
強化學習學習筆記——介紹強化學習(reinforcement learning)
眾所周知,當AlphaGO戰勝了世界圍棋冠軍李世石之後,整個工業界都為之振奮,越來越多的學者意識到強化學習在人工智慧領域是一個非常令人exciting的。在此我就分享一下本人的強化學習學習筆記。
強化學習基本概念
機器學習可以分為三類,分別是 supervised learning,unsupervised learning 和reinforcement learning。而強化學習與其他機器學習不同之處為:
- 沒有教師訊號,也沒有label。只有reward,其實reward就相當於label。
- 反饋有延時,不是能立即返回。
- 相當於輸入資料是序列資料。
agent執行的動作會影響之後的資料。
強化學習的關鍵要素有:environment,reward,action 和 state。有了這些要素我們就能建立一個強化學習模型。強化學習解決的問題是,針對一個具體問題得到一個最優的policy,使得在該策略下獲得的reward最大。所謂的policy其實就是一系列action。也就是sequential data。
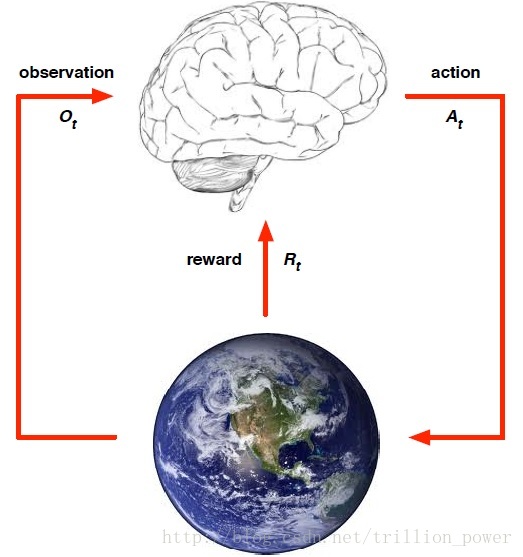
強化學習可用下圖來刻畫,都是要先從要完成的任務提取一個環境,從中抽象出狀態(state) 、動作(action)、以及執行該動作所接受的瞬時獎賞(reward)。
reward
reward通常都被記作
Rt ,表示第t個time step的返回獎賞值。所有強化學習都是基於reward假設的。reward是一個scalar。action
action是來自於動作空間,agent對每次所處的state用以及上一狀態的reward確定當前要執行什麼action。執行action要達到最大化期望reward,直到最終演算法收斂,所得的policy就是一系列action的sequential data。
state
就是指當前agent所處的狀態。具體來講,例如玩pong遊戲(Atari的遊戲),
該遊戲的狀態就是當前time step下小球的位置。而Flappy bird狀態就是當前小鳥在平面上的位置。
policy
policy就是隻agent的行為,是從state到action的對映,分為確定策略和與隨機策略,確定策略就是某一狀態下的確定動作
a , 隨機策略以概率來描述,即某一狀態下執行這一動作的概率:=π(s)π(a|s)=P[At=a|St=s] 。value function
因為強化學習今本上可以總結為通過最大化reward來得到一個最優策略。但是如果只是瞬時reward最大會導致每次都只會從動作空間選擇reward最大的那個動作,這樣就變成了最簡單的貪心策略(Greedy policy),所以為了很好地刻畫是包括未來的當前reward值最大(即使從當前時刻開始一直到狀態達到目標的總reward最大)。因此就夠早了值函式(value function)來描述這一變數。表示式如下:
γ 是折扣係數(取值在[0,1] ),就是為了減少未來的reward對當前動作的影響。然後就通過選取合適的policy使value function最大,稍後會為大家推導著名的bellman方程,bellman方程才是強化學習各大演算法(e.g. 值迭代,策略迭代,Q-learning)的源頭。model
model就是用來預測環境接下來會幹什麼,即在這一狀態的情況下執行某一動作會達到什麼樣的狀態,這一個動作會得到什麼reward。所以描述一個模型就是用動作轉移概率與動作狀態reward。具體公式如下:

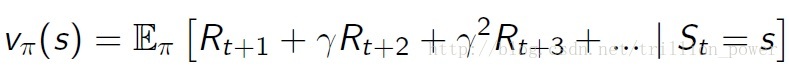
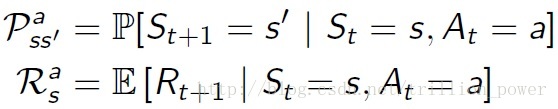
馬爾可夫決策過程(MDP)
大家應該都很熟悉馬爾科夫過程,其實就是狀態以及某狀態的轉移,最重要的就是一步轉移概率矩陣,只要有了這個一步轉移概率矩陣就能刻畫整個馬爾科夫過程。
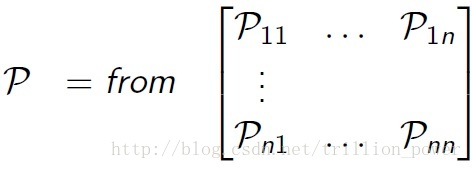
下面就來介紹一下馬爾可夫決策過程(MDP)它主要由以下幾個變數來刻畫,狀態空間
下面介紹一個MDP常用的用來刻畫獎賞的函式。
1.return
t時刻之後未來執行一組action後能夠獲得的reward,即t+1,t+2…所有時刻的reward之和。(未來時刻的reward在當前時刻體現),後面的reward要乘以discount

2.狀態值函式
定義為t時刻狀態S能獲得的return的期望,表示式如下:
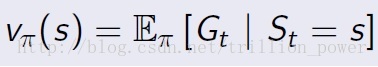
3.動作值函式
t時刻狀態S下選擇特定action後能獲得的return的期望,表示式如下:
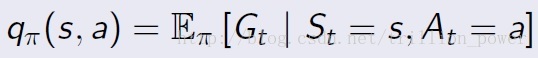
下面來講解一下最著名的bellman方程的推導,首先推導如何迭代值函式,即更新值函式:
1.value function
2.Q-value function