
無向圖的遍歷(BFS+DFS,MATLAB)
廣度/寬度優先搜尋(BFS)
【演算法入門】
1.前言
廣度優先搜尋(也稱寬度優先搜尋,縮寫BFS,以下采用廣度來描述)是連通圖的一種遍歷策略。因為它的思想是從一個頂點V0開始,輻射狀地優先遍歷其周圍較廣的區域,故得名。
一般可以用它做什麼呢?一個最直觀經典的例子就是走迷宮,我們從起點開始,找出到終點的最短路程,很多最短路徑演算法就是基於廣度優先的思想成立的。
演算法導論裡邊會給出不少嚴格的證明,我想盡量寫得通俗一點,因此採用一些直觀的講法來偽裝成證明,關鍵的point能夠幫你get到就好。
2.圖的概念
剛剛說的廣度優先搜尋是連通圖的一種遍歷策略,那就有必要將圖先簡單解釋一下。
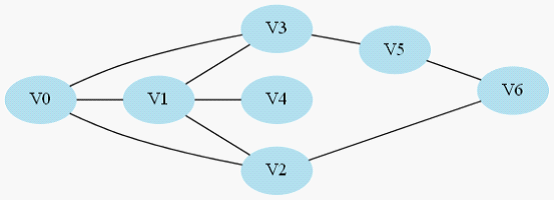
圖2-1
如圖2-1所示,這就是我們所說的連通圖,這裡展示的是一個無向圖,連通即每2個點都有至少一條路徑相連,例如V0到V4的路徑就是V0->V1->V4。
一般我們把頂點用V縮寫,把邊用E縮寫。
3.廣度優先搜尋
3.1.演算法的基本思路
常常我們有這樣一個問題,從一個起點開始要到一個終點,我們要找尋一條最短的路徑,從圖2-1舉例,如果我們要求V0到V6的一條最短路(假設走一個節點按一步來算)【注意:此處你可以選擇不看這段文字直接看圖3-1】,我們明顯看出這條路徑就是V0->V2->V6,而不是V0->V3->V5->V6。先想想你自己剛剛是怎麼找到這條路徑的:首先看跟V
你會看到這裡有點像輻射形狀的搜尋方式,從一個節點,向其旁邊節點傳遞病毒,就這樣一層一層的傳遞輻射下去,知道目標節點被輻射中了,此時就已經找到了從起點到終點的路徑。
我們採用示例圖來說明這個過程,在搜尋的過程中,初始所有節點是白色(代表了所有點都還沒開始搜尋),把起點V0標誌成灰色(表示即將輻射V0),下一步搜尋的時候,我們把所有的灰色節點訪問一次,然後將其變成黑色(表示已經被輻射過了),進而再將他們所能到達的節點標誌成灰色(因為那些節點是下一步搜尋的目標點了),但是這裡有個判斷,就像剛剛的例子,當訪問到V1節點的時候,它的下一個節點應該是V0和V4,但是V0已經在前面被染成黑色了,所以不會將它染灰色。這樣持續下去,直到目標節點V6被染灰色,說明了下一步就到終點了,沒必要再搜尋(染色)其他節點了,此時可以結束搜尋了,整個搜尋就結束了。然後根據搜尋過程,反過來把最短路徑找出來,圖3-1中把最終路徑上的節點標誌成綠色。
整個過程的例項圖如圖3-1所示。
 初始全部都是白色(未訪問)
初始全部都是白色(未訪問)
 即將搜尋起點V0(灰色)
即將搜尋起點V0(灰色)
 已搜尋V0,即將搜尋V1、V2、V3
已搜尋V0,即將搜尋V1、V2、V3
 ……終點V6被染灰色,終止
……終點V6被染灰色,終止
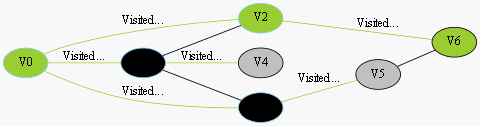 找到最短路徑
找到最短路徑
圖3-1 尋找V0到V6的過程
3.2.廣度優先搜尋流程圖
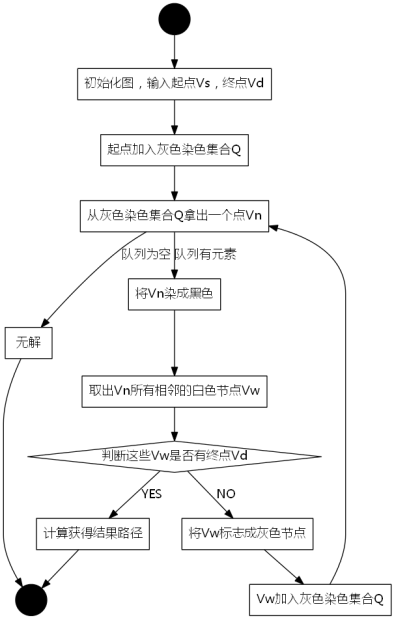
圖3-2 廣度優先搜尋的流程圖
在寫具體程式碼之前有必要先舉個例項,詳見第4節。
4.例項
第一節就講過廣度優先搜尋適用於迷宮類問題,這裡先給出POJ3984《迷宮問題》。
《迷宮問題》
定義一個二維陣列:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一個迷宮,其中的1表示牆壁,0表示可以走的路,只能橫著走或豎著走,不能斜著走,要求程式設計序找出從左上角到右下角的最短路線。
題目保證了輸入是一定有解的。
也許你會問,這個跟廣度優先搜尋的圖怎麼對應起來?BFS的第一步就是要識別圖的節點跟邊!
4.1.識別出節點跟邊
節點就是某種狀態,邊就是節點與節點間的某種規則。
對應於《迷宮問題》,你可以這麼認為,節點就是迷宮路上的每一個格子(非牆),走迷宮的時候,格子間的關係是什麼呢?按照題目意思,我們只能橫豎走,因此我們可以這樣看,格子與它橫豎方向上的格子是有連通關係的,只要這個格子跟另一個格子是連通的,那麼兩個格子節點間就有一條邊。
如果說本題再修改成斜方向也可以走的話,那麼就是格子跟周圍8個格子都可以連通,於是一個節點就會有8條邊(除了邊界的節點)。
4.2.解題思路
對應於題目的輸入陣列:
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
我們把節點定義為(x,y),(x,y)表示陣列maze的項maze[x][y]。
於是起點就是(0,0),終點是(4,4)。按照剛剛的思路,我們大概手工梳理一遍:
初始條件:
起點Vs為(0,0)
終點Vd為(4,4)
灰色節點集合Q={}
初始化所有節點為白色節點
開始我們的廣度搜索!
手工執行步驟【PS:你可以直接看圖4-1】:
1.起始節點Vs變成灰色,加入佇列Q,Q={(0,0)}
2.取出佇列Q的頭一個節點Vn,Vn={0,0},Q={}
3.把Vn={0,0}染成黑色,取出Vn所有相鄰的白色節點{(1,0)}
4.不包含終點(4,4),染成灰色,加入佇列Q,Q={(1,0)}
5.取出佇列Q的頭一個節點Vn,Vn={1,0},Q={}
6.把Vn={1,0}染成黑色,取出Vn所有相鄰的白色節點{(2,0)}
7.不包含終點(4,4),染成灰色,加入佇列Q,Q={(2,0)}
8.取出佇列Q的頭一個節點Vn,Vn={2,0},Q={}
9.把Vn={2,0}染成黑色,取出Vn所有相鄰的白色節點{(2,1), (3,0)}
10.不包含終點(4,4),染成灰色,加入佇列Q,Q={(2,1), (3,0)}
11.取出佇列Q的頭一個節點Vn,Vn={2,1},Q={(3,0)}
12. 把Vn={2,1}染成黑色,取出Vn所有相鄰的白色節點{(2,2)}
13.不包含終點(4,4),染成灰色,加入佇列Q,Q={(3,0), (2,2)}
14.持續下去,知道Vn的所有相鄰的白色節點中包含了(4,4)……
15.此時獲得了答案
起始你很容易模仿上邊過程走到終點,那為什麼它就是最短的呢?
怎麼保證呢?
我們來看看廣度搜索的過程中節點的順序情況:

圖4-1 迷宮問題的搜尋樹
你是否觀察到了,廣度搜索的順序是什麼樣子的?
圖中標號即為我們搜尋過程中的順序,我們觀察到,這個搜尋順序是按照上圖的層次關係來的,例如節點(0,0)在第1層,節點(1,0)在第2層,節點(2,0)在第3層,節點(2,1)和節點(3,0)在第3層。
我們的搜尋順序就是第一層->第二層->第三層->第N層這樣子。
我們假設終點在第N層,因此我們搜尋到的路徑長度肯定是N,而且這個N一定是所求最短的。
我們用簡單的反證法來證明:假設終點在第N層上邊出現過,例如第M層,M<N,那麼我們在搜尋的過程中,肯定是先搜尋到第M層的,此時搜尋到第M層的時候發現終點出現過了,那麼最短路徑應該是M,而不是N了。
所以根據廣度優先搜尋的話,搜尋到終點時,該路徑一定是最短的。
6.其他例項
6.1.題目描述
給定序列1 2 3 4 5 6,再給定一個k,我們給出這樣的操作:對於序列,我們可以將其中k個連續的數全部反轉過來,例如k = 3的時候,上述序列經過1步操作後可以變成:3 2 1 4 5 6 ,如果再對序列 3 2 1 4 5 6進行一步操作,可以變成3 4 1 2 5 6.
那麼現在題目就是,給定初始序列,以及結束序列,以及k的值,那麼你能夠求出從初始序列到結束序列的轉變至少需要幾步操作嗎?
6.2.思路
本題可以採用BFS求解,已經給定初始狀態跟目標狀態,要求之間的最短操作,其實也很明顯是用BFS了。
我們把每次操作完的序列當做一個狀態節點。那每一次操作就產生一條邊,這個操作就是規則。
假設起始節點是:{1 2 3 4 5 6},終點是:{3 4 1 2 5 6}
去除佇列中的起始節點時,將它的相鄰節點加入佇列,其相鄰節點就是對其操作一次的所有序列:
{3 2 1 4 5 6}、{1 4 3 2 5 6}、{1 2 5 4 3 6}、{1 2 3 6 5 4}
然後繼續搜尋即可得到終點,此時運算元就是搜尋到的節點所在的層數2。
7.OJ題目
題目分類來自網路:
sicily:1048 1444 1215 1135 1150 1151 1114
pku:1136 1249 1028 1191 3278 1426 3126 3087 3414
8.總結
假設圖有V個頂點,E條邊,廣度優先搜尋演算法需要搜尋V個節點,因此這裡的消耗是O(V),在搜尋過程中,又需要根據邊來增加佇列的長度,於是這裡需要消耗O(E),總得來說,效率大約是O(V+E)。
其實最影響BFS演算法的是在於Hash運算,我們前面給出了一個visit陣列,已經算是最快的Hash了,但有些題目來說可能Hash的速度要退化到O(lgn)的複雜度,當然了,具體還是看實際情況的。
BFS適合此類題目:給定初始狀態跟目標狀態,要求從初始狀態到目標狀態的最短路徑。
9.擴充套件
進而擴充套件的話就是雙向廣度搜索演算法,顧名思義,即是從起點跟終點分別做廣度優先搜尋,直到他們的搜尋過程中有一個節點相同了,於是就找到了起點跟終點的一條路徑。
騰訊筆試題目:假設每個人平均是有25個好友,根據六維理論,任何人之間的聯絡一定可以通過6個人而間接認識,間接通過N個人認識的,那他就是你的N度好友,現在要你程式設計驗證這個6維理論。
此題如果直接做廣度優先搜尋,那麼搜尋的節點數可能達到25^6,如果是用雙向的話,兩個樹分別只需要搜尋到3度好友即可,搜尋節點最多為25^3個,但是用雙向廣度演算法的話會有一個問題要解決,就是你如何在搜尋的過程中判斷第一棵樹中的節點跟第二棵樹中的節點有相同的呢?按我的理解,可以用Hash,又或者放進佇列的元素都是指向原來節點的指標,而每個節點加入一個color的屬性,這樣再搜尋過程中就可以根據節點的color來判斷是否已經被搜尋過了。
深度優先搜尋(DFS)
【演算法入門】
1.前言
深度優先搜尋(縮寫DFS)有點類似廣度優先搜尋,也是對一個連通圖進行遍歷的演算法。它的思想是從一個頂點V0開始,沿著一條路一直走到底,如果發現不能到達目標解,那就返回到上一個節點,然後從另一條路開始走到底,這種儘量往深處走的概念即是深度優先的概念。
你可以跳過第二節先看第三節,:)
2.深度優先搜尋VS廣度優先搜尋
2.1演示深度優先搜尋的過程
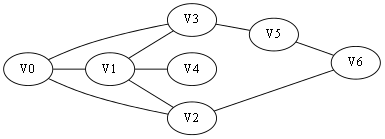
還是引用上篇文章的樣例圖,起點仍然是V0,我們修改一下題目意思,只需要讓你找出一條V0到V6的道路,而無需最短路。
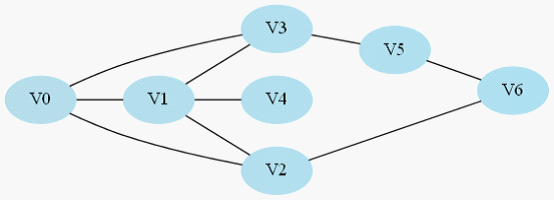
圖2-1 尋找V0到V6的一條路(無需最短路徑)
假設按照以下的順序來搜尋:
1.V0->V1->V4,此時到底盡頭,仍然到不了V6,於是原路返回到V1去搜索其他路徑;
2.返回到V1後既搜尋V2,於是搜尋路徑是V0->V1->V2->V6,,找到目標節點,返回有解。
這樣搜尋只是2步就到達了,但是如果用BFS的話就需要多幾步。
2.2深度與廣度的比較
(你可以跳過這一節先看第三節,重點在第三節)
我們假設一個節點衍生出來的相鄰節點平均的個數是N個,那麼當起點開始搜尋的時候,佇列有一個節點,當起點拿出來後,把它相鄰的節點放進去,那麼佇列就有N個節點,當下一層的搜尋中再加入元素到佇列的時候,節點數達到了N2,你可以想想,一旦N是一個比較大的數的時候,這個樹的層次又比較深,那這個佇列就得需要很大的記憶體空間了。
於是廣度優先搜尋的缺點出來了:在樹的層次較深&子節點數較多的情況下,消耗記憶體十分嚴重。廣度優先搜尋適用於節點的子節點數量不多,並且樹的層次不會太深的情況。
那麼深度優先就可以克服這個缺點,因為每次搜的過程,每一層只需維護一個節點。但回過頭想想,廣度優先能夠找到最短路徑,那深度優先能否找到呢?深度優先的方法是一條路走到黑,那顯然無法知道這條路是不是最短的,所以你還得繼續走別的路去判斷是否是最短路?
於是深度優先搜尋的缺點也出來了:難以尋找最優解,僅僅只能尋找有解。其優點就是記憶體消耗小,克服了剛剛說的廣度優先搜尋的缺點。
3.深度優先搜尋
3.1.舉例
給出如圖3-1所示的圖,求圖中的V0出發,是否存在一條路徑長度為4的搜尋路徑。

圖3-1
顯然,我們知道是有這樣一個解的:V0->V3->V5->V6。
3.2.處理過程

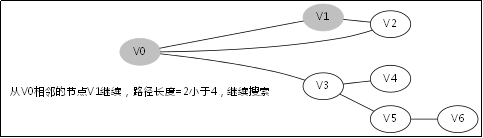

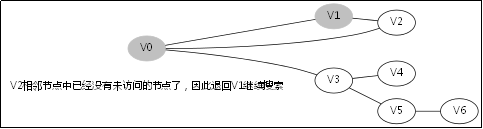
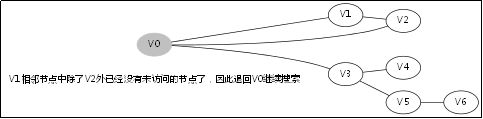
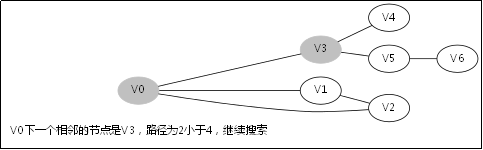
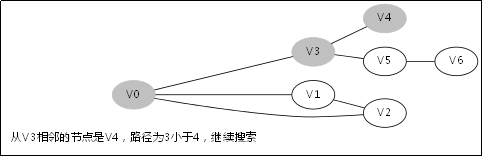
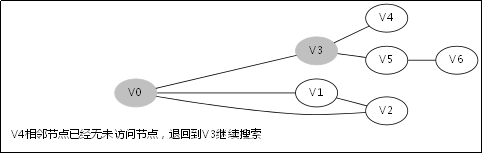
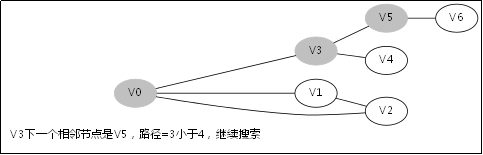
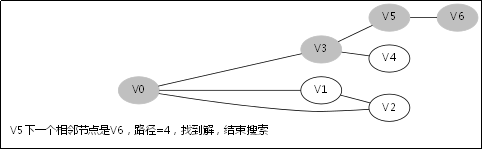
3.4.DFS函式的呼叫堆疊

此後堆疊呼叫返回到V0那一層,因為V1那一層也找不到跟V1的相鄰未訪問節點

此後堆疊呼叫返回到V3那一層

此後堆疊呼叫返回到主函式呼叫DFS(V0,0)的地方,因為已經找到解,無需再從別的節點去搜別的路徑了。
5.另一個例子:24點
5.1.題目描述
想必大家都玩過一個遊戲,叫做“24點”:給出4個整數,要求用加減乘除4個運算使其運算結果變成24,4個數字要不重複的用到計算中。
例如給出4個數:1、2、3、4。我可以用以下運算得到結果24:
1*2*3*4 = 24;2*3*4/1 = 24;(1+2+3)*4=24;……
如上,是有很多種組合方式使得他們變成24的,當然也有無法得到結果的4個數,例如:1、1、1、1。
現在我給你這樣4個數,你能告訴我它們能夠通過一定的運算組合之後變成24嗎?這裡我給出約束:數字之間的除法中不得出現小數,例如原本我們可以1/4=0.25,但是這裡的約束指定了這樣操作是不合法的。
5.2.解法:搜尋樹
這裡為了方便敘述,我假設現在只有3個數,只允許加法減法運算。我繪製瞭如圖5-1的搜尋樹。
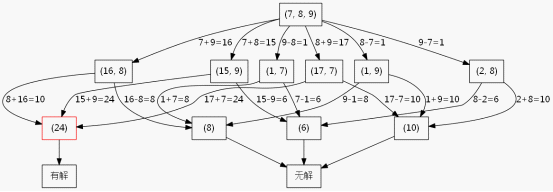
圖5-1
此處只有3個數並且只有加減法,所以第二層的節點最多就6個,如果是給你4個數並且有加減乘除,那麼第二層的節點就會比較多了,當延伸到第三層的時候節點數就比較多了,使用BFS的缺點就暴露了,需要很大的空間去維護那個佇列。而你看這個搜尋樹,其實第一層是3個數,到了第二層就變成2個數了,也就是遞迴深度其實不會超過3層,所以採用DFS來做會更合理,平均效率要比BFS快(我沒寫程式碼驗證過,讀者自行驗證)。
6.OJ題目
題目分類來自網路:
sicily:1019 1024 1034 1050 1052 1153 1171 1187
pku:1088 1176 1321 1416 1564 1753 2492 3083 3411
7.總結
DFS適合此類題目:給定初始狀態跟目標狀態,要求判斷從初始狀態到目標狀態是否有解。
8.擴充套件
不知道你注意到沒,在深度/廣度搜索的過程中,其實相鄰節點的加入如果是有一定策略的話,對演算法的效率是有很大影響的,你可以做一下簡單馬周遊跟馬周遊這兩個題,你就有所體會,你會發現你在搜尋的過程中,用一定策略去訪問相鄰節點會提升很大的效率。
這些運用到的貪心的思想,你可以再看看啟發式搜尋的演算法,例如A*演算法等。
無向圖的儲存方式有鄰接矩陣,鄰接連結串列,稀疏矩陣等。無向圖主要包含兩方面內容,圖的遍歷和尋找聯通分量。
一、無向圖的遍歷
無向圖的遍歷有兩種方式—廣度優先搜尋(BFS)和深度優先搜尋(DFS)。廣度優先搜尋在遍歷一個頂點的所有節點時,先把當前節點所有相鄰節點遍歷了,然後遍歷當前節點第一個相鄰的節點的所有相鄰節點,廣度優先搜尋使用佇列來實現。深度優先搜尋在遍歷當前節點的所有相鄰節點時,先對當前節點的第一個相鄰節點進行訪問,然後遍歷第一個相鄰節點的相鄰節點,依次遞迴,因此深度優先搜尋使用棧實現。
1、BFS圖遍歷程式碼:
function result=BFSTraversal(startNode,Graph)
% 廣度優先搜尋
% Graph 圖連通矩陣
[m n]=size(Graph);
nodelist=zeros(m,1);
queue=startNode;
nodelist(startNode)=1;
result=startNode;
while isempty(queue)==false
i=queue(1);
queue(1)=[];
for j=1:n
if(Graph(i,j)>0&&nodelist(j)==0&&i~=j)
queue=[queue;j];
nodelist(j)=1;
result=[result;j];
end
end
end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、DFS圖遍歷程式碼
function result=DFSTraversal(startNode,Graph)
global nodelist
m=size(Graph,1);
nodelist=zeros(m,1);
result=DFSRecursion(startNode,Graph);- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
function result=DFSRecursion(startNode,Graph)
global nodelist
nodelist(startNode)=1;
result=[startNode];
n=size(Graph,2);
for j=1:n
if(Graph(startNode,j)>0&&nodelist(j)==0&&startNode~=j)
result=[result DFSRecursion(j,Graph)];
end
end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
二、尋找聯通分量
尋找聯通分量的方法就是把一個節點的所有相鄰節點找出來,然後再在未訪問過的節點中選擇一個節點用遍歷方法尋找相鄰節點。
1、基於BFS的尋找聯通分量程式碼:
func