
BP(反向傳播)演算法
最近在看深度學習的東西,一開始看的吳恩達的UFLDL教程,有中文版就直接看了,後來發現有些地方總是不是很明確,又去看英文版,然後又找了些資料看,才發現,中文版的譯者在翻譯的時候會對省略的公式推導過程進行補充,但是補充的又是錯的,難怪覺得有問題。反向傳播法其實是神經網路的基礎了,但是很多人在學的時候總是會遇到一些問題,或者看到大篇的公式覺得好像很難就退縮了,其實不難,就是一個鏈式求導法則反覆用。如果不想看公式,可以直接把數值帶進去,實際的計算一下,體會一下這個過程之後再來推導公式,這樣就會覺得很容易了。
說到神經網路,大家看到這個圖應該不陌生:
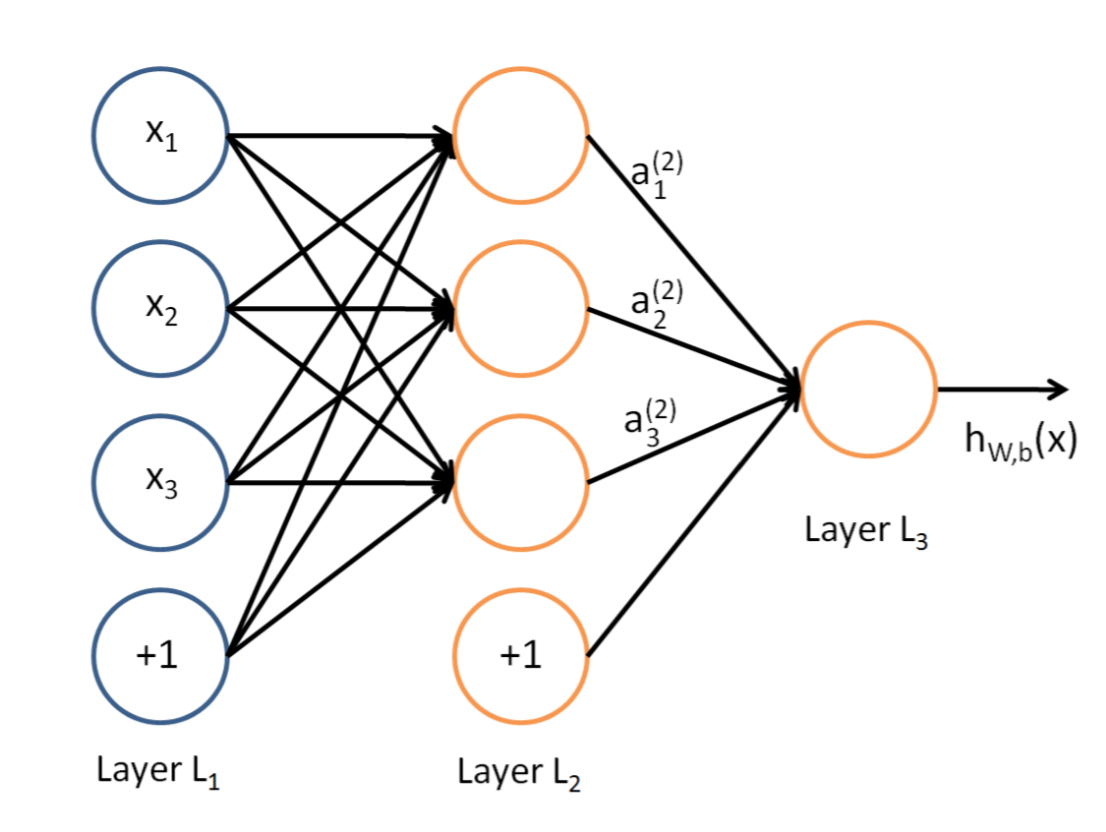
這是典型的三層神經網路的基本構成,Layer L1是輸入層,Layer L2是隱含層,Layer L3是隱含層,我們現在手裡有一堆資料{x1,x2,x3,…,xn},輸出也是一堆資料{y1,y2,y3,…,yn},現在要他們在隱含層做某種變換,讓你把資料灌進去後得到你期望的輸出。如果你希望你的輸出和原始輸入一樣,那麼就是最常見的自編碼模型(Auto-Encoder)。可能有人會問,為什麼要輸入輸出都一樣呢?有什麼用啊?其實應用挺廣的,在影象識別,文字分類等等都會用到,我會專門再寫一篇Auto-Encoder的文章來說明,包括一些變種之類的。如果你的輸出和原始輸入不一樣,那麼就是很常見的人工神經網路了,相當於讓原始資料通過一個對映來得到我們想要的輸出資料,也就是我們今天要講的話題。
本文直接舉一個例子,帶入數值演示反向傳播法的過程,公式的推導等到下次寫Auto-Encoder的時候再寫,其實也很簡單,感興趣的同學可以自己推導下試試:)(注:本文假設你已經懂得基本的神經網路構成,如果完全不懂,可以參考Poll寫的筆記:[Mechine Learning & Algorithm] 神經網路基礎)
假設,你有這樣一個網路層:

第一層是輸入層,包含兩個神經元i1,i2,和截距項b1;第二層是隱含層,包含兩個神經元h1,h2和截距項b2,第三層是輸出o1,o2,每條線上標的wi是層與層之間連線的權重,啟用函式我們預設為sigmoid函式。
現在對他們賦上初值,如下圖:
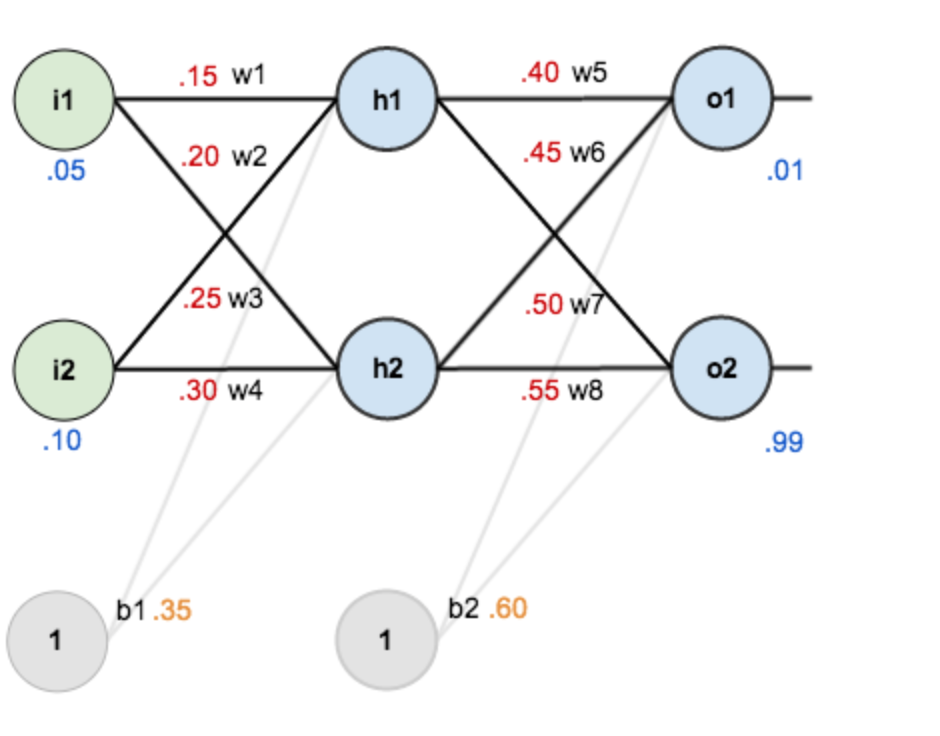
其中,輸入資料 i1=0.05,i2=0.10;
輸出資料 o1=0.01,o2=0.99;
初始權重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目標:給出輸入資料i1,i2(0.05和0.10),使輸出儘可能與原始輸出o1,o2(0.01和0.99)接近。
Step 1 前向傳播
1.輸入層—->隱含層:
計算神經元h1的輸入加權和:

神經元h1的輸出o1:(此處用到啟用函式為sigmoid函式):
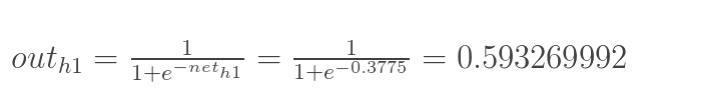
同理,可計算出神經元h2的輸出o2:
![]()
2.隱含層—->輸出層:
計算輸出層神經元o1和o2的值:

![]()
這樣前向傳播的過程就結束了,我們得到輸出值為[0.75136079 , 0.772928465],與實際值[0.01 , 0.99]相差還很遠,現在我們對誤差進行反向傳播,更新權值,重新計算輸出。
Step 2 反向傳播
1.計算總誤差
總誤差:(square error)
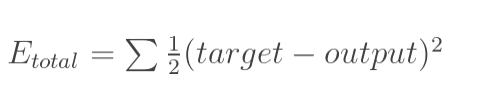
但是有兩個輸出,所以分別計算o1和o2的誤差,總誤差為兩者之和:


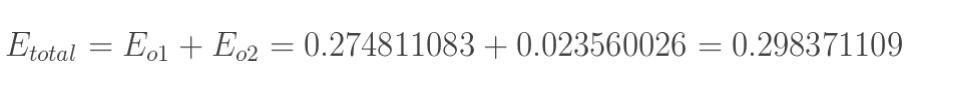
2.隱含層—->輸出層的權值更新:
以權重引數w5為例,如果我們想知道w5對整體誤差產生了多少影響,可以用整體誤差對w5求偏導求出:(鏈式法則)

下面的圖可以更直觀的看清楚誤差是怎樣反向傳播的:

現在我們來分別計算每個式子的值:
計算![]() :
:

計算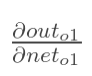 :
:

(這一步實際上就是對sigmoid函式求導,比較簡單,可以自己推導一下)
計算 :
:
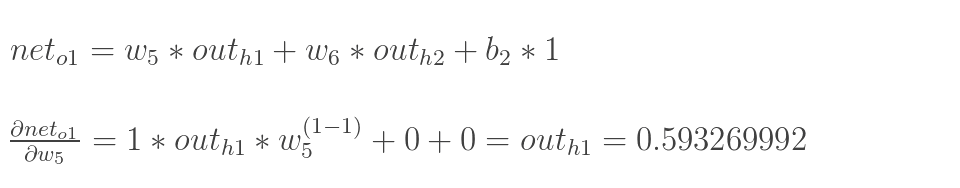
最後三者相乘:

這樣我們就計算出整體誤差E(total)對w5的偏導值。
回過頭來再看看上面的公式,我們發現:

為了表達方便,用![]() 來表示輸出層的誤差:
來表示輸出層的誤差:

因此,整體誤差E(total)對w5的偏導公式可以寫成:

如果輸出層誤差計為負的話,也可以寫成:

最後我們來更新w5的值:
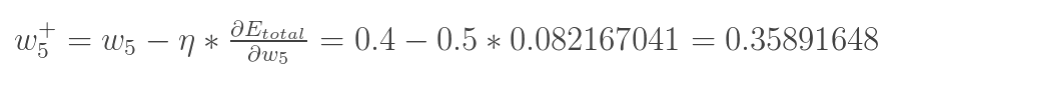
(其中,![]() 是學習速率,這裡我們取0.5)
是學習速率,這裡我們取0.5)
同理,可更新w6,w7,w8:

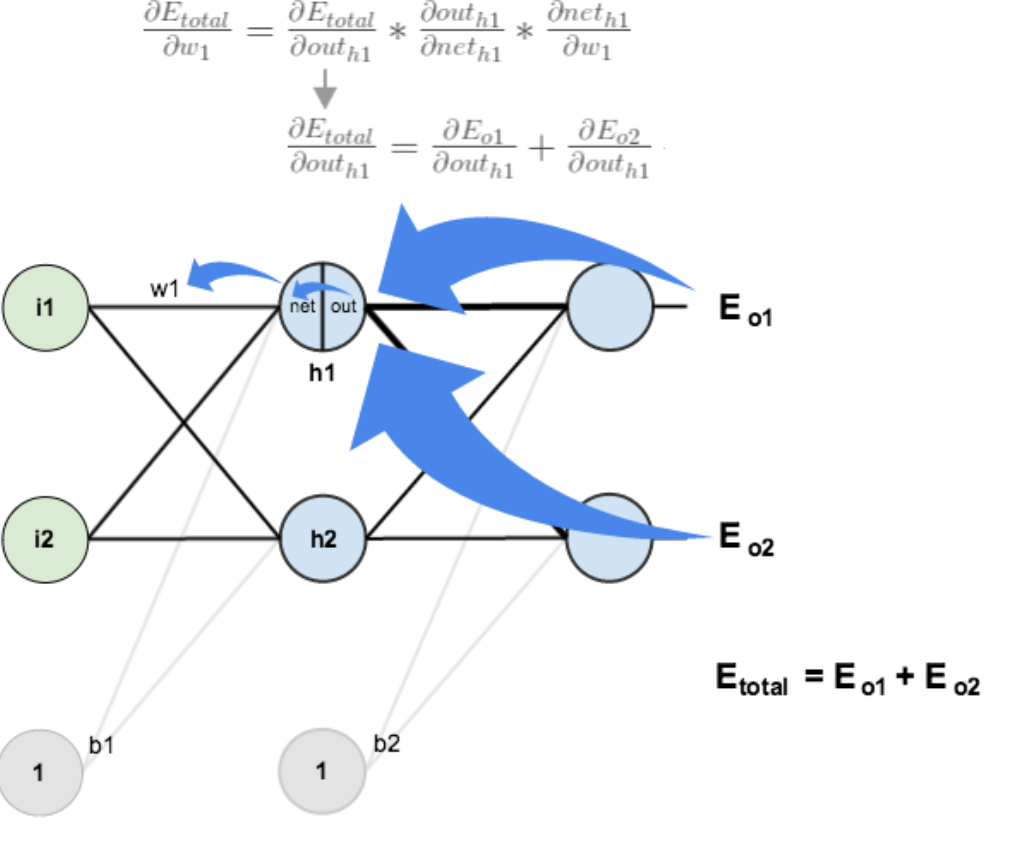
3.隱含層—->隱含層的權值更新:
方法其實與上面說的差不多,但是有個地方需要變一下,在上文計算總誤差對w5的偏導時,是從out(o1)—->net(o1)—->w5,但是在隱含層之間的權值更新時,是out(h1)—->net(h1)—->w1,而out(h1)會接受E(o1)和E(o2)兩個地方傳來的誤差,所以這個地方兩個都要計算。
計算![]() :
:

先計算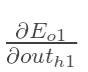 :
:
![]()
![]()
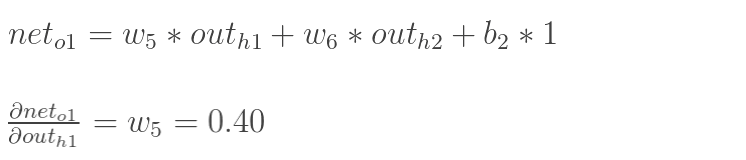
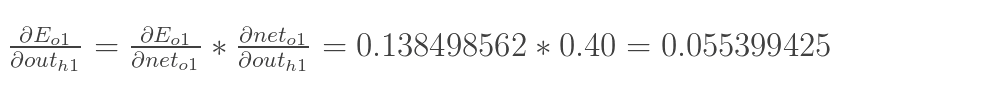
同理,計算出:
![]()
兩者相加得到總值:
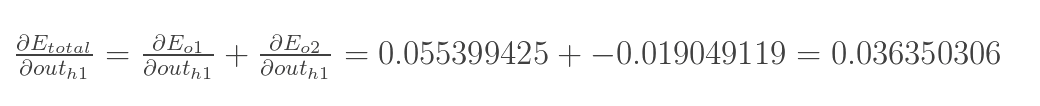
再計算![]() :
:

再計算![]() :
:

最後,三者相乘:

為了簡化公式,用sigma(h1)表示隱含層單元h1的誤差:

最後,更新w1的權值:
![]()
同理,額可更新w2,w3,w4的權值:

這樣誤差反向傳播法就完成了,最後我們再把更新的權值重新計算,不停地迭代,在這個例子中第一次迭代之後,總誤差E(total)由0.298371109下降至0.291027924。迭代10000次後,總誤差為0.000035085,輸出為[0.015912196,0.984065734](原輸入為[0.01,0.99]),證明效果還是不錯的。