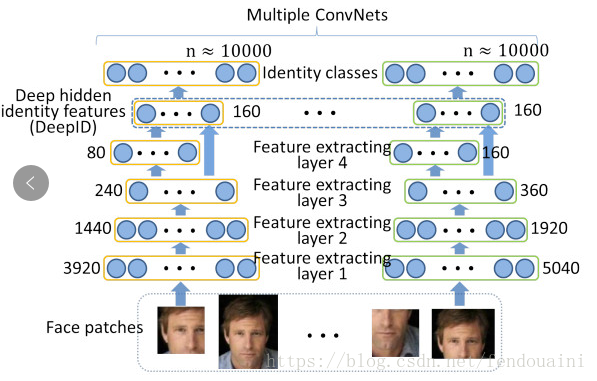
模型最終以CelebFaces+中202,599影象作為訓練集, patch數提升為100(10r*10s*2) ,特徵數提升為100*160*2=32000 然後使用PCA降為150維 ,使用聯合貝葉斯演算法進行驗證, 最終在LFW上達到97.20%的驗證準確率。
3. DeepID2:
DeepID2是Deep Learning Face Representationby Joint Identification-Verification一文提出的,對DeepID1進行了進一步的改進,提出了contrastive loss,在分類任務,我們需要的是減少類內差距(同一人臉),增加類間差距(不同人臉),softmax loss分類的監督訊號可以增大類間差距,但是卻對類內差距影響不大,所以DeepID2加入了另一個loss,contrastive loss,從而增加驗證的監督訊號,就可以減少類內差距。
網路結構類似DeepID1,不同之處在於使用了兩種不同的損失函式,網路結構如下圖所示。
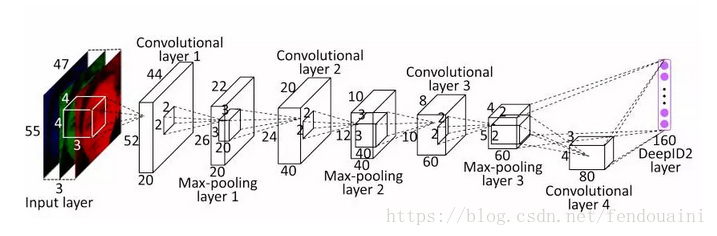
損失函式:
①分類訊號,Softmax loss。
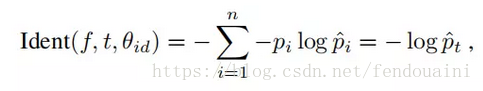
②驗證訊號,contrastiveloss,使用l2範數距離表示,m為閾值不參與訓練,括號內的θve={m},該損失函式可以讓類間的距離給定一個限制margin,即m大小的距離。
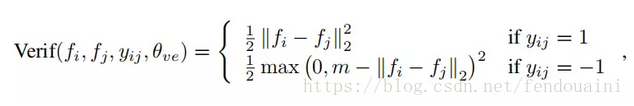
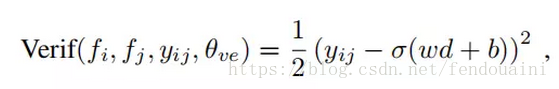
兩loss的組合方式: 首先使用2個輸入,計算Softmax loss和contrastive loss,總損失為二者通過λ加權求和,通過總損失來執行梯度下降更新卷積引數,通過Softmax loss來更新softmax層的引數。
整個模型使用celebrate+資料集訓練,每張圖片使用了21 facial landmarks,分成200patches(20regions*5scales*2RGB&Gray),水平翻轉後變為400patches,使用了200個卷積神經網路,提取400(200*2)個Deepid2特徵,使用貪婪演算法降為25個Deepid2特徵,使用PCA將25*160Deepid2特徵降為180維,最後使用聯合貝葉斯演算法進行驗證,最終在LFW上得到的最終準確率是98.97%,使用7組25個Deepid2特徵,SVM融合可得到準確率為99.15% 。DeepID2在2014 年是人臉領域非常有影響力的工作,也掀起了在人臉領域引進 MetricLearning 的浪潮。
4. DeepID2+:
DeepID2+源於論文Deeply learned facerepresentations are sparse, selective, and robust,DeepID2+是對DeepID2的改進。①卷積層在原來基礎上再增加128維,第四層全連線層從160增加到512,訓練資料增加了CelebFaces+ dataset,WDRef等,有12000個人臉的大約290,000張圖片; ②每個卷積層的後面都加了一個512為的全連線層,並新增contrastive loss監督訊號,而不僅在第四層全連線層上有 。網路結構如下圖所示。
最終在LFW資料集上準確率為99.47%。
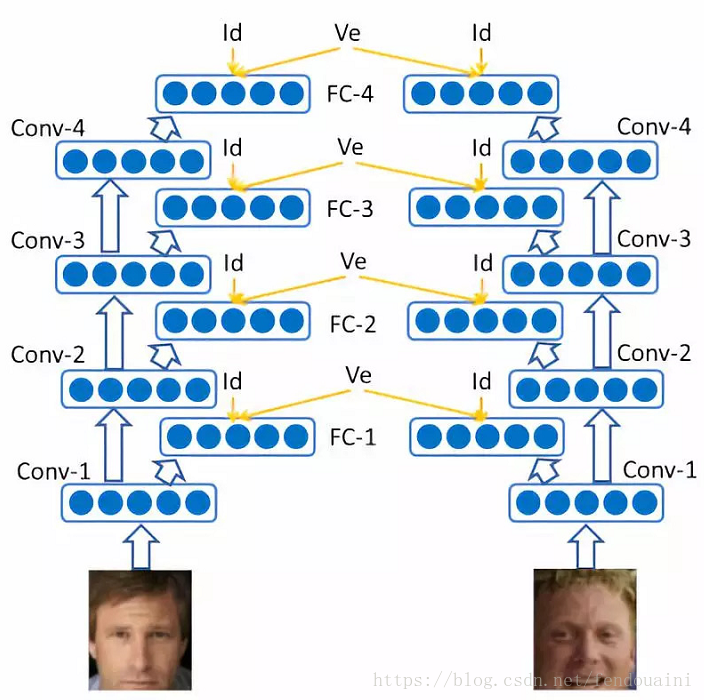
5. DeepID3:
DeepID3源於2015年的Deepid3:Face recognition with very deep neural networks論文,該論文探究了複雜神經網路對人臉識別的作用。論文研究VGG與GoogleNet用於人臉識別的效果,論文在VGG和GooLeNet的基礎上進行構建合適的結構,使得方便人臉識別。結果發現DeepID3的結果和DeepID2+相當,可能是由於資料集的瓶頸,需要更大的資料才能有更好的提升,兩個網路結構如下圖所示。
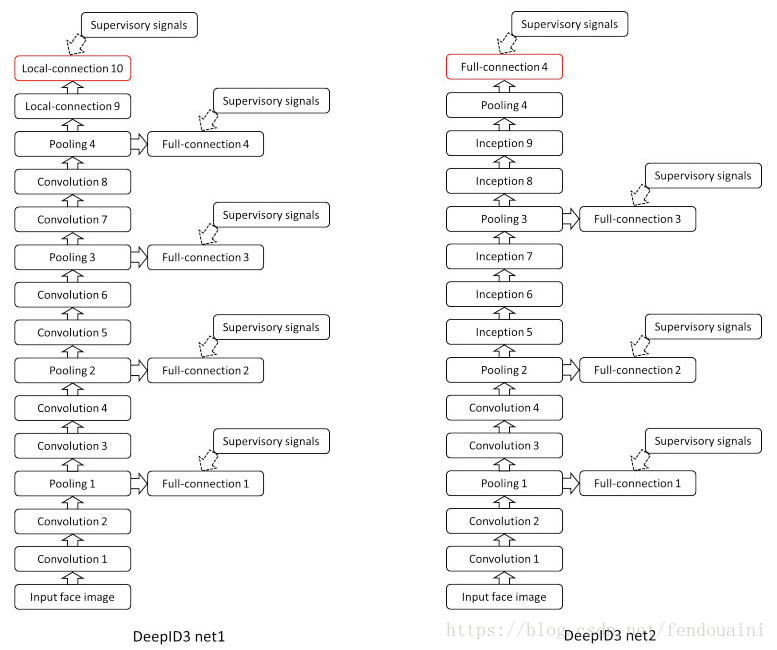
網路輸出使用PCA降維到300維的向量,使用聯合貝葉斯演算法進行驗證,最終在LFW上得到的最終準確率是99.53%。
6. FaceNet:
FaceNet由論文Facenet: A unified embedding forface recognition and clustering提出,這篇 2015 年來自 Google 的 論文同樣具有非常大的影響力,不僅僅成功應用了 TripletLoss 在 benchmark 上取得state-of-art 的結果,更因為他們提出了一個絕大部分人臉問題的統一解決框架,即:識別、驗證、搜尋等問題都可以放到特徵空間裡做,需要專注解決的僅僅是如何將人臉更好的對映到特徵空間。FaceNet在DeepID的基礎上,將 ContrastiveLoss 改進為 Triplet Loss,去掉softmaxloss。FaceNet實驗了ZFNet型別網路和Inception型別網路,最終Inception型別網路效果更好,網路結構如下圖所示。
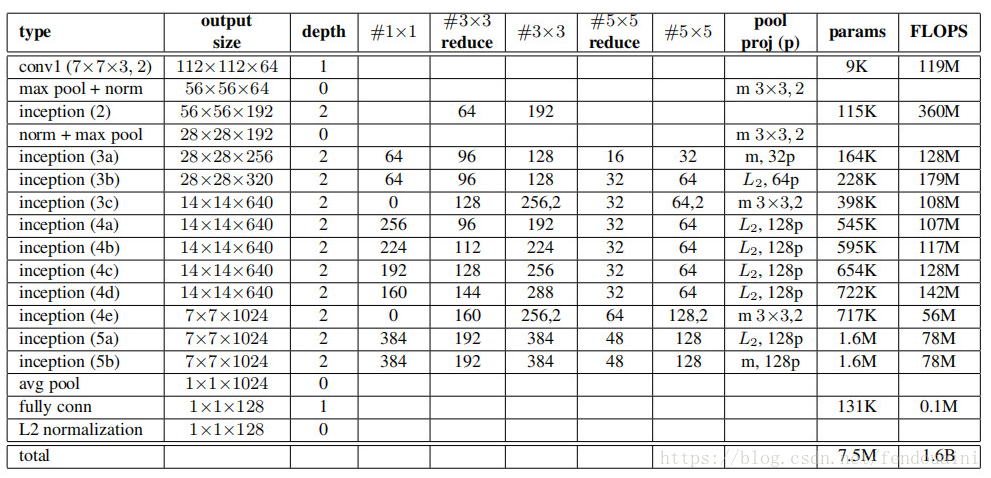
FaceNet沒有使用PCA降維,而是在網路中直接訓練輸出128維的向量,用全連線層來完成降維,最後的128維的向量經過Triplet Loss。
Triplet Loss輸入不再是 Image Pair,而是三張圖片(Triplet),分別為 Anchor Face(xa),Negative Face(xn)和 Positive Face(xp)。Anchor 與 Positive Face 為同一人,與 Negative Face 為不同人,在特徵空間裡 Anchor 與 Positive 的距離要小於 Anchor 與 Negative 的距離,且相差超過一個 Margin Alpha。
loss的目標為:
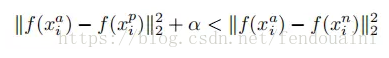
總loss公式為:
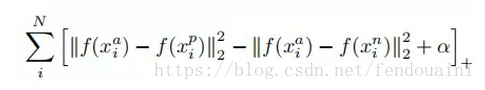
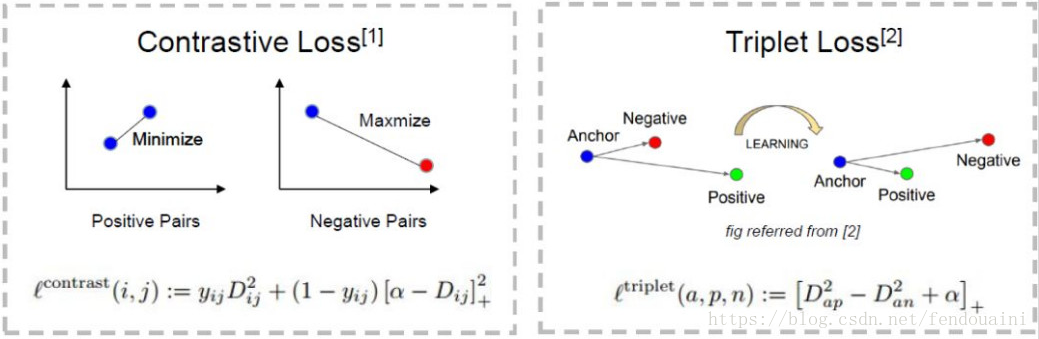
Contrastive Loss與Triplet Loss的比較, Contrastive Loss目標是減少類內差距(兩個藍點),增加類間差距(藍點與紅點);Triplet Loss則是輸入三張圖片,Anchor 與 Positive 的距離要小於 Anchor 與 Negative 的距離,且相差超過一個 Margin Alpha,即Triplet Loss同時約束了兩個距離。
最後FaceNet在LFW資料集上達到了99.63%的準確率。
基於 ContrastiveLoss 和 Triplet Loss 的 MetricLearning 符合人的認知規律,在實際應用中也取得了不錯的效果,但同時也有很多問題,由於ContrastiveLoss 和 Triplet Loss 的訓練樣本都基於pair 或者 triplet 的,可能的樣本數是 O(N2) 或者 O (N3) 的,所以模型需要很久的計算才能擬合併且訓練集需要足夠大。
三、總結
本期文章主要介紹人臉表徵相關演算法和論文綜述,主要是2014年到2016年的研究成果, ContrastiveLoss 和 Triplet Loss在實際應用中也取得了很好的效果,但是也有很多問題,由於Contrastive Loss 和 Triplet Loss 的訓練樣本都基於 pair 或者 triplet 的,可能的樣本數是 O (N2) 或者 O (N3) 的,所以模型需要很久的計算才能擬合併且訓練集要足夠大,所以在之後的人臉識別研究中,大部分在於loss函式的研究,這部分將會在下一期給大家介紹。
參考文獻:
【1】 Taigman Y, Yang M, Ranzato M A, et al.Deepface: Closing the gap to human-level performance in faceverification[C]//Proceedings of the IEEE conference on computer vision andpattern recognition. 2014: 1701-1708.
【2】Sun Y, Wang X, Tang X. Deep learning facerepresentation from predicting 10,000 classes[C]//Proceedings of the IEEEconference on computer vision and pattern recognition. 2014: 1891-1898.
【3】Sun Y, Chen Y, Wang X, et al. Deeplearning face representation by joint identification-verification[C]//Advancesin neural information processing systems. 2014: 1988-1996.
【4】Sun Y, Liang D, Wang X, et al. Deepid3:Face recognition with very deep neural networks[J]. arXiv preprintarXiv:1502.00873, 2015.
【5】Simonyan K, Zisserman A. Very deepconvolutional networks for large-scale image recognition[J]. arXiv preprintarXiv:1409.1556, 2014.
【6】Szegedy C, Liu W, Jia Y, et al. Goingdeeper with convolutions[C]//Proceedings of the IEEE conference on computervision and pattern recognition. 2015: 1-9.
【7】Sun Y, Wang X, Tang X. Deeply learned facerepresentations are sparse, selective, and robust[C]//Proceedings of the IEEEconference on computer vision and pattern recognition. 2015: 2892-2900.
【8】Schroff F, Kalenichenko D, Philbin J.Facenet: A unified embedding for face recognition andclustering[C]//Proceedings of the IEEE conference on computer vision andpattern recognition. 2015: 815-823.