
爬蟲爬取動態網頁下載美女圖片
阿新 • • 發佈:2019-02-06
scrapy爬取動態網頁下載圖片
靜態頁面練習了後,我們開始來爬取動態頁面,為了滿足廣大程式猿的需求,在這裡就選擇360圖片吧,網址是image.so.com。希望大家學會後身體一天不如一天。
首先我們來分析這個網頁,開啟開發者工具,滑動頁面等加載出新的圖片後,找到如下連結: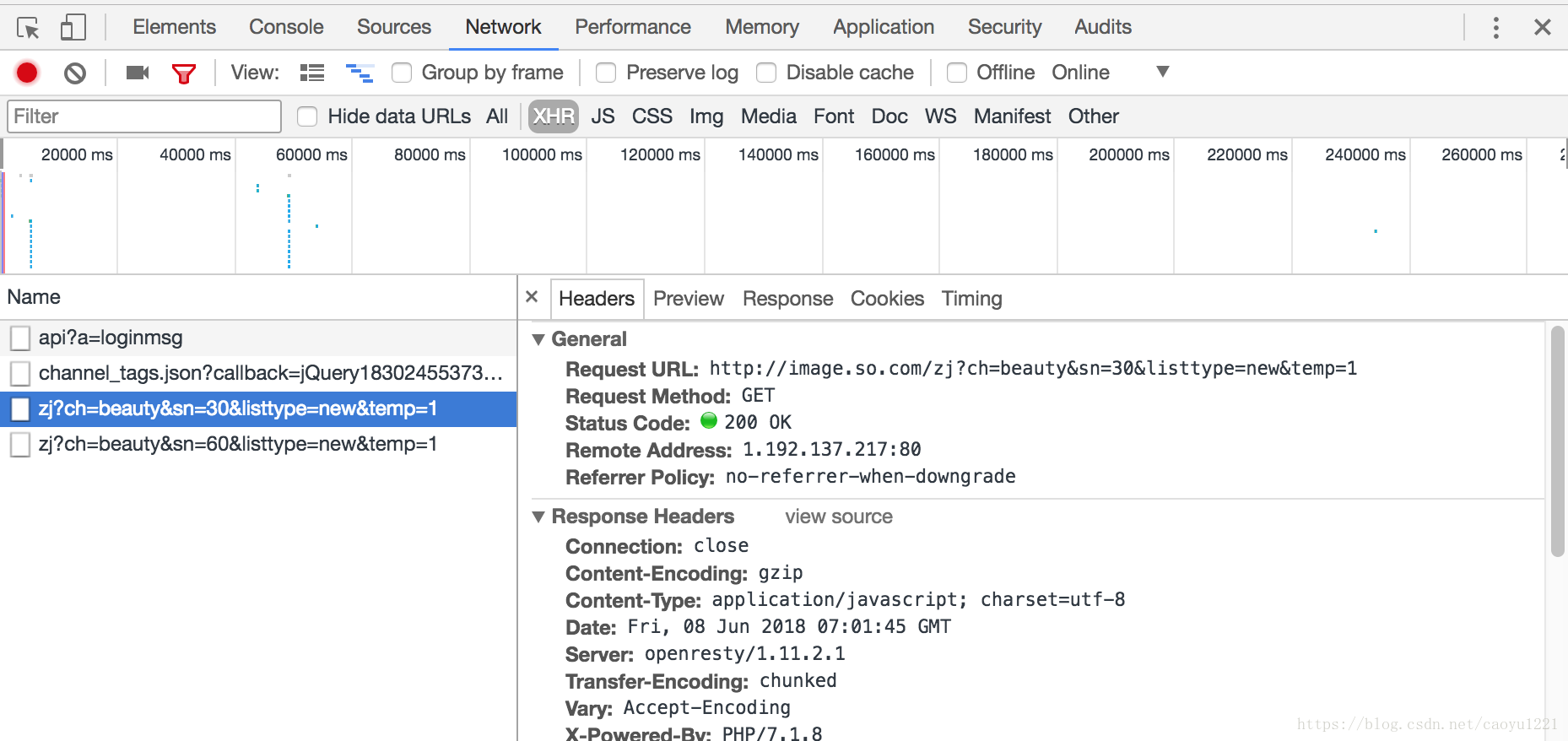
我們可以看到Request URL, 開啟併到runoob.com線上解析工具解析出來,解析後我們可以看到如下的json資料: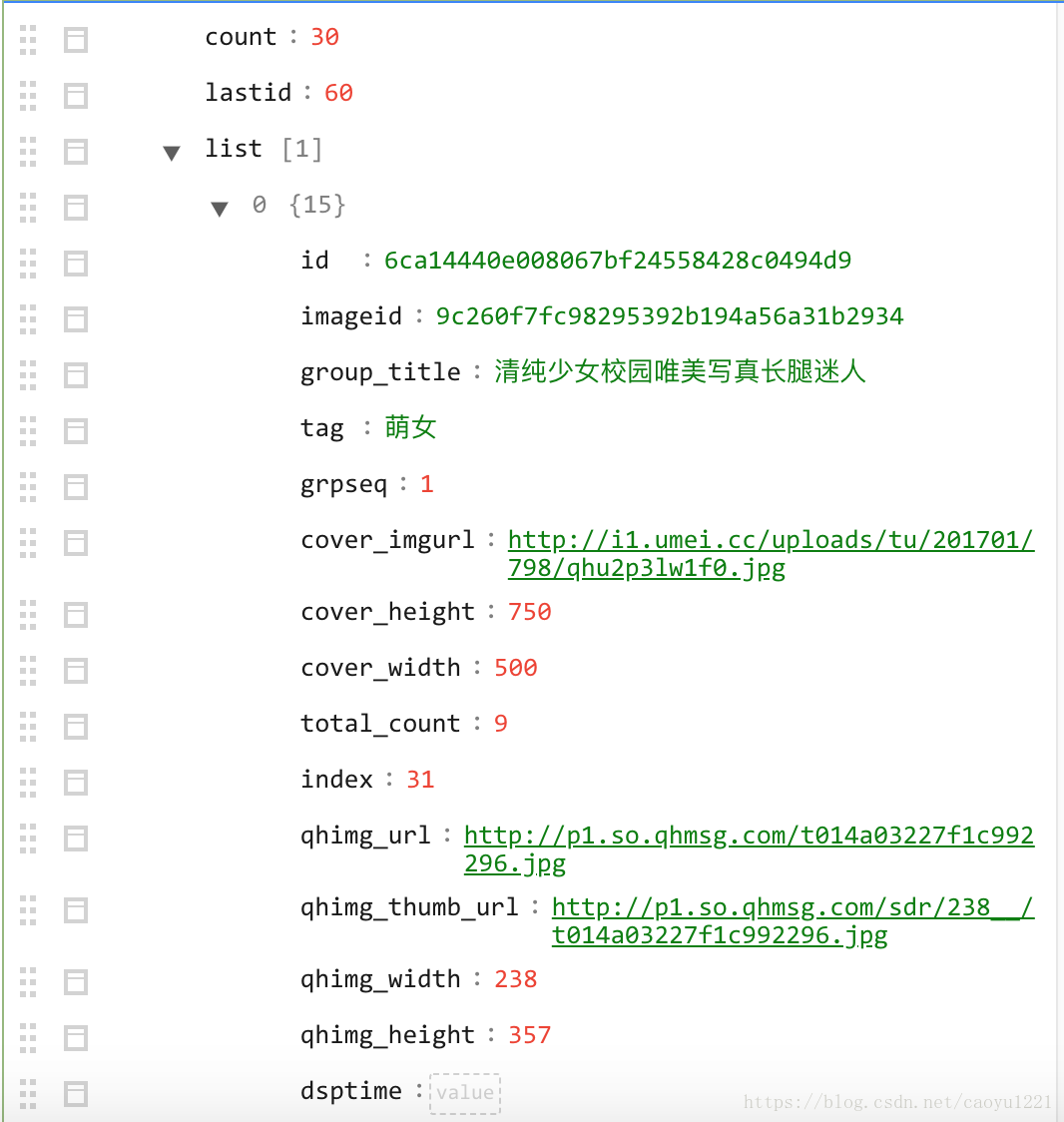
接下來就建立project,開始爬取我們想要的圖片, 首先還是在item.py裡面設定我們需要的:
import image.py
import scrapy
from json import loads
from setting.py
BOT_NAME = 'image360'
SPIDER_MODULES = ['image360.spiders']
NEWSPIDER_MODULE = 'image360.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
# 檔案存取,存在當前路徑下resources目錄
IMAGES_STORE = './resources'
ITEM_PIPELINES = {
'image360.pipelines.SaveImagePipeline': 300,
'image360.pipelines.SaveToMongoPipeline': 301,
}到這裡,我們的爬蟲就可以開始跑了。接下來我們開始完成我們的資料持久化的部分。
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class SaveImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 返回requests
yield Request(url=item['url'])
def item_completed(self, results, item, info):
# 下完檔案後, 給一個results,返回處理結果
# 傳了一個item,所以這個列表只有一個值,而這個值是個元組,我們需要通過results來判斷是否下載成功
if not results[0][0]:
raise DropItem('下載失敗')
return item
def file_path(self, request, response=None, info=None):
# 拿到檔名
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
def process_item(self, item, spider):
# 把資料持久化到 mongo
return item現在開始執行程式,可以在resources路徑下可以看到下載的圖片:
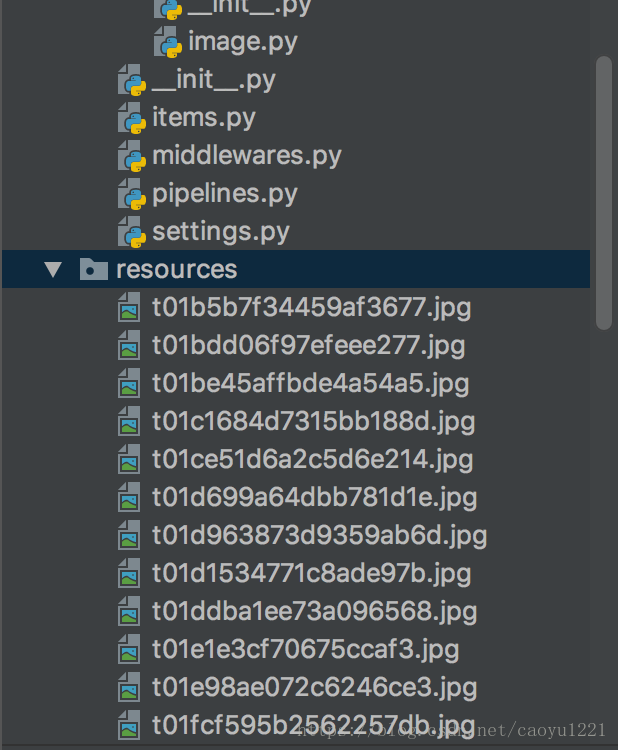
如果想提高一下逼格,寫個日誌,我們可以接著寫下去,首先匯入logging這個模組,如果想在下載的時候列印日誌,只需要在item_completed裡面加入logger.debug('圖片下載完成!')。
現在就可以盡情的開始欣賞下載的圖片了,大家學會後還是要注意節制,畢竟檣櫓灰飛煙滅啊!