
傳統Active MQ與大資料下的分散式Kafka
阿新 • • 發佈:2019-02-05
本人在Zuora工作的時候,幾乎所有的非同步業務邏輯都使用ActiveMQ,對AMQ也算頗為熟悉。現如今每天和Kafka打交道,對kafka也算駕馭的不錯。現在基於這兩者做個小比較。
首先,Active MQ與Kafka的相同點只有一個,就是都是訊息中介軟體。其他沒有任何相同點。
- 關於consume
- 關於儲存結構
- 關於使用場景與吞吐量
- 關於訊息傳遞模型
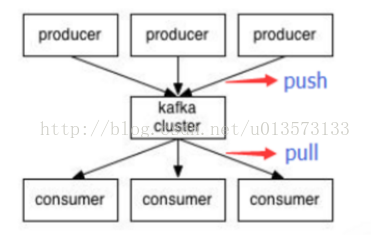
- push/pull 模型
那麼,ActiveMQ中如何採用Push方式或者Pull方式呢?
從是否阻塞來看,消費者有兩種方式獲取訊息。同步方式和非同步方式。
同步方式使用的是ActiveMQMessageConsumer的receive()方法。而非同步方式則是採用消費者實現MessageListener介面,監聽訊息。使用同步方式receive()方法獲取訊息時,prefetch limit即可以設定為0,也可以設定為大於0
prefetch limit為零 意味著:“receive()方法將會首先發送一個PULL指令並阻塞,直到broker端返回訊息為止,這也意味著訊息只能逐個獲取(類似於Request<->Response)”
prefetch limit 大於零 意味著:“broker端將會批量push給client 一定數量的訊息(<= prefetch),client端會把這些訊息(unconsumedMessage)放入到本地的佇列中,只要此佇列有訊息,那麼receive方法將會立即返回,當一定量的訊息ACK之後,broker端會繼續批量push訊息給client端。” 當使用MessageListener非同步獲取訊息時,prefetch limit必須大於零了。因為,prefetch limit 等於零 意味著訊息中介軟體不會主動給消費者Push訊息,而此時消費者又用MessageListener被動獲取訊息(不會主動去輪詢訊息)。這二者是矛盾的。 Kafka使用PULL模型,PULL可以由消費者自己控制,但是PULL模型可能造成消費者在沒有訊息的情況下盲等,這種情況下可以通過long polling機制緩解,而對於幾乎每時每刻都有訊息傳遞的流式系統,這種影響可以忽略。 Kafka 的 consumer 是以pull的形式獲取訊息資料的。 pruducer push訊息到kafka cluster ,consumer從叢集中pull訊息。