
【易通慧谷】業務風控產品模型思考:解讀業務模型的6個層級
阿新 • • 發佈:2019-02-05
一直想找個機會說說我對業務風控的一些業務及產品上的理解。由於業務敏感性,有些東西不能寫的太詳細,見諒.

業務風控重要性
如果把平臺比喻為一顆樹,那麼需要投入足夠的養分才能快速生長,而業務風險則是寄生於樹木竊取養分的角色,只有能夠充分抵禦這種風險的才能成長為參天大樹。這就是業務風險在平臺發展中扮演的角色。在大部分場景下,風控意味著阻斷使用者操作,在大部分人眼裡與使用者體驗是背道而馳的存在。單就電商領域而言,競爭逐漸白熱化,使用者體驗成為了吸引使用者的重要因素,此時風控如何在儘可能少打擾到使用者的情況下,能阻斷儘可能多的惡意行為?這是一場善與惡的博弈,也是關乎生死存亡的博弈。
業務風控的原則
在這裡,需要提出行業內一個著名的原則:輕管控,重檢測,快響應,私以為基本能實現使用者體驗與風控需要的平衡。怎麼來理解這個原則呢?個人認為:
輕管控:在出現風險,需要阻斷使用者操作時,阻斷動作宜輕不宜重。能驗證碼校驗就不簡訊校驗,能簡訊校驗就不禁訪。同時被阻斷後文案,下一步出口都需要照顧使用者感受。看似簡單,其實背後涉及到對使用者風控行為以及對使用者風控阻斷動作的分層管理。
重檢測:通過儘可能多的獲取使用者資訊(包括靜態及動態資料),由規則引擎進行實時或離線計算,來動態分析每個使用者及採取行為的風險程度。這裡需要儘量全的資料來源,以及非常強大的規則引擎,才可以實現良好的檢測效果。
快響應:
業務風控的業務模型設計
說完了原則,我們怎麼具體來看業務風控的業務模型設計呢?
在我理解,業務風控的業務模型主要分為六層,分別為資料輸入層,資料計算層,資料輸出層,運營管控層,業務接入層以及使用者觸達層。
大家可以看到,下面三層,是偏向於資料,研發的;上面三層,是偏向於業務,運營,產品的。做風控其實就是做資料,因此資料的接入、技術、處理是其中最核心的模組;但現階段,由於演算法模型的限制,還需要有人為的因素進行規則模型的校正,以及特殊樣本的審理,因此會有運營層的存在;最上面的觸達層,是拿結果的一層,產品的部分工作也在於對此進行良好的設計。
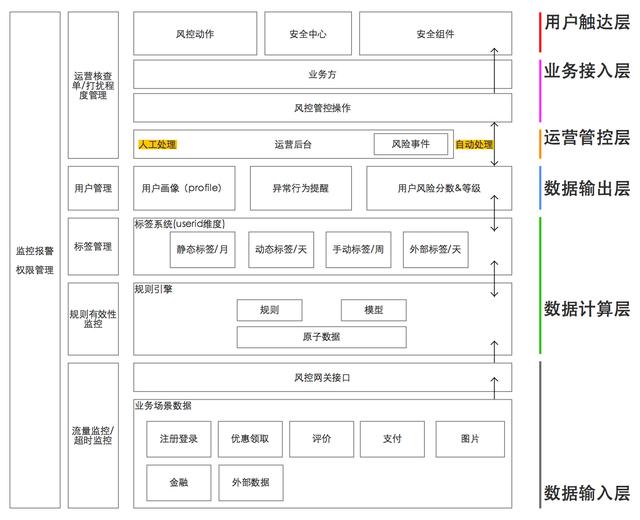
一、資料輸入層
如何獲取資料?獲取什麼資料?資料準確性如何?這是資料輸入層需要解決的三個問題。
1、獲取資料方式
目前獲取資料主要有兩種方式,一種是主動獲取,一種是被動獲取。
1)主動方式
主動方式是自己去業務方資料庫、日誌裡面去讀,這樣可以拿到最全的資訊,而不用依賴訊息報等被處理過的二手資料。有些比較成熟的公司有自己的訊息匯流排,風控可以去實時的訂閱資訊然後作為資料來源進行分析;但在公司沒有訊息匯流排的時候,風控可以發揮自己橫向,跨業務的優勢,建立自己的訊息匯流排,去獲取資料進行分析。這樣的好處是對業務方依賴降低,資料來源最全,能進行深入的資料探勘;壞處是建立難度較大,需要大量資源支援,適合較為成熟的公司。
2)被動方式
被動方式就是提供介面給業務研發,讓業務把訊息按格式標準傳過來。這種配合週期非常長,但成本較低,可以按照標準來拿到高質量的資訊,所以是比較常見的風控系統搭建方式。
2、獲取資料種類
鑑於目前大部分公司都採用第二種方式,因此與業務方如何合作,獲取高質量的資料就很重要了。對資料種類的要求是能全就全,能深就深。以筆者做過的賬號安全業務為例:
1)資料全面程度
往往風控關心的資訊比如IP地址、referer這些資訊業務都是不關心的,但這些資訊的缺失可能造成很多策略沒法做,所以在採集資訊開始的時候就要有個明確的資訊列表。
2)資料詳細程度
以註冊登入行為為例對資料詳細程度進行深入:
基礎的登陸註冊資料,就可以從頻率、登陸註冊特徵來進行分析;
進一步拿到登入註冊行為的上下文,比如登陸前訪問了哪些頁面,登陸後去訪問了什麼,就可以從訪問行為軌跡來增加更多的分析維度,例如頁面停留時間,是否有訪問到必訪問的頁面;
使用者的操作行為資料,比如滑鼠移動的軌跡,鍵盤輸入,進一步的從操作過程來增加分析維度,比如是不是輸入密碼的時候有過多次輸入刪除?是不是直接複製貼上的賬號密碼?
3、獲得的資料準確性
比較常見的例子:需要使用者的訪問IP,結果拿到的IP地址是內網的伺服器IP;或者是想要使用者名稱,結果傳遞過來的是UID。這點需要大量的前期溝通確認工作。
如何在日常工作中確保資料的準確性呢?
1、對採集回來的資料必須定期的對資料質量進行監控——
已經採集到的資料可能因為技術架構調整,程式碼更新等各類奇葩原因造成採集回來的資料不準了,如果無法及時發現可能造成後面一系列分析過程都出現錯誤。
2、採集點儘量選擇穩定的業務點,比如採集登入日誌,一次性在公共服務採集好,後面出現問題只要找一個點。但如果是去前端從WEB、移動端等各個呼叫登入服務的點去採集,出了問題要改動的工作就會成倍增加,還有可能出現新業務點的日誌無法覆蓋的情況。
資料輸入原則:宜早不宜晚,宜全不宜少;
資料分層處理:實時資料與離線資料分離。實時資料接入需要評估RT時間及準備一旦被降級的預案。
二、資料計算層
資料計算層是由各種規則、模型等演算法形成的計算核心,一般都依附在一個強大的規則引擎之上。
為什麼採用規則引擎?因為黑產的反應速度實在太快了。如果把風控規則都硬編碼進業務程式碼中,那一旦規則被繞過,反應速度就會非常慢。規則引擎必須能把策略邏輯從業務邏輯中解藕出來,讓防禦者可以靈活配置規則在靜默模式下驗證和實時上線生效,並可以去隨時調整。
雖然說資料技術層主要是研發和演算法同學處理的,但作為產品可以做的,除了瞭解基本的規則,模型及實現原理外,還可以增加對規則的生命週期及健康度的評估,比如:風控系統的規則有多少?哪些已經很久沒有觸發了?產生誤判投訴的對應規則有哪些?
一個新規則在建立起初的效果肯定是最有效的(因為這時風險問題正在發生,而規則正好對應了風險),但隨著時間其有效性是快速下降的,比如攻擊者都知道網站三次輸入密碼錯誤觸發驗證碼,那麼他們會傻傻的嘗試第三次猜測密碼的概率有多大?那麼是否有人在定期的去統計分析這些規則的效率就是風控產品的重要運營環節了,而運營風控產品所要付出的代價是往往大於常規網際網路業務產品的,並且是保證專案能夠持續產出價值並不斷迭代進化的一個前提。
三、資料輸出層
資料輸出層是將資料計算層的計算結果轉化為可以被下游使用的分數,主要的輸出為使用者的風險畫像,風險分數及風險等級。
資料輸出層主要的原則是資料可讀性高(因為會直接被運營及下游業務方消費,需要降低使用方的使用成本,提高效率)以及可複用性(一個輸出的資料,可以在多個場景下被使用。比如垃圾註冊的資料可以同時被反欺詐,反作弊等場景使用)。由於使用者分層及使用者畫像展開來說內容比較多,就不展開了,大家可以自行百度。
四、運營管控層
如果說上面三層主要靠技術的手段來實現風險管控,那麼運營管控層主要是靠人為經驗來對技術尚無法處理的風險進行管控。
技術尚無法進行處理的風險主要分為兩種,一是樣本較少,計算準確度不足,然而危害較大的風險行為,比如金融盜卡,詐騙等;二是人為,非機器行為的風險行為,比如工作室層次的大量人工刷單等。以上兩種都是需要運營的經驗來進行判斷會更為合理。同時運營層的處理結果也會反饋到資料輸出層,優化資料輸出的準確性,也有利於為演算法及模型提供較為準確的樣本進行學習。
運營管控層主要是風控運營後臺的設計,由於各個運營後臺設計的特點不一而足,因此在這裡只說明主要的涉及原則,主要包括可讀性以及案件存檔。
1.可讀性:
讓分析人員可以快速的查詢原始日誌:日誌並不是簡單的存下來,從風控分析的需求來看,通過IP、使用者名稱、裝置等維度在一個較長的跨度中搜索資訊是非常高頻的行為,同時還存在在特定型別日誌,比如在訂單日誌或者支付日誌中按特定條件搜尋的需求。
機器語言轉化為自然語言:這主要是為了能夠讓分析人員可以快速的還原風險CASE,例如從客服那邊得到了一個被盜的案例,那麼現在需要從日誌中查詢被盜時間段內這個使用者做了什麼,這個過程如果有一個介面可以去做查詢,顯然比讓分析人員用grep在一大堆檔案中查詢要快的多,並且學習門檻也要低得多。
如果在日誌做過標準化的前提下,也可以進行後續的業務語言轉譯,將晦澀難懂的日誌欄位轉化為普通員工都能看得懂的業務語言,也能極大的提升分析師在還原CASE時閱讀日誌的速度。
2.案件存檔:
這裡指將實時或離線的計算加工訊息成變數&檔案。例如在分析某個帳號被盜CASE的時候,往往需要把被盜期間登入的IP地址和使用者歷史常用的IP地址進行比對,即使我們現在可以快速的對原始日誌進行查詢,篩選一個使用者的所有歷史登入IP並察看被盜IP在歷史中出現的比例也是一個非常耗時的工作。
再比如我們的風控引擎在自動判斷使用者當前登入IP是否為常用IP時,如果每次都去原始日誌裡面查詢聚合做計算也是一個非常“貴”的行為。
那麼,如果能預定義這些變數並提前計算好,就能為規則引擎和人工節省大量的時間了,而根據這些變數性質的不同,採取的計算方式也是不同的。不過還好我們有一個標準可以去辨別:頻繁、對時效敏感的利用實時計算;而相對不頻繁、對時效不敏感的利用離線計算,以這樣的原則進行指導,就可以儘可能節省時間了。
五、業務接入層
風控的業務模型是環環相扣的,在已經具備了資料處理能力以及運營後臺之後,如果沒有業務方接入,那相當於只有內功而無法出拳,這樣就只是風控內部的自娛自樂,無法為業務保駕護航。在風控與業務技術的合作中,由於業務為王,一切要以業務為重,因此風控在合作中,需要注意:儘可能避免給業務帶來不必要的麻煩。
如何做到與業務進行良好的合作,主要從4點出發:
1、呈現給業務研發直白的判定結果
我們最終從資料中發現的報警和問題最終是要在業務邏輯中去阻攔的,在接入這些結果的時候,往往分析師覺得可以提供的資訊有很多,比如命中了什麼規則、這些規則是什麼、什麼時候命中的、什麼時候過期,一個code list給他們說明對應希望做的操作,一定把中間結果等等包裝成最終結果再給出去。
2、實時與離線計算分離,降低業務系統壓力
因為T+0在接入的時候要額外承擔很多計算成本,結果要現場算出來而延時要求又很高,所以一般都只在攻擊者得手關鍵步驟採取實時判斷(比如訂單支付或者提現請求)。而對於其他場景可以選擇T+1方式,比如登入或者提交訂單等。
3、超時及降級預案准備
風控風險判斷的最基本原則就是要不影響業務邏輯,所以超時機制在一開始就要嚴格約定並執行,一旦發現風控介面超過預計響應時間立馬放行業務請求。
4、充分關注業務流量
平時可能流量很小的業務,突然因為某個活動(比如秒殺)流量大增,除了在接入之初要對風險判斷請求有了解,對後續的活動也要提前準備,否則如果資源預估不足,突然又趕上這個點接了T+0介面有很多要現場計算的邏輯,那業務分分鐘會把風控降級。
六、使用者觸達層
終於來到最後一層,使用者觸達層了。風控的使用者觸達,主要包括各種C端的安全中心,安全元件以及多樣的風控阻斷操作。在這一層,需要做的是細化管控手段,以及重視使用者體驗。
1、細化管控手段
風控管控手段需要豐富,包括圖形驗證碼,語音驗證碼,實名校驗,touchid校驗,密保問題,禁訪,禁買,禁言等,在不同場景下,採取對應的方式,而不是千遍一律。千遍一律的話,太輕會導致管控效果不佳;太重的話會極大影響使用者體驗。
2、重視使用者體驗
這點說起來容易做起來難。在獲客成本高昂的今天,假設獲客成本是100塊,他可能因為被風控之後,文案的簡單粗暴,缺少申訴出口或者流程難以繼續而選擇用腳投票,從而離開。而這些是產品可以做的事情。使用提醒式而非警告式的文案;在被風控後及時提示使用者後續的操作;與客服同學加強溝通(任何風控準確率都不是100%的,所以在和研發溝通好接入後一定要告訴一線同事們風控阻斷可能出現的表象(文案提示),以及大致的原因,以避免一線客服們對風險攔截的投訴不知道如何解釋,並給出具體的阻斷回覆措施(CRM後臺增加白名單、刪除黑名單許可權等等))都是可以有效提高使用者體驗的方法。
以上就是我對業務安全風控業務模型的理解。因為風控涉及的東西較為敏感,所以上面的說法都脫敏處理了下,具體的規則、策略,使用者畫像的構造等均沒有細說,大家可以自行百度。