
真正的完全圖解Seq2Seq Attention模型
作者:盛源車
知乎專欄:魔法抓的學習筆記
五分鐘看懂seq2seq attention模型。
本文通過圖片,詳細地畫出了seq2seq+attention模型的全部流程,幫助小夥伴們無痛理解機器翻譯等任務的重要模型。
seq2seq 是一個Encoder–Decoder 結構的網路,它的輸入是一個序列,輸出也是一個序列, Encoder 中將一個可變長度的訊號序列變為固定長度的向量表達,Decoder 將這個固定長度的向量變成可變長度的目標的訊號序列。--簡書
好了別管了,接下來開始刷圖吧。
大框架
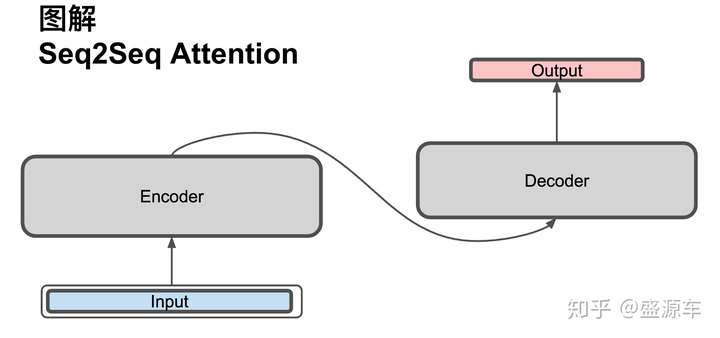
想象一下翻譯任務,input是一段英文,output是一段中文。
公式(直接跳過看圖最佳)
輸入:
輸出:
(1) , Encoder方面接受的是每一個單詞word embedding,和上一個時間點的hidden state。輸出的是這個時間點的hidden state。
(2) , Decoder方面接受的是目標句子裡單詞的word embedding,和上一個時間點的hidden state。
(3) , context vector是一個對於encoder輸出的hidden states的一個加權平均。
(4) , 每一個encoder的hidden states對應的權重。
(5) , 通過decoder的hidden states加上encoder的hidden states來計算一個分數,用於計算權重(4)
(6) , 將context vector 和 decoder的hidden states 串起來。
(7) ,計算最後的輸出概率。
詳細圖
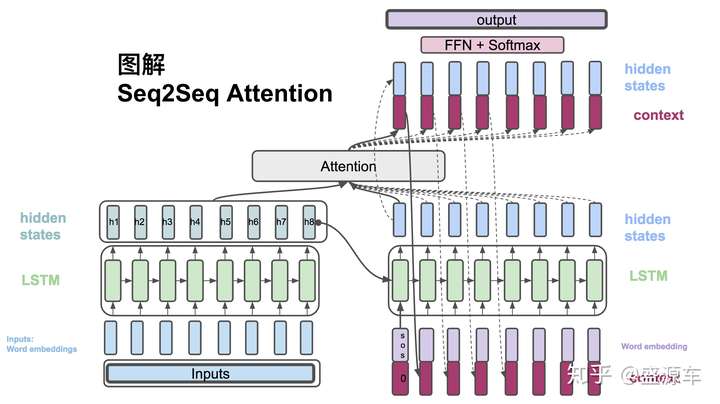
左側為Encoder+輸入,右側為Decoder+輸出。中間為Attention。
(1) , Encoder方面接受的是每一個單詞word embedding,和上一個時間點的hidden state。輸出的是這個時間點的hidden state。
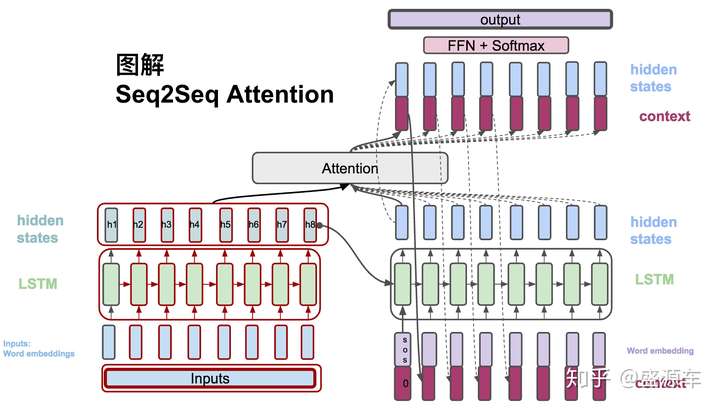
從左邊Encoder開始,輸入轉換為word embedding, 進入LSTM。LSTM會在每一個時間點上輸出hidden states。如圖中的h1,h2,...,h8。
(2) , Decoder方面接受的是目標句子裡單詞的word embedding,和上一個時間點的hidden state。

接下來進入右側Decoder,輸入為(1) 句首 <sos>符號,原始context vector(為0),以及從encoder最後一個hidden state: h8。LSTM的是輸出是一個hidden state。(當然還有cell state,這裡沒用到,不提。)
(3) , context vector是一個對於encoder輸出的hidden states的一個加權平均。
(4) , 每一個encoder的hidden states對應的權重。
(5) , 通過decoder的hidden states加上encoder的hidden states來計算一個分數,用於計算權重(4)
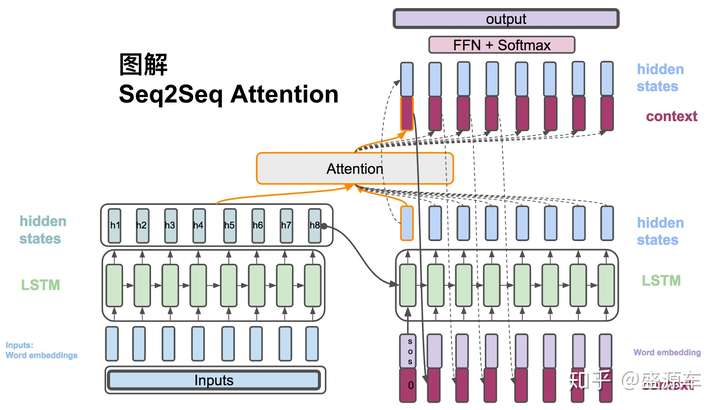
Decoder的hidden state與Encoder所有的hidden states作為輸入,放入Attention模組開始計算一個context vector。之後會介紹attention的計算方法。
下一個時間點
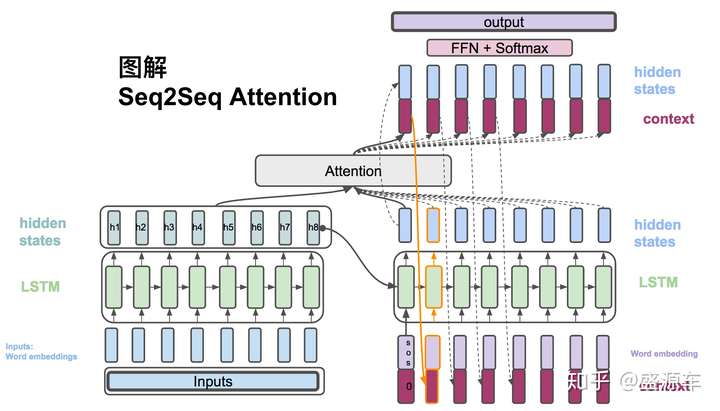
來到時間點2,之前的context vector可以作為輸入和目標的單詞串起來作為lstm的輸入。之後又回到一個hiddn state。以此迴圈。
(6) , 將context vector 和 decoder的hidden states 串起來。
(7) ,計算最後的輸出概率。
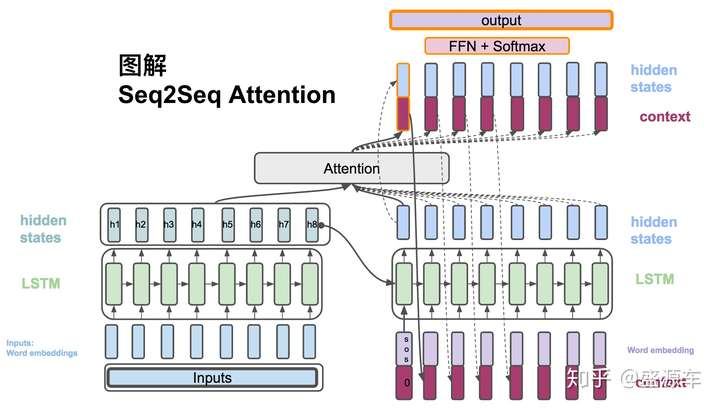
另一方面,context vector和decoder的hidden state合起來通過一系列非線性轉換以及softmax最後計算出概率。
在luong中提到了三種score的計算方法。這裡圖解前兩種:
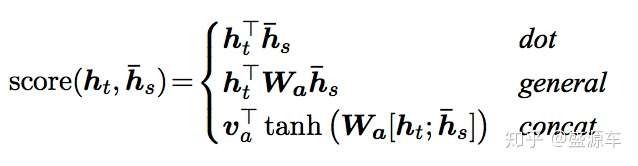
Attention score function: dot
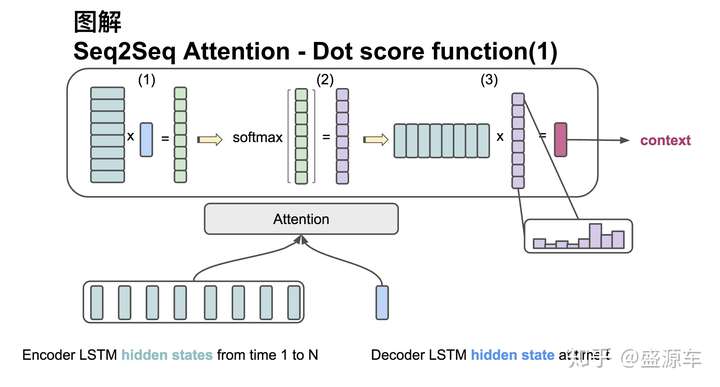
輸入是encoder的所有hidden states H: 大小為(hid dim, sequence length)。decoder在一個時間點上的hidden state, s: 大小為(hid dim, 1)。
第一步:旋轉H為(sequence length, hid dim) 與s做點乘得到一個 大小為(sequence length, 1)的分數。
第二步:對分數做softmax得到一個合為1的權重。
第三步:將H與第二步得到的權重做點乘得到一個大小為(hid dim, 1)的context vector。
Attention score function: general
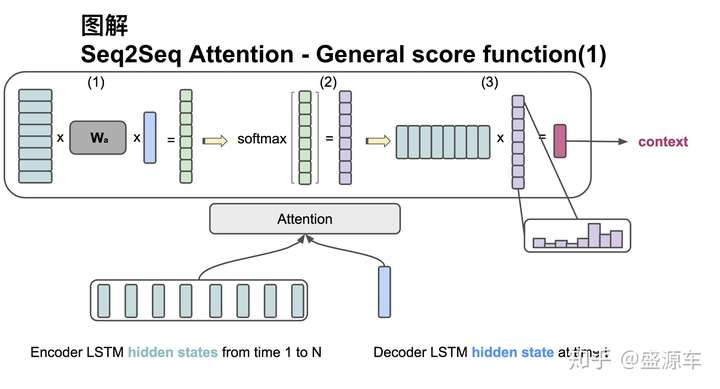
輸入是encoder的所有hidden states H: 大小為(hid dim1, sequence length)。decoder在一個時間點上的hidden state, s: 大小為(hid dim2, 1)。此處兩個hidden state的緯度並不一樣。
第一步:旋轉H為(sequence length, hid dim1) 與 Wa [大小為 hid dim1, hid dim 2)] 做點乘, 再和s做點乘得到一個 大小為(sequence length, 1)的分數。
第二步:對分數做softmax得到一個合為1的權重。
第三步:將H與第二步得到的權重做點乘得到一個大小為(hid dim, 1)的context vector。
完結