
無監督式學習-鳶尾花資料降維and聚類
阿新 • • 發佈:2019-02-05
一. 使用PCA(主成分分析)進行降維實現資料視覺化
降維的任務是要找到一個可以保留資料本質特徵的低維矩陣來表示高維資料, 通常用於輔助資料視覺化的工作.
下面我們使用主成分分析(principal component analysis, PCA)方法, 這是一種快速線性降維技術. 模型返回兩個主成分, 用二維資料表示鳶尾花的4維資料.
1. 首先匯入資料
import seaborn as sns
sns.set()
iris = sns.load_dataset('iris')
print(iris) # 輸出檢視資料
2. 劃分資料, 特徵和標籤
X_iris = iris.drop( 3. 選擇PCA模型, 進行擬合
from sklearn.decomposition import PCA
model = PCA(n_components=2) # 設定超引數, 初始化模型
model.fit(X_iris) # 進行擬合
X_2D = model.transform(X_iris) # 將資料轉化為二維
4. 圖形視覺化
思路是將二維資料插入到DataFrame中, 然後用seaborn的lmplot方法繪製圖形.
iris['PCA1'] = X_2D[:, 0]
iris['PCA2' 結果展示:
可以看到PCA降維成功地將鳶尾花的種類在視覺上進行劃分.
原先的資料集是4維, 難以進行視覺化, 降維後在2維上實現視覺化.

二. 使用高斯混合模型對鳶尾花資料進行聚類
1. 首先匯入資料
import seaborn as sns
sns.set()
iris = sns.load_dataset('iris')
print(iris) # 輸出檢視資料
2. 劃分資料, 特徵和標籤
X_iris = iris. 3. 使用主成分分析進行降維(為了視覺化為2維資料)
from sklearn.decomposition import PCA
model = PCA(n_components=2) # 設定超引數, 初始化模型
model.fit(X_iris) # 進行擬合
X_2D = model.transform(X_iris) # 將資料轉化為二維
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
4. 選擇高斯混合模型
from sklearn.mixture import GMM
model = GMM(n_components=3, covariance_type='full') # 設定超引數
model.fit(X_iris) # 擬合數據
y_gmm = model.predict(X_iris) # 確定簇標籤
5. 資料視覺化
iris['cluster'] = y_gmm
sns.lmplot('PCA1', 'PCA2', data=iris, hue='species', col='cluster', fit_reg=False)
如圖, 資料根據簇的不同被成三類.
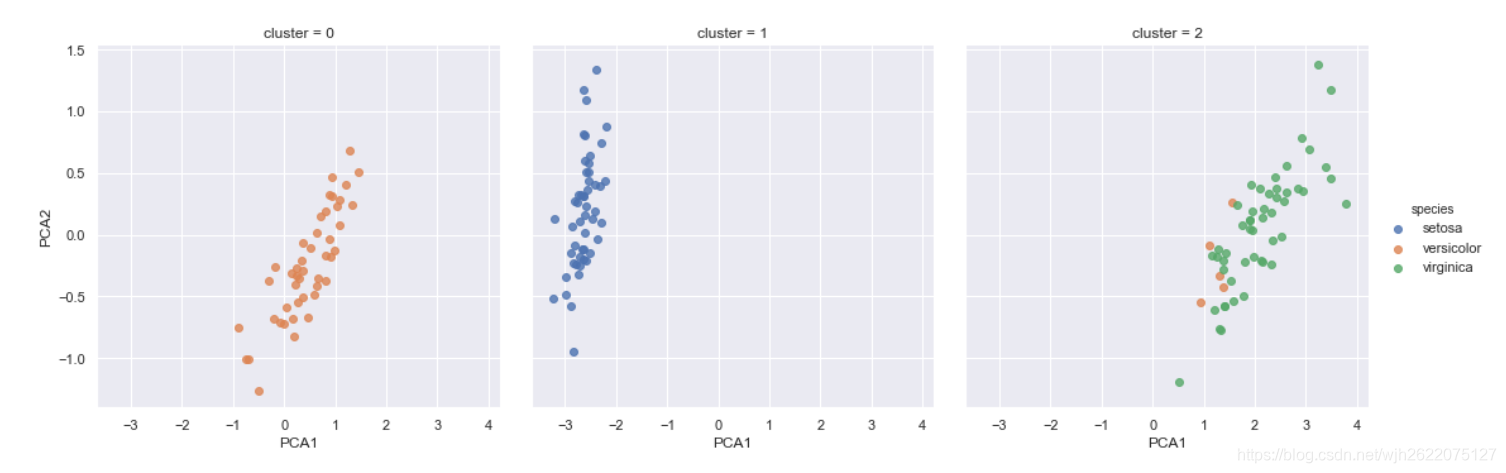
可以看到圖一和圖二的分類基本正確, 圖三有少數的點是屬於圖二.