
BP神經網路——如何進行權值的初始化
阿新 • • 發佈:2019-02-04
如果以面向物件(OOP)的方式進行BP神經網路系統的設計與實踐的話,因為權值的初始化以及類的構造都只進行一次(而且發生在整個流程的開始階段),所以自然地將權值(全部層layer之間的全部權值)初始化的過程放在類的構函式中,而權值的初始化,一種trivial常用的初始化方法為,對各個權值使用均值為0方差為1的正態分佈(也即np.random.randn(shape))進行初始化,也即:
class Network(object):
# topology:表示神經網路拓撲結構,用list或者tuple來實現,
# 比如[784, 30, 10],表示784個神經元的輸入層,30個neuron的隱層,以及十個neuron的輸出層 我們不妨以一個簡單的具體例子,分析這種初始化方法可能存在的缺陷,如下圖所示:
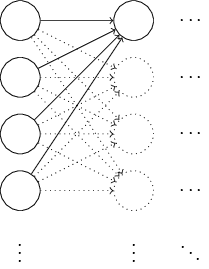
為了簡化問題,我們只以最左一層向中間一層的第一個神經元(neuron)進行前向(forward)傳遞為例進行分析,假設一個輸入樣本(特徵向量,
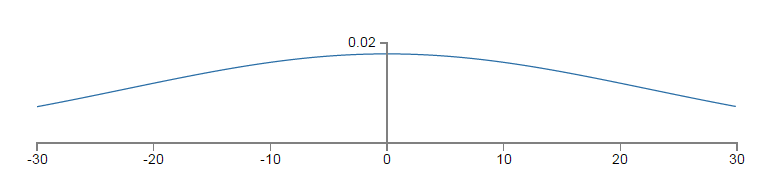
以上的平坦的概率密度函式為
而權值更新公式為:
也就意味著越小的
如何進行改進呢?假使輸入層有
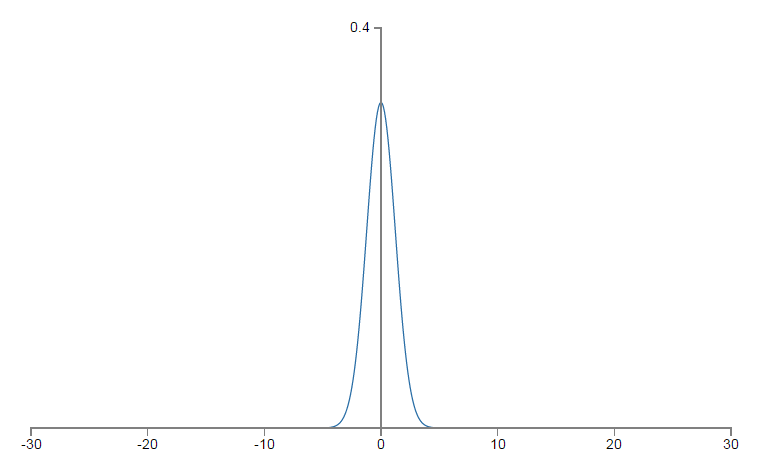
相關程式碼:
def default_weight_init(self):
self.biases = [np.random.randn(y, 1)/y for y in self.topology[1:]]
self.weights = [np.random.rand(y, x)/np.sqrt(x) for x, y in zip(self.topology[:-1], self.topology[1:])]
def large_weight_init(self):
self.biases = [np.random.randn(y, 1) for y in self.topoloy[1:]]
self.weights = [np.random.randn(y, x)/np.sqrt(x) for x, y in zip(self.topology[:-1], self.topology[1:])]我們看到正是這樣一種np.random.randn(y, x)向np.random.randn(y, x)/np.sqrt(x)小小的改變,卻暗含著豐富的概率論與數理統計的知識,可見無時無刻無處不體現著數學工具的強大。