
Apache Kafka 簡介與使用
Kafka 可以簡單理解為分散式MQ,用Scala編寫,執行在JVM上。
分散式程式,除了其自身的基本概念外,最重要的就是要知道它是如何實現高併發和高可用的:
- Kafka 用 Partitions 實現了高併發;
- Kafka 用 Partitions 複製 + Zookeeper 實現了高可用;
注:以下內容中英文混合存在,只是為了描述方便。更全面和準確的文件,可以檢視Kafka官網。
一、Kafka - 簡介
Apache Kafka is a distributed streaming platform. 卡夫卡是一個分散式流平臺。
它有三個關鍵的能力:
訊息佇列 - 可以使你能pub/sub streams of records
. 從這方面看,它很像一個訊息佇列。容錯儲存 - 使你可以儲存streams of records in a fault-tolerant way.
流處理 - 可以使你能夠處理 stream of records 在它們出現時。
有三個基本概念:
作為叢集執行 - Kafka is run as a cluster on one or more servers.
主題 - The Kafak cluster stores stream of records in categories called topics.
Record = key + value + timestamp- Each record consists of a key, a value and a timestamp.
有四個核心API:
釋出者 - The Producer API allows an application to publish a stream of records to one or more Kafka topics.
消費者 - The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
流處理 - The Streams API allows an application to act as stream processor, 使得你能從topics消費輸入流和產生輸出流到topics上。
聯結器 - The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
Kafka 構建了一個語言無關的基於TCP protocol 的通訊機制,用來高效能的實現clients 和 servers 之間通訊;
1、Topics and Logs - 主題和日誌
Topic - 主題
一個 topic 是一個型別名,指示哪些records被髮布。
對於每個 topic, Kafka 叢集會將其儲存為一個被分割槽的log ,就像下圖這樣:
(Topic = partitioned log 0 + partitioned log 1 + partitioned log 2)每個分割槽都是一個ordered, immutable sequence of records,它們會被不斷的追加到 a structured commit log.
每個分割槽中的記錄都被分配一個順序的id,稱為唯一標示此分割槽內每個記錄的 offset.
Kafka叢集儲存所有被髮布的 records 無論它們是否已被消費,可以用一個配置來控制。
例如:log.retention.hours=148,代表在記錄釋出的6天后才會將其刪除。
Log - 日誌
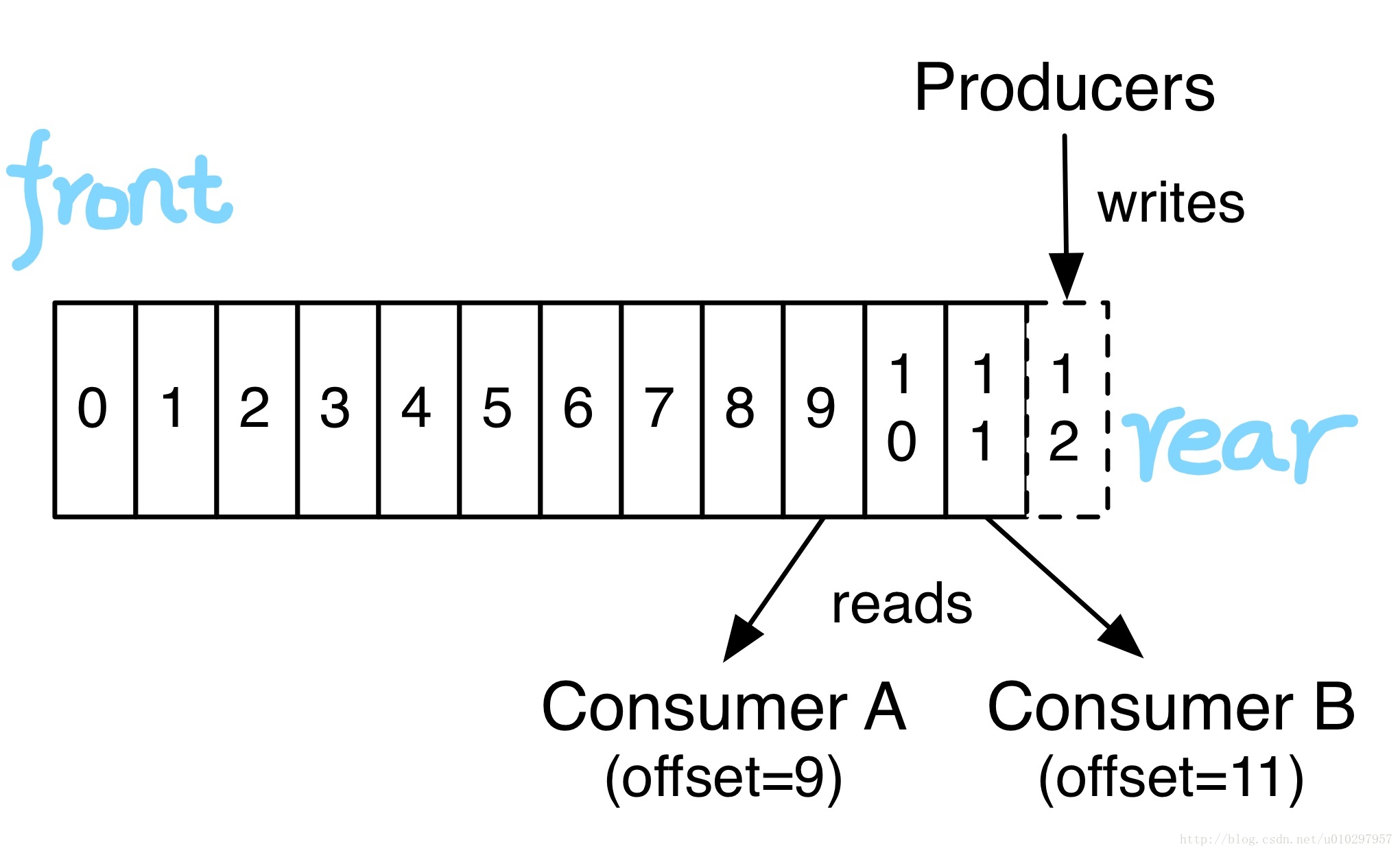
事實上,每個消費者唯一需要持有的元資料基本上就是log的the offset or position,消費者控制自己的offset:可以線性的讀、也可以從任何位置開始讀,因為自己控制position。
以上這些Topic和Log的特性決定了消費者消費這件事是非常廉價容易的,他們可以隨意來隨意消費而互不影響。
Partitions - 分割槽
Log的Partitions即是水平切分,它服務於以下兩個目的:
(擴容)首先,可以使Log的擴充套件能超過安裝在一臺單機上的大小限制。
每個Partition必須安裝在託管它的伺服器上,但是Topic可以有很多Partition,所以Topic理論上可以處理無限量的資料;
分割槽會被均衡的分佈於叢集中的每臺機器上。
(高併發)第二,Partition們作為並行的單位,更多的是在這點上;
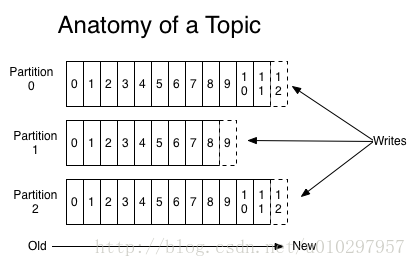
2、Distribution - 分散式
Log的分割槽們會被分佈在Kafka伺服器叢集中,每個伺服器處理自己分到分割槽。每個分割槽會被複製為建立時指定的複製數量,引數--replication-factor N 。
每個partition有一個被稱為”Leader”的節點,0或多個”Followers”:
Leader處理所有讀和寫請求,Followers被動的從leader複製。
如果Leader掛掉了,那麼叢集會在Follower中重新選出一個Leader;
3、舉例
一個有3臺伺服器的Kafka叢集。(安裝過程在後面,這是假設安裝過了)
使用如下命令建立一個Topic:
# Topic名 TestTopic001,分割槽數2,複製因子1(即不復制) [[email protected] bin]# ./kafka-topics.sh --create --topic TestTopic001 --partitions 2 --replication-factor 1 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181然後檢視:
[[email protected] bin]# ./kafka-topics.sh --describe --topic TestTopic001 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181輸出如下:
Topic:TestTopic001 PartitionCount:2 ReplicationFactor:1 Configs: Topic: TestTopic001 Partition: 0 Leader: 2 Replicas: 2 Isr: 2 Topic: TestTopic001 Partition: 1 Leader: 3 Replicas: 3 Isr: 3此時被生成的Topic目錄
在叢集中的3臺伺服器(
broker)中,Kafka將兩個分割槽分別放在了broker-2和broker-3上。此時去到兩臺機器的事務日誌目錄下,可以看到生成了相應的主題分割槽的目錄:broker-1:無目錄生成broker-2:- <log_dir>/TestTopic001-0
- 00000000000000000000.index
- 00000000000000000000.log
- 00000000000000000000.timeindex
- …
- <log_dir>/TestTopic001-0
broker-3:- <log_dir>/TestTopic001-1
- 00000000000000000000.index
- 00000000000000000000.log
- 00000000000000000000.timeindex
- …
每個Topic的每個分割槽會對應一個單獨的目錄,其下有配套的Log檔案 + index檔案 + timeindex檔案
- <log_dir>/TestTopic001-1
引數
分割槽
--partitions是任意正整數,會被分散在所有broker上,越多的分割槽一般意味著越高的併發。複製因子
--replication-factor是不能大於broker數量的,如果等於broker數量,則會在每臺broker上都複製一份。正如文首所說:
Partitions - 分割槽(即水平切分),實現了高併發;
Partitions 的複製(複製因子>1)+ Zookeeper 實現了高可用;
3、Producers - 生產者
生產者釋出資料到Topic中。
生產者還負責給record選擇分割槽:
- 可以簡單的使用輪詢(round-robin)方式簡單的負載均衡。
- 或者可以根據某些語義分割槽函式(例如基於record中的某個key)。
4、Consumers- 消費者
一、概述
消費者通過一個group name 來標記自己,每個被髮布到topic上的record只會被消費者組中的一個例項所消費。
Records會負載均衡的被髮送到同組中的所有消費者例項上。
如果所有消費者例項都有不同的group name ,那這就是廣播了。
二、分析一個例項如下
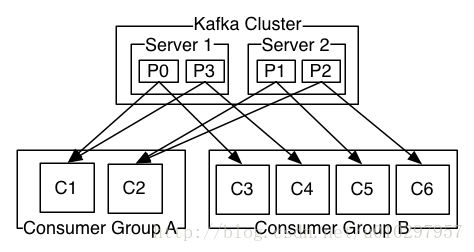
- 一個兩臺伺服器組成的Kafka叢集,每個Topic會被分為4個Partition(P0-P3);
- 假設有2個客戶端應用在消費:
- 第1個應用的消費者組叫Group A,它啟動了2個消費者例項。
- 第2個應用的消費者組叫Group B,它啟動了4個消費者例項。
三、消費者與分割槽
Kafka實現消費的方式是通過將log中的分區劃分到消費者例項上,以便每個例項都是任何時間點的“fair share”分割槽的唯一消費者。維護成員資格的過程由Kafka協議動態處理。
- 一個分割槽只能被一個消費者組中的唯一的一個例項所訂閱;
- 消費者組中的例項數量不能超過Topic分割槽數量;
- 如果新的消費者例項加入,它們將從組中其他成員接管一些分割槽;
- 如果一個例項消失,其分割槽將被分發到剩餘的例項。
四、順序
Kafka僅提供分割槽內的順序,而不提供跨分割槽的即Topic的總順序。如果需要保證Topic的總順序,則可以使用僅具有一個分割槽的Topic,不過這意味著每個消費者group只能有一個消費者例項。
二、開源訊息系統比較
| - | ActiveMQ | RabbitMQ | Kafka |
|---|---|---|---|
| 所屬社群/公司 | Apache | Pivotal Software | Apache/LinkedIn |
| 開發語言 | Java | Erlang | Scala |
| 可支援協議 | OpenWire、STOMP、REST、XMPP、AMQP | AMQP | 仿 AMQP |
| 事務 | 支援 | 不支援 | 不支援 |
| 叢集 | 支援 | 支援 | 支援 |
| 負載均衡 | 支援 | 支援 | 支援 |
| 動態擴容 | 不支援 | 不支援 | 支援(通過zookeeper) |
| 高效能、高吞吐 | 否 | 否 | 是 |
| 其它 | 是JMS的實現 |
三、安裝與使用
1. 安裝
Kafka依賴Zookeeper,所以要先安裝Zookeeper(Zookeeper簡介、安裝與使用),安裝後啟動。
-
tar -zxf kafka_2.12-0.10.2.1.tgz -C <YOUR_DIR> // 為了方便,將目錄重新命名為kafka mv kafka_2.12-0.10.2.1/ kafka 修改伺服器配置檔案:
由上文描述我們知道,Kafka天生是叢集的即使只有一個broker,所以我們配置多個broker的情況,修改每個機器上的配置檔案
<Kafka_home>/config/server.properties:############################# Server ############################# # broker id 要全叢集唯一,你的每個機器上要配置不一樣的(既然註冊在zookeeper上也可以叫zookeeper上唯一),我是直接設定的1、2、3 broker.id = 1 # Switch to enable topic deletion or not, default value is false delete.topic.enable=true # Kafka的Socket Server監聽的地址和埠,這裡最好自己顯示設定一下,否則值是Java的方法java.net.InetAddress.getCanonicalHostName()的返回值。 ## 監聽本機所有網路介面(network interfaces) listeners=PLAINTEXT://0.0.0.0:9092 ## 被髮布到Zookeeper上,公佈給Client讓Client使用 advertised.listeners=PLAINTEXT://kafka1.host:9092 ############################# Log ############################# # log檔案儲存目錄 log.dir = <dirctory what you want> # 預設Topic分割槽數量 num.partitions=3 # log檔案在被刪除前的儲存時間 log.retention.hours=168 ############################# Zookeeper ############################# # 你的zookeeper叢集的地址 zookeeper.connect=zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181log4j配置:
在
<kafka_home>/config/log4j.properties中,有各種型別日誌的輸出配置,需要怎樣改變可以自行修改,這部分屬於log4j部分,就不再詳述;我這裡是修改為按day分檔案、修改日誌路徑;
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender ... log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender # '.'yyyy-MM-dd-HH修改為'.'yyyy-MM-dd log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd # 可以看到修改日誌路徑,只需要定義kafka.logs.dir就行 log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log ... ...修改
<kafka_home>/bin/kafka-run-class.sh裡LOG_DIR的賦值即可# Log directory to use if [ "x$LOG_DIR" = "x" ]; then # "$base_dir/logs"修改為"/data/logs/kafka" LOG_DIR="/data/logs/kafka" fi啟動,啟動指令碼是在
<kafka_home>/bin/kafka-server-start.sh,如果機器記憶體不夠可以先修改下指令碼中Kafka使用的JVM堆記憶體設定:if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx300M -Xms300M" fi然後啟動:
# 指定後臺啟動;指定配置檔案地址 [root@host kafka]# bin/kafka-server-start.sh -daemon config/server.properties也可以先不加
-daemon,用以看是否有正常日誌輸出,正常的話直接結束程序再使用-daemon啟動。
2. 網路
有可能你的Linux伺服器或Kafka配置不對,會導致各種網路的問題,在這裡我專門列出來。(使用netstat -anp | grep 9092來檢視埠的監聽和連線情況。)
首先是Kafka自身的配置,在
<Kafka_home>/config/server.properties中:listeners
listeners=PLAINTEXT://0.0.0.0:90920.0.0.0代表監聽本機所有網路介面(network interfaces),最好這樣做!尤其當你使用的是阿里雲等雲服務提供商的機器時。因為雲伺服器一般有內網IP和外網IP(即內網網路介面和外網網路介面),而如果你僅僅監聽內網IP的話,由於外部網路訪問此伺服器只能用外網IP,則訪問肯定會被拒絕。advertised.listeners
advertised.listeners=PLAINTEXT://<your_hostname>:9092<your_hostname>被髮布到Zookeeper上,被直接公佈給Client讓Client使用:可以直接賦值為伺服器的外網IP,這樣無論broker或者Client都連線你的外網IP;
也可以自己配置一個
hostname,比如叫kafka1.host;- 在伺服器的
/etc/hosts中配置:內網IP kafka1.host; - 在內網其它伺服器
/etc/hosts中配置:內網IP kafka1.host; - 在外部所有客戶端配置:
外網IP kafka1.host;
- 在伺服器的
其次是系統防火牆
在CentOS7中,可以關閉、也可以將
TCP 9092埠開放(推薦):systemctl status firewalld // 檢視狀態 systemctl stop firewalld // 停用 systemctl start firewalld // 啟動 firewall-cmd --zone=public --list-ports // 檢視所有允許的埠 firewall-cmd --zone=public --add-port=9092/tcp --permanent // 新增TCP的9092埠 firewall-cmd --reload // 過載
3. 使用
可以看官方的快速開始:http://kafka.apache.org/quickstart,有簡單的建立Topic、生產訊息、消費訊息的過程;(直接執行指令碼不加引數可以看到help,如果使用--help有些指令碼是不支援的)
Topic
建立Topic:
bin/kafka-topics.sh --create --topic TestTopic003 --partitions 3 --replication-factor 3 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181檢視所有Topic:
bin/kafka-topics.sh --list --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181分析具體Topic:
bin/kafka-topics.sh --describe --topic TestTopic003 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181刪除某個Topic(在
delete.topic.enable=true情況下才是物理刪除):bin/kafka-topics.sh --delete --topic TestTopic003 --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181刪除某個Topic - 手動方式:刪除所有kafka節點下
${log.dir}目錄下TestTopic003-*的所有目錄;登入zookeeper 客戶端後操作刪除主題的元資料,包括/brokers/topics/TestTopic003和/config/topics/TestTopic003。生產者-傳送訊息
# 傳送時重要的是指定要往哪些broker上發(broker可以同屬一個叢集也可以不是,這樣你就可以發到多個叢集上) bin/kafka-console-producer.sh --topic TestTopic003 --broker-list kafka1.host:9092,kafka2.host:9092,kafka3.host:9092 This is a message This is another message消費者-消費
官網中說從
0.9.0.0開始引入了新的配置方式,我看起來最重要的就是取消了zookeeper,所以官網上的消費例項這樣寫:bin/kafka-console-consumer.sh --topic TestTopic003 --from-beginning --bootstrap-server kafka1.host:9092,kafka2.host:9092,kafka3.host:9092 This is a message This is another message如果是舊版本的Kakfa則使用如下配置去訂閱消費:
bin/kafka-console-consumer.sh --topic TestTopic003 --from-beginning --zookeeper zookeeper1.host:2181,zookeeper2.host:2181,zookeeper3.host:2181 // 會輸出如下提示 Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
4. zookeeper中 – 僅用於瞭解
Kafka會在Zookeeper中建立和使用的目錄如下:
- admin
- cluster
- config
- consumers
- controller
- controller_epoch
- isr_change_notification
/brokers
ids
your broker id 1your broker id 2- …
your broker id N
topics
topic your created 1topic your created 2- …
topic your created N__consumer_offsets
partitions
<num><num>
state
seqid
三、Java例項
引入客戶端jar包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>生產者 - Producer
其實直接使用
org.apache.kafka.clients.producer.KafkaProducer的類註釋部分即可:public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "你的伺服器地址們"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 1; i < 5; i++) { producer.send(new ProducerRecord<String, String>("TestTopic001", Integer.toString(i))); } producer.close(); }消費者 - Consumer
也是直接使用
org.apache.kafka.clients.consumer.KafkaConsumer的類註釋部分即可:public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "你的伺服器地址們"); props.put("group.id", "自己起個唯一的組名"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("TestTopic001")); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } } }
更詳細的Java使用例項,需要大家在實際情況下再自己拓展了,這裡我只說到這了。
相關推薦
Apache Kafka 簡介與使用
Kafka 可以簡單理解為分散式MQ,用Scala編寫,執行在JVM上。 分散式程式,除了其自身的基本概念外,最重要的就是要知道它是如何實現高併發和高可用的: Kafka 用 Partitions 實現了高併發; Kafka 用 Partitions 複製
DataPipeline |Apache Kafka實戰作者胡夕:Apache Kafka監控與調優
推出 充足 不足 交互 進入 時間片 第一條 小時 send 胡夕,《Apache Kafka實戰》作者,北航計算機碩士畢業,現任某互金公司計算平臺總監,曾就職於IBM、搜狗、微博等公司。國內活躍的Kafka代碼貢獻者。 前言雖然目前Apache Kafka已經全面進化成
[Kafka] Apache Kafka 簡介、叢集搭建及配置詳解
前言 kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。這種動作(網頁瀏覽,搜尋和其他使用者的行動)是在現代網路上的許多社會功能的一個關鍵因素。這些資料通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 Kafk
Apache kafka簡介
在 第一個挑戰是如何收集大量的資料,第二個挑戰是分析收集的資料。為了克服這些挑戰,你必須需要一個訊息系統。 kafka專門分散式高吞吐量系統而設計。kafka往往工作的很好,作為一個更傳統的訊息代理的替代品。與其他訊息傳遞系統相比,kafka具有更好的吞吐量,內建分割槽,複製和固有的容錯能力
Apache kafka原理與特性(0.8V)
前言: kafka是一個輕量級的/分散式的/具備replication能力的日誌採集元件,通常被整合到應用系統中,收集"使用者行為日誌"等,並可以使用各種消費終端(consumer)將訊息轉存到HDFS等其他結構化資料儲存系統中.因為日誌訊息通常為文字資料,尺寸較小,且對
Apache Kafka -7 與Storm整合
Apache Kafka教程 之 與Storm整合 Apache Kafka - 與Storm整合 關於Storm Storm最初是由Nathan Marz和BackType建立的。在短時間內,Apache Storm成為分散式實時
Apache Camel簡介與入門
基礎 Apache Camel十一個Java庫和引擎,有多種不同的整合模式,然而他並不是BPMN或者ESB,雖然可以在此引擎下實現他們。Apache Camel是一個程式設計人員調節、整合問題的工具。 Message org.apache.camel
Apache Kafka 0.11版本新功能簡介
多個 spa 實現 cer true assign 線程 cto headers Apache Kafka近日推出0.11版本。這是一個裏程碑式的大版本,特別是Kafka從這個版本開始支持“exactly-once”語義(下稱EOS, exactly-once semant
RabbitMQ VS Apache Kafka (九)—— RabbitMQ叢集的分割槽容錯性與高可用性
本章,我們討論有關RabbitMQ的容錯性,訊息一致性及高可用性。RabbitMQ可以作為叢集節點來執行,因此RabbitMQ通常被歸為分散式訊息系統,對於分散式訊息系統,我們的關注點通常是一致性與可用性。 我們為什麼要討論分散式系統的一致性與可用性,本質在於兩者描述的是系統在失敗的
Kafka安裝與簡介
今天來講一下Kafka,它是一個訊息佇列,應用場景比較廣泛。剛開始學習一門東西,咱們先不管它是幹什麼的,先跑起來才是正經,所以本文主要講兩點: 安裝搭建Kafka 簡單介紹下Kafka的原理和應用 1. 安裝Kafka 1.1 下載解壓
Kafka簡介、基本原理、執行流程與使用場景
一、簡介 Apache Kafka是分散式釋出-訂閱訊息系統,在 kafka官網上對 kafka 的定義:一個分散式釋出-訂閱訊息傳遞系統。 它最初由LinkedIn公司開發,Linkedin於2010年貢獻給了Apache基金會併成為頂級開源專案。Kafka
Spring 對Apache Kafka的支援與整合
## 1. 引言 Apache Kafka 是一個分散式的、容錯的流處理系統。在本文中,我們將介紹Spring對Apache Kafka的支援,以及原生Kafka Java客戶端Api 所提供的抽象級別。 Spring Kafka 通過 *@KafkaListener* 註解,帶來了一個簡單而典型的 Sp
apache kafka源碼project環境搭建(IDEA)
name env check 轉載 2.2.0 var 10.9 環境 con 1.gradle安裝 gradle安裝 2.下載apache kafka源碼 apache kafka下載 3.用gradle構建產生IDEAproject文件 先裝好idea的sc
python學習篇:python簡介與入門
1-1 一行代碼 組合 python代碼 index python語言 cmd https turn 簡介與特點 python語言是由Guido van Rossum在1989年開發的,並最終於1991年初發表。 python是一種面向對象、解釋型的計算機語言,語法簡潔清
webpack簡介與使用
模塊名 code 字符串 mips 不同 分割 pub ref asc 歡迎小夥伴們為 前端導航倉庫 點star https://github.com/pfan123/fr...前端導航平臺訪問 CommonJS 和 AMD 是用於 JavaScript 模塊管理的兩大規範
nagios簡介與原理
nagios簡介與原理1.Nagios簡介1.與cacti的區別a) Cacti1.Cacti比較著重於直觀數據的監控,易於生成圖形,用來監控網絡流量、cpu使用率、硬盤使用率等可以說很在合適不過2.通過SNMP監控數據3.展示工具4.用插件來增加模塊做監控b) nagios 1.比較註重於主機和服務的監控,
zabbix簡介與工作原理
zabbix簡介與工作原理註;如有雷同純屬巧合。1.zabbix簡介zabbix(音同 zbix)是一個基於WEB界面的提供分布式系統監視以及網絡監視功能的企業級的開源解決方案zabbix能監視各種網絡參數,保證服務器系統的安全運營;並提供靈活的通知機制以讓系統管理員快速定位/解決存在的各種問題。zabbix
apache kafka監控系列-KafkaOffsetMonitor
lan Kafka集群 解釋 water zabbix xxx order avi download apache kafka中國社區QQ群:162272557 概覽 近期kafka server消息服務上線了,基於jmx指標參數也寫到zabbix中了。
Servlet簡介與Servlet和HttpServlet運行的流程
別名 文件 port eth cte 通信 訪問 進制 cnblogs 1.Servlet [1] Servlet簡介 > Server + let > 意為:運行在服務器端的小程序。 >
struts2學習(7)值棧簡介與OGNL引入
ride tag per 集合 round del ram exception new 一、值棧簡介: 二、OGNL引入: com.cy.action.HelloAction.java: package com.cy.action; import java.util