
場景文字識別Sliding Convolution筆記
方法優勢:
(1)相對於基於先分割再識別的方法,該方法避免了複雜的字元分割過程。
(2)避免了rnn訓練過程中的梯度消失和梯度爆炸的問題,使得訓練過程比較容易
(3)相對於基於單詞識別的方法,該基於字元識別的方法可以識別基於單詞的方法不能識別的單詞
(4)識別過程可以高度並行化
整體識別流程圖:
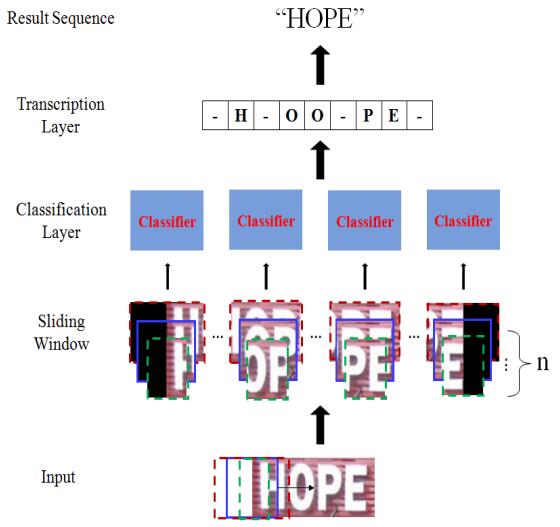
首先對輸入圖片進行overlap型的滑動視窗掃描(英文:步長step為4,視窗大小為32*32,中文:步長step為8,視窗大小為32*40)。並且將整個的輸入圖片按照視窗大小切割出來。然後將所有切割出的圖片按照batch方向輸入神經網路。神經網路會輸出分類後的結果。然後Transcription Layer將這些分類結果按照順序合併起來,然後送入
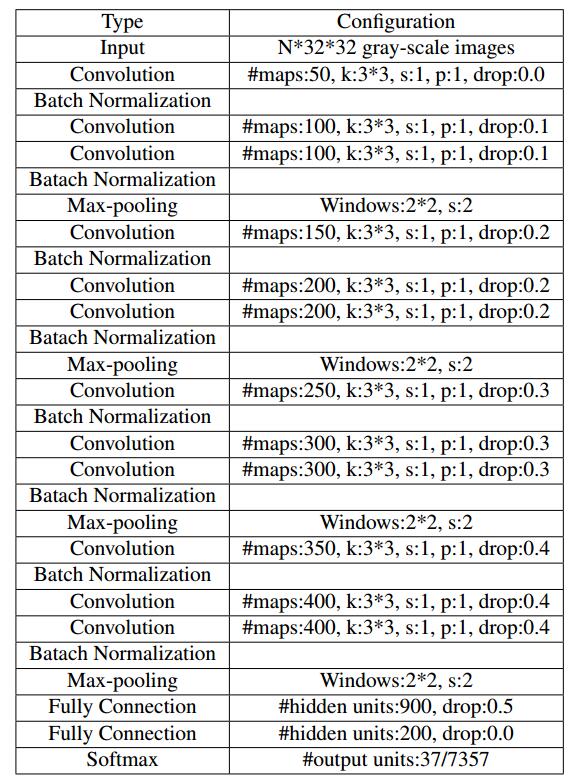
網路結構:
其中,k,s,p分別代表卷積核大小,滑動步長,padding大小
和crnn的對比:
crnn是白翔老師的那篇文章。和這篇文章有異曲同工之處。
(1)crnn整體結構為CNN+RNN+CTC的結構,這篇Sliding Convolution結構為CNN+CTC結構。(2)Sliding Convolution文章對於輸入的圖片做了切割,然後切割好的圖片可以跑batch,然後得出每個分割圖片的識別結果。而crnn是一行文字圖片直接輸入,從處理時間上看,沒有Sliding Convolution更加效率。
(2)Sliding Convolution文章的結構使用了全連線層,輸入圖片大小被固定為
自己的一些想法:
(1)Sliding Convolution文章的網路結構,最後的2個全連線層可以換為1*1卷積層,或者RNN。
(2)通過Sliding Convolution文章中跑batch的思想,對於crnn,也可以將輸入圖片平均切分成幾份。然後走batch。注意這裡只走cnn的batch。cnn跑完後,做一個batch方向的concat。然後輸入rnn+ctc。同樣可以實現batch思想的加速。同時對訓練過程不會有影響,還是使用原始的訓練就可以,而測試程式,只需要再cnn之後加個concat操作既可。
這裡我自己修改的程式是使用的reshape操作實現的。由於我這裡是對輸入圖片平均切分的。所以切的份數太多,識別效果會有影響。切的份數越多加速越明顯,但是加速比不是很明顯。只有微量的加速。
CTC基礎建議看這篇:
自己的實現: