
Openblas加速三維矩陣卷積操作
阿新 • • 發佈:2019-02-07
接上個部落格(http://blog.csdn.net/samylee/article/details/73252715)所講,這篇博文介紹如何用openblas加速三維矩陣。
程式碼如下(以下程式經博主測試準確無誤):
標頭檔案function.h
//function.h //cblas加速三維矩陣卷積操作 //注意:stride=1 //作者:samylee #ifndef FUNCTION_H #define FUNCTION_H #include <cblas.h> #include <iostream> using namespace std; //A加pad的計算 void comput_Apad(const int pad_w, const int Map, const int channel, float *A_pad, const float *A); //pad_A的轉換,以適用於Openblas void convertA(float *A_convert, const int outM, const int convAw, const int pad_w, float *A_pad, const int channel); //kernel轉換以適用於openblas void convertB(const int convAw, const int channel, float *B, float *B_convert); //Openblas矩陣乘積計算 void Matrixmul_blas(const int convAh, const int convAw, float *A_convert, float *B_convert, float *C, const int channel); //轉換C為常用矩陣排列 void convertC(const int channel, const int convAh, float *C_convert, float *C); //驗證結果是否正確 void evaluate_blas(const int channel, const int Map, const float *A, const int Kernel, const float *B, const int outM, float *C_convert); #endif // !FUNCTION_H
函式檔案function.cpp
//function.cpp //cblas加速三維矩陣卷積操作 //注意:stride=1 //作者:samylee #include "function.h" //A加pad的計算 void comput_Apad(const int pad_w, const int Map, const int channel, float *A_pad, const float *A) { int pad_one_channel = pad_w*pad_w; int org_one_channel = Map*Map; for (int c = 0; c < channel; c++) { for (int i = 0; i < pad_w; i++) { for (int j = 0; j < pad_w; j++) { int col = c*pad_one_channel + i*pad_w + j; if (i == 0 || i == pad_w - 1) { A_pad[col] = 0; } else { if (j == 0 || j == pad_w - 1) { A_pad[col] = 0; } else { A_pad[col] = A[c*org_one_channel + (i - 1)*Map + j - 1]; } } } } } } //pad_A的轉換,以適用於Openblas void convertA(float *A_convert, const int outM, const int convAw, const int pad_w, float *A_pad, const int channel) { int pad_one_channel = pad_w*pad_w; int seg = channel * convAw; for (int c = 0; c < channel; c++) { for (int i = 0; i < outM; i++) { for (int j = 0; j < outM; j++) { int wh = c*convAw + i * outM * seg + j * seg; int col1 = c*pad_one_channel + i * pad_w + j; A_convert[wh] = A_pad[col1]; A_convert[wh + 1] = A_pad[col1 + 1]; A_convert[wh + 2] = A_pad[col1 + 2]; int col2 = c*pad_one_channel + (i + 1) * pad_w + j; A_convert[wh + 3] = A_pad[col2]; A_convert[wh + 4] = A_pad[col2 + 1]; A_convert[wh + 5] = A_pad[col2 + 2]; int col3 = c*pad_one_channel + (i + 2) * pad_w + j; A_convert[wh + 6] = A_pad[col3]; A_convert[wh + 7] = A_pad[col3 + 1]; A_convert[wh + 8] = A_pad[col3 + 2]; } } } } //kernel轉換以適用於openblas void convertB(const int convAw, const int channel, float *B, float *B_convert) { int block_A_convert = convAw*channel; for (int c = 0; c < channel; c++) { int block = c*block_A_convert; for (int i = 0; i < convAw; i++) { for (int j = 0; j < channel; j++) { if (c == j) { B_convert[block + i*channel + j] = B[c*convAw + i]; } else { B_convert[block + i*channel + j] = 0; } } } } } //Openblas矩陣乘積計算 void Matrixmul_blas(const int convAh, const int convAw, float *A_convert, float *B_convert, float *C, const int channel) { const enum CBLAS_ORDER Order = CblasRowMajor; const enum CBLAS_TRANSPOSE TransA = CblasNoTrans; const enum CBLAS_TRANSPOSE TransB = CblasNoTrans; const int M = convAh;//A的行數,C的行數 const int N = channel;//B的列數,C的列數 const int K = convAw * channel;//A的列數,B的行數 const float alpha = 1; const float beta = 0; const int lda = K;//A的列 const int ldb = N;//B的列 const int ldc = N;//C的列 cblas_sgemm(Order, TransA, TransB, M, N, K, alpha, A_convert, lda, B_convert, ldb, beta, C, ldc); } //轉換C為常用矩陣排列 void convertC(const int channel, const int convAh, float *C_convert, float *C) { for (int c = 0; c < channel; c++) { for (int i = 0; i < convAh; i++) { C_convert[c*convAh + i] = C[i*channel + c]; } } } //驗證結果是否正確 void evaluate_blas(const int channel, const int Map, const float *A, const int Kernel, const float *B, const int outM, float *C_convert) { cout << "A is:" << endl; for (int c = 0; c < channel; c++) { for (int i = 0; i < Map; i++) { for (int j = 0; j < Map; j++) { cout << A[c*Map*Map + i*Map + j] << " "; } cout << endl; } cout << endl; } cout << "B is:" << endl; for (int c = 0; c < channel; c++) { for (int i = 0; i < Kernel; i++) { for (int j = 0; j < Kernel; j++) { cout << B[c * Kernel * Kernel + i*Kernel + j] << " "; } cout << endl; } cout << endl; } cout << "C is:" << endl; for (int c = 0; c < channel; c++) { for (int i = 0; i < outM; i++) { for (int j = 0; j < outM; j++) { cout << C_convert[c * outM * outM + i*outM + j] << " "; } cout << endl; } cout << endl; } }
主函式檔案main.cpp
//main.cpp //cblas加速三維矩陣卷積操作 //注意:stride=1 //作者:samylee #include "function.h" int main() { //卷積引數初始化 const int pad = 1; const int stride = 1; //定義被卷積三維矩陣 const int Map = 4; const int channel = 3; const float A[Map * Map * channel] = { 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,2,3,4 }; //定義三維卷積核 const int Kernel = 3; float B[Kernel * Kernel * channel] = { 1,1,1, 1,1,1, 1,1,1, 2,2,2, 2,2,2, 2,2,2, 3,3,3, 3,3,3, 3,3,3 }; //計算卷積輸出矩陣寬高 const int outM = (Map - Kernel + 2 * pad) / stride + 1; //計算三維pad_A const int pad_w = Map + 2 * pad; float A_pad[pad_w*pad_w*channel]; comput_Apad(pad_w, Map, channel, A_pad, A); //定義被卷積矩陣寬高 const int convAw = Kernel*Kernel; const int convAh = outM*outM; //轉換被卷積矩陣 float A_convert[convAh*convAw*channel]; convertA(A_convert, outM, convAw, pad_w, A_pad, channel); //轉換卷積核以適用於cblas float B_convert[channel * Kernel * Kernel * channel]; convertB(convAw, channel, B, B_convert); //定義卷積輸出矩陣 float C[convAh * channel]; //cblas計算輸出矩陣 Matrixmul_blas(convAh, convAw, A_convert, B_convert, C, channel); //將輸出轉換為常用矩陣形式 float C_convert[outM * outM * channel]; convertC(channel, convAh, C_convert, C); //輸出驗證 evaluate_blas(channel, Map, A, Kernel, B, outM, C_convert); system("pause"); return EXIT_SUCCESS; }
效果如下:
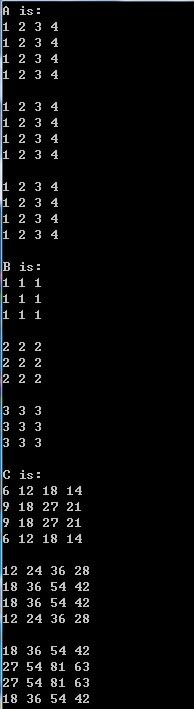
任何問題請加唯一QQ2258205918(名稱samylee)!