
TensorFlow實戰:Chapter-1(TensorFlow介紹)
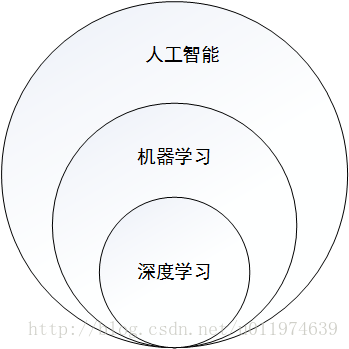
人工智慧、機器學習與深度學習
從計算機發明之初,人們就希望它能代替人們完成重複性勞動,而計算機要想像人類一樣智慧的完成許多工作,需要掌握這個世界海量的知識。
為了使計算機更多的掌握開放環境(open domain)下的知識,研究人員做了許多工作,其中一個影響力非常大的領域是知識相簿1(Ontology) .雖然使用知識相簿可以讓計算機很好地掌握人工定義的知識,但是建立知識相簿需要的成本太大,另一方面通過知識相簿方式明確定義的知識有限。我們常說的經驗,就是一個很難描述的知識,如何讓計算機和人類一樣從歷史的經驗中獲取新的知識?這就是機器學習需要解決的事情。
機器學習
現學術界2對機器學習的定義為:”如果一個程式可以在任務T上,隨著經驗E的增加,效果P也可以隨之增加,則稱為這個程式可以從經驗中學習
在大部分情況下,在訓練資料達到一定數量之前,越多的訓練資料可以使演算法對未知郵件的判斷越精準。之所以說這是在大部分情況下,是因為演算法的效果除了依賴訓練資料,也依賴於從資料中提取的特徵。(假設郵件分類中提取的資料都是郵件時間,那資料量大小和判別垃圾郵件之間的關聯不大),無法從資料中學習更好的特徵表達,這是傳統的機器學習演算法一個共同的問題
深度學習
類似從郵件中提取特徵,如何數字化的表達現實世界中的實體,這個在科學計算中一個重要的問題。深度學習解決的核心問題之一就是自動地將簡單的特徵組合成更加複雜的特徵,並使用這些組合特徵解決問題。深度學習是機器學習的一個分支,它除了可以學習特徵和任務之間的關聯之外,還能自動從簡單特徵中提取更加複雜的特徵。
圖示展現了深度學習和傳統機器學習在流程上的差異.

深度學習演算法可以從資料中學習更加複雜的特徵表達。
人工智慧
總的來說,人工智慧、機器學習和深度學習是非常相關的幾個領域。人工智慧是一類非常寬泛的問題,機器學習是解決這類問題的一個重要手段,深度學習則是機器學習的一個分支。
深度學習工具介紹和對比
深度學習研究的熱潮持續高漲,各種開源深度學習框架也層出不窮,下面列出目前一些主流的深度學習開源工具。
主流的深度學習開源工具總結表
| 工具名稱 | 維護團體 | 支援語言 | 支援系統 |
|---|---|---|---|
| TensorFlow | C++、Python | Linux、Mac-OS、Windows、Android、iOS | |
| Caffe | 伯克利視覺學習中心 | C++、Python、MATLAB | Linux、Mac-OS、Windows |
| Theano | 蒙特利爾大學 | Python | Linux、Mac-OS、Windows |
| Torch | Facebook等 | Lua、LuaJIT、C | Linux、Mac-OS、Windows、Android、iOS |
| MXNet | DMLC | C++、Python、Go、R | Linux、Mac、Windows、Android、iOS |
| CNTK | MSR | Python、C++ | Linux、Windows |
| Deeplearn4j | Skymind | Java、Scala | Linux、Windows、Mac |
主流的深度學習框架介紹
TensorFlow
TensorFlow是相對高階的機器學習庫,使用者可以方便地用它設計神經網路結構,而不必為了追求效率實現C++或CUDA程式碼。TensorFlow通過SWIG(Simplified Wrapper and Interface Generator)實現對多種語言的支援,包括有Python、R、C++等
因為TensorFlow有著對多平臺、多語言支援特性。並且TensorFlow擁有產品級的高質量程式碼,背後又有Google強大的開發、維護能力的加持,相比於基於Python的其他框架,TensorFlow更加成熟、更加完善。
Caffe
Caffe是一個被廣泛使用的開源深度學習框架,由伯克利視覺學中心進行維護。Caffe的核心概念是Layer,每一個神經網路的模組都是一個Layer。設計網路時,只需要把各個Layer拼接在一起構成完整的網路。
Caffe最初設計目標針對於影象,對於CNN的支援非常好,而對後續的其他網路結構支援不是特別充分。而且Caffe在實現新的Layer時,需要將正向和反向兩種計算過程的函式都實現,這對普通使用者來說還是很難上手的。
Theano
Theano的核心是一個數學表示式編譯器,專門為處理大規模神經網路訓練的計算而設計。它可以將使用者定義的各種計算編譯為高效的底層程式碼,並連結各種可以加速的庫。
Theano是一個完全基於Python的符號計算庫,未提供面向底層的C++介面,故移植性差,一般作為研究工具,不作為產品來使用。
Torch
Torch給自己的定位是LuaJIT上的一個高效的科學計算庫,支援大量的機器學習演算法,同時以GPU上的計算優先。Torch的底層語言使用的是Lua,Lua的效能優秀,擁有一個非常直接的呼叫C程式的介面,可移植強。不過,Lua相對Python還不是那麼主流,對大多數使用者有學習成本。
TensorFlow簡介
程式設計模型簡介
核心概念
TensorFlow中的計算可以表示為一個計算圖(computation graph),又稱有向圖(directed graph)。在計算圖中每一個運算操作(operation)將作為一個節點(node),節點與節點之間的連線稱為邊(edge)。計算圖的每一個節點可以有任意多個輸入和輸出,節點可以算是運算操作的例項化(instance).在計算圖的edge中流動(flow)的資料稱為張量(tensor),故得名tensorflow.
下面是用Python設計並執行計算圖的示例:
# -*- coding:utf-8 -*-
import tensorflow as tf
b = tf.Variable(tf.zeros[100]) #生成100維的向量,初始化為0
W = tf.Variable(tf.random_uniform([784,100],-1,1)) #生成784x100的隨機矩陣w
x = tf.placeholder(name="X") #輸入的Placeholder
relu = tf.nn.relu(tf.matmul(W,x)+b) #ReLU(Wx+b)
C=[...] #根據ReLU函式的結果計算Cost
s = tf.Session()
for step in range(0,10):
input=...construct 100-D input array... #為輸入建立一個100維的向量
result = s.run(C,feed_dict={x:input}) #獲取Cost,供給輸入x
print(step,result)
計算圖程式碼示例
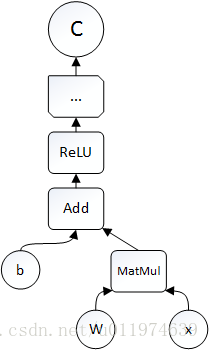
一個運算操作代表一種型別的抽象運算,運算操作可以有自己的屬性,所有屬性需要預設或者可推斷。運算核(kernel)是一個運算操作在某個具體硬體(CPU/GPU等)的實現。在TensorFlow中,可以通過註冊機制加入新的運算操作或運算核。
Session是使用者使用TensorFlow時的互動式介面,使用者可以通過Session的Extend方法建立node和edge,通過run方法執行計算圖。在大多數運算,計算圖某部分會被重複執行多次,使用Variable可以儲存運算過程中tensor至記憶體或視訊記憶體中,可用於迭代等操作。
實現原理
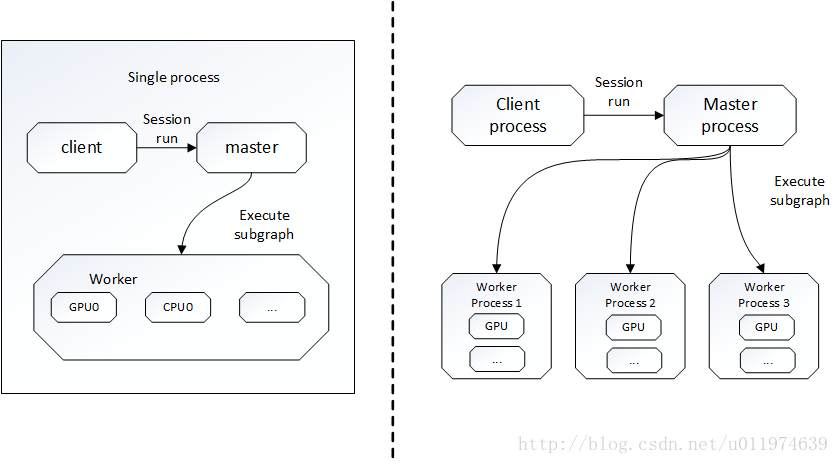
TensorFlow有一個重要元件client,即客戶端,client通過Session的介面與master和多個worker相連。其中每個worker可以與多個硬體裝置(device)相連並管理這些硬體。
TensorFlow有單機模式和分散式模式兩種實現,單機即client、master、worker全部在一臺機器上的同一程序;分散式允許client、master、worker在不同的機器的不同程序中,同時由叢集排程系統統一管理。
TensorFlow單機版本和分散式版本示例圖
1.在只有一個硬體的情況下 計算圖會按依賴關係被順序執行。
2.在有多個硬體的情況下
情況就複雜了。主要有二點:
a.每一個節點該讓什麼硬體裝置執行
TensorFlow設計了一套為節點分配裝置的策略。
該策略首先計算一個代價模型,估算每一個節點的輸入、輸出tensor的大小,以及所需要的計算時間。代價模型一部分由人工經驗制定的啟發式規則得到,另一部分則是對一小部分資料進行實際運算測量得到的。
接下來,分配策略會模擬執行整個計算圖,在模擬每個節點時,會把能執行該節點的裝置都測試一遍,再考慮到代價模型對該節點的計算時間估計,加上資料傳輸通訊時間。最後選擇一個綜合時間最短的裝置作為節點的運算裝置。
可以看出分配策略是一個簡單的貪婪策略,雖然不能確保找到全域性最優,但可以較快的找到一個不錯的節點運算方案。TensorFlow也允許使用者對節點的分配設定限制條件。例如這個節點分配GPU型別的裝置等。
b.如何管理節點間的通訊
當給節點分配裝置的方案確定,整個計算圖就會被劃分為許多子圖,使用同一裝置並且相鄰的節點會劃分到同一子圖。計算圖從x到y的邊,就會被取代為傳送端的傳送節點(send node)、一個接收端的接收節點(receive node),以及從傳送節點到接收節點的邊。如圖
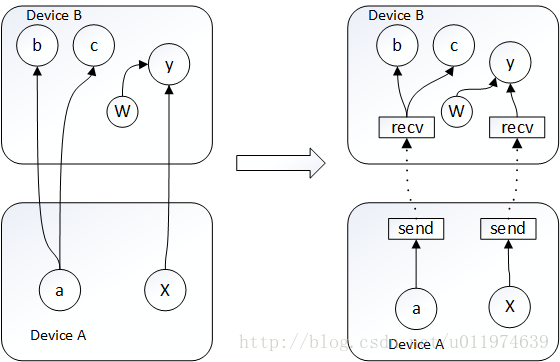
這樣把資料通訊問題轉換為send node 和recv node的實現問題,同時可以解決資料重複傳輸的問題。傳送節點和接收節點的設計簡化了底層的通訊模式。
TensorFlow主要依賴包
本節講述TensorFlow依賴的兩個最主要的工具包—Protocol Buffer和Bazel.
Protocol Buffer
Protocol Buffer是Google開發的處理結構化資料的工具。此處的結構化資料指的是擁有多種屬性的資料。Protocol Buffer解決的主要問題就是處理結構化資料,即將資料序列化傳輸,再將序列化後的資料反序列化.
類似的結構化資料處理工具有XML和JSON格式,例如一段資料
name:zhangsan
id:111111
email:zhangsan@df.comXML格式表達:
<user>
<name>zhangsan</name>
<id>111111</id>
<email>[email protected]</email>
</user>JSON格式表達:
{
"name":"zhangsan",
"id":"1111111",
"email":"[email protected]",
}Protocol Buffer格式的資料和XML或JSON格式有比較大的區別,首先,Protocol Buffer序列化資料是二進位制流,而且使用Protocol Buffer時需要先定義資料的格式(schema)。還原一個序列化後的資料流,需要使用定義好的schema.這樣做的好處是Protocol Buffer序列化後的資料要比XML格式的資料小3到10倍,解析時間快20到100倍。
Protocol Buffer的schema格式
message user{
optional string name = 1;
required int32 id = 2;
repeated string email = 3;
}Protocol Buffer定義資料格式檔案一般儲存在.proto檔案中,每一個message代表了一類結構化資料。Protocol Buffer裡屬性可以為基本資料型別,也可以為另一個message.(類似於C語言的struct結構體).
還可以指定資料的屬性是optional(可選)還是required(必須的)或者是repeated(可重複的).
Bazel
Bazel3是Google開源的自動化構建工具,相比於傳統的Makefile、Ant或者Maven,Bazel在速度、可伸展性、靈活性以及對不同程式語言和平臺的支援上都要出色。
Bazel的一個基本概念的專案空間(workspace),一個workspace可以簡單的理解為一個資料夾(類似ecplise的工程目錄)。在這個資料夾中包含了編譯這個軟體所需要的原始碼以及輸出編譯結果的軟連線地址。
一個workspace可以包含一個或多個應用。一個workspace對應的資料夾是這個專案的根目錄,在這個根目錄中需要一個WORKSPACE檔案,該檔案定義了對外部資源的依賴關係。
在一個workspace內,Bazel通過BUILD檔案來找到需要編譯的目標,BUILD檔案指定了每一個編譯目標的輸入、輸出以及編譯方式。
以Python為例,B**azel對Python支援的編譯方式有三種:py_binary(可執行程式)、py_library(連結庫)和py_test(測試程式)**。例如在一個workspace中有4個檔案:WORKSPACE、BUILD、hello_main.py和hello_lib.py
BUILD #指定需要編譯的目標
hello_lib.py #庫檔案
hello_main.py #編譯目標
WORKSPACE #給出此專案的外部依賴關係(可為空)hello_lib.py完成列印功能:
def print_hello_world():
print('hello world')hello_main.py通過呼叫hello_lib.py完成輸出:
import hello_lib
hello.lib.print_hello_world()在BUILD檔案中定義了兩個編譯目標:
py_library(
name = "hello_lib",
srcs=[
"hello_lib.py",
]
)
py_binary(
name = "hello_main",
srcs=[
"hello_main.py",
],
deps=[
":hello_lib",
],
)BUILD檔案是由一系列的編譯目標組成,每一個編譯目標第一行指定編譯方式,例如示例中的py_library和py_binary。每一條編譯目標的主體是編譯的具體資訊,具體資訊是通過name、srcs,deps等屬性完成。其中name是一個編譯目標的名稱,srcs給出了編譯所需要的原始碼(可以為列表),deps給出了編譯需要的依賴關係.
TensorFlow測試樣例
再安裝好TensorFlow後,我的安裝歷程。
這裡採用Python語言。編寫一個簡單的TensorFlow樣例程式實現兩個向量求和:
import tensorflow as tf
a = tf.constant([1.0,2.0],name='a') #定義兩個常量
b = tf.constant([2.0,3.0],name='b')
result = a + b #向量的加法
sess = tf.Session() #生成一個會話,通過會話計算結果
print(sess.run(result))
輸出結果
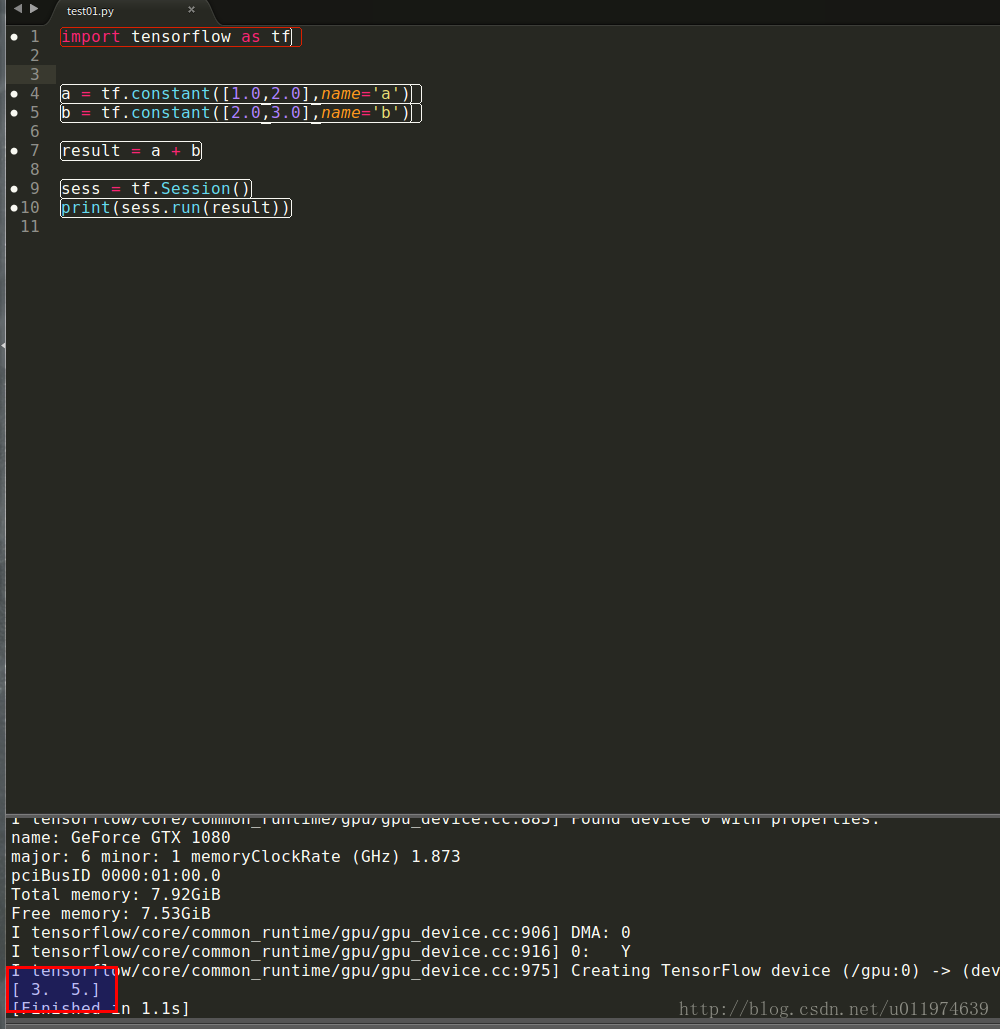
測試成功~
參考資料
《TensorFlow實戰Google深度學習框架》 - 才雲科技 鄭澤宇等
《TensorFlow實戰》 -黃文堅等
相關推薦
TensorFlow實戰:Chapter-1(TensorFlow介紹)
人工智慧、機器學習與深度學習 從計算機發明之初,人們就希望它能代替人們完成重複性勞動,而計算機要想像人類一樣智慧的完成許多工作,需要掌握這個世界海量的知識。 為了使計算機更多的掌握開放環境(open domain)下的知識,研究人員做了許多工作,其
TensorFlow實戰:Chapter-3(CNN-1-卷積神經網路簡介)
卷積神經網路簡介 卷積神經網路(convolutional neural network,CNN)最初是用來解決影象識別等問題設計的,隨著計算機的發展,現在CNN的應用已經非常廣泛了,在自然語言處理(NLP)、醫藥發現、文字處理等等中都有應用。這裡我
TensorFlow實戰:Chapter-4(CNN-2-經典卷積神經網路(AlexNet、VGGNet))
引言 AlexNet AlexNet 簡介 AlexNet的特點 AlexNet論文分析 引言
TensorFlow實戰:Chapter-6(CNN-4-經典卷積神經網路(ResNet))
ResNet ResNet簡介 ResNet(Residual Neural Network)由微軟研究院的何凱明大神等4人提出,ResNet通過使用Residual Unit成功訓練152層神經網路,在ILSCRC2015年比賽中獲得3.75%的
TensorFlow實戰:Chapter-5(CNN-3-經典卷積神經網路(GoogleNet))
GoogleNet GoogleNet 簡介 本節講的是GoogleNet,這裡面的Google自然代表的就是科技界的老大哥Google公司。 Googe Inceptio
TensorFlow實戰:Chapter-8上(Mask R-CNN介紹與實現)
簡介 程式碼源於matterport的工作組,可以在github上fork它們組的工作。 軟體必備 復現的Mask R-CNN是基於Python3,Keras,TensorFlow。 Python 3.4+ TensorFlow 1.3
TensorFlow實戰:Chapter-7上(RNN簡介和RNN在NLP應用)
RNN簡介 迴圈神經網路是一類用於處理序列資料的神經網路。就像卷積網路是專門處理網格化資料X(如一個影象)的神經網路,迴圈神經網路是專門用於處理序列x(1),...,x(τ)的神經網路。正如卷積網路可以很容易地擴充套件到具有很大寬度和高度的影象,以及
TensorFlow實戰:Chapter-9下(DeepLabv3+在自己的資料集訓練)
基本配置 資料集處理 我的資料集是3分類問題,但因為資料集的保密協議,在後面的demo中我沒有放出原圖片,我會盡量將訓練細節寫出來。為了方便記錄,我又使用了CamVid資料集(從這裡下載)測試了一下。 資料集處理分成三大步: 標註資料 製作
Tensorflow學習: AlexNet程式碼(slim版)
# Copyright 2016 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use th
老查的ARM學習筆記:chapter-1(按鍵驅動程式設計)
前面的部落格中,有一篇通過按鍵玩中斷的文章,不過那裡的程式是裸機,也就是沒有加系統下設計的程式,也就和在微控制器中設計的程式一樣比較簡單。現在我們來看看按鍵的驅動程式在linux系統下是如何設計的。 1 混雜裝置驅動模型** 1 混雜裝置驅動描述 首先
sklearn實戰:糖尿病預測(knn演算法)
%matplotlib inline import matplotlib.pyplot as plt import numpy as np import pandas as pd # 載入資料 data = pd.read_csv('datas
tensorflow實戰:端到端簡單粗暴識別驗證碼(反爬利器)
今天分享一下如何簡單粗暴的解決驗證碼的辦法 背景: 對於一個爬蟲開發者來說,反爬蟲無疑是一個又愛又恨的對手,兩者之間通過鍵盤的鬥爭更是一個沒有硝煙的戰場。 反爬蟲有很多措施,在這裡說說驗證碼這一塊 論爬蟲修養:大家都是混口飯吃,上有老下有小,碼農何苦為難碼農?爬資
tensorflow實戰:端到端簡單粗暴識別驗證碼(反爬利器OA信用盤平臺可殺大賠小)
今天分享一OA信用盤平臺可殺大賠小(殺豬)QQ2952777280【話仙原始碼論壇】hxforum.com下如何簡單粗暴的解決驗證碼的辦法背景:對於一個爬蟲開發者來說,反爬蟲無疑是一個又愛又恨的對手,兩者之間通過鍵盤的鬥爭更是一個沒有硝煙的戰場。反爬蟲有很多措施,在這裡說說驗證碼這一塊論爬蟲修養:大家都是混口
TensorFlow實戰:經典卷積神經網路(AlexNet、VGGNet)
下面表格是兩個網路的簡單比較: 特點 AlexNet VGGNet 論文貢獻 介紹完整CNN架構模型(近些年的許多CNN模型都是依據此模型變種來的)和多種訓練技巧 CNN模型復興的開山之作 使用GPU加速
Tensorflow實戰:Word2Vec_Skip_Gram原理及實現(多註釋)
Word2Vec也稱Word Embeddings,中文的叫法為“詞向量”或“詞嵌入”,是一種非常高效的,可以從原始語料中學習字詞空間向量的預測模型。 在Word2Vec出現之前,通常將字詞轉為One-Hot Encoder ,一個詞對應一個
《Tensorflow實戰》學習筆記(一)
深度學習基本四步驟: (1)定義演算法公式,也就是神經網路forward時的計算 (2)定義loss,選定優化器,並指定優化器優化loss (3)迭代對資料進行訓練 (4)在測試集合對準確率進行評測 有用的類 tf.placeholder() tf.Variable(
tensorflow 16:資料讀取(以cifar10_input.py為例)
資料讀取概述 TensorFlow程式讀取資料一共有3種方法: 供給資料(Feeding): 在TensorFlow程式執行的每一步, 讓Python程式碼來供給資料。 從檔案讀取資料: 在TensorFlow圖的起始, 讓一個輸入管線從檔案中讀取資料。 預載
tensorflow實戰:MNIST手寫數字識別的優化2-代價函式優化,準確率98%
最簡單的tensorflow的手寫識別模型,這一節我們將會介紹其簡單的優化模型。我們會從代價函式,多層感知器,防止過擬合,以及優化器的等幾個方面來介紹優化過程。 1.代價函式的優化: 我們可以這樣將代價函式理解為真實值與預測值的差距,我們神經
ubuntu安裝tensorflow-gpu:匯流排錯誤(核心已轉儲)
我的環境是ubuntu16.04,cuda8.0,cudnn5.1,根據官方給的匹配說法是,tensorflow-gpu只能安裝1.2.0版本的,文章最後附了tensorflow與cuda以及cudnn的對應匹配版本圖,不誇張的說,1.2.0版本的tensorf
TensorFlow實戰:TensorFlow中的CNN
這裡按照官方api介紹官方api點這裡 卷積 不同的ops下使用的卷積操作總結如下: conv2d:Arbitrary filters that can mix channels together(通道混合處理的任意濾波器) depthwise_conv2d:Filter