
大資料資料倉庫——hive學習權威指南
學習hive權威指南
目錄:
- ETL介紹
- 大資料平臺架構概述
- 系統資料流動
- hive概述
- hive在hadoop生態系統中
- hive體系結構
- hive安裝及使用
- hive客戶端的基本語句
- hive在HDFS檔案系統中的結構
- 修改hive元資料儲存的資料庫
- hive操作命令
- hive常用配置
- hive常用的Linux命令選項
- hive三種表的建立方式
- hive外部表
- hive臨時表
- hive分割槽表
- hive桶表
- hive分析函式
- hive資料的匯入和匯出
- hive常見的hql語句
- hive和MapReduce的相關執行引數
- hive自定義UDF函式
- hiveserver2與jdbc客戶端
- hive執行模式與虛擬列
- 【案列一】日誌資料檔案分析
- 【案列二】hive shell 自動化載入資料
- hive優化
- hadoop & hive壓縮
- hive儲存格式
- hive總結&應用場景
一、ETL介紹:
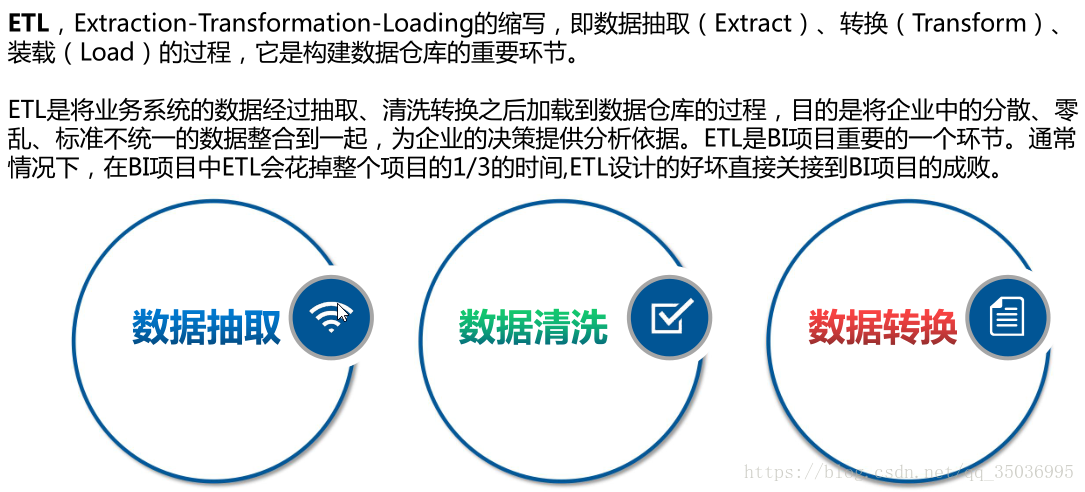
資料清洗:過濾那些不符合要求的資料或者修正資料之後再進行抽取
不完整的資料:比如資料裡一些應該有的資訊缺失,需要補全後再寫入資料倉庫
錯誤的資料:比如字串資料後面有一個回車操作、日期格式不正確、日期越界等,需要修正之後再抽取
重複的資料:重複資料記錄的所有欄位,需要去重
資料轉換:不一致的資料轉換,比如同一個供應商在結算系統的編碼是XX0001,而在CRM中編碼是YY0001,統一編碼 實現有多種方法:
1、藉助ETL工具(如Oracle的OWB、SQL Server的DTS、SQL Server的SSIS服務、Informatic等等)實現
OWB:Oracle Warehouse Builder
DTS:Data Transformation Service
SSIS:SQL Server Integration Services
2、SQL方式實現
3、ETL工具和SQL相結合-----》間接引出hive
藉助工具可以快速的建立起ETL工程,遮蔽了複雜的編碼任務,提高了速度,降低了難度,但是缺少靈活性。
SQL的方法優點是靈活,提高ETL執行效率,但是編碼複雜,對技術要求比較高。
第三種是綜合了前面二種的優點,會極大地提高ETL的開發速度和效率
二、大資料平臺架構概述:
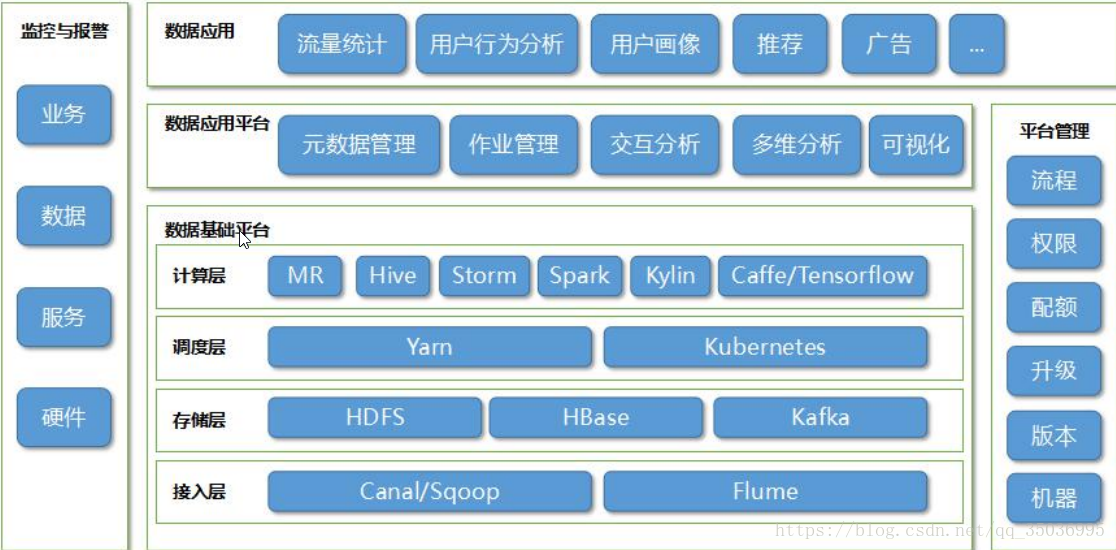
資料儲存:HDFS(檔案儲存)、HBase(KV儲存)、Kafka(訊息快取)
排程:採用了Yarn的統一排程以及Kubernetes的基於容器的管理和排程的技術
計算分析:MR、HIVE、Storm、Spark、Kylin以及深度學習平臺比如Caffe、Tensorflow等等
應用平臺:互動分析sql,多維分析:時間、地域等等,
視覺化:資料分析tableau,阿里datav、hcharts、echarts
資料應用就是指資料的業務
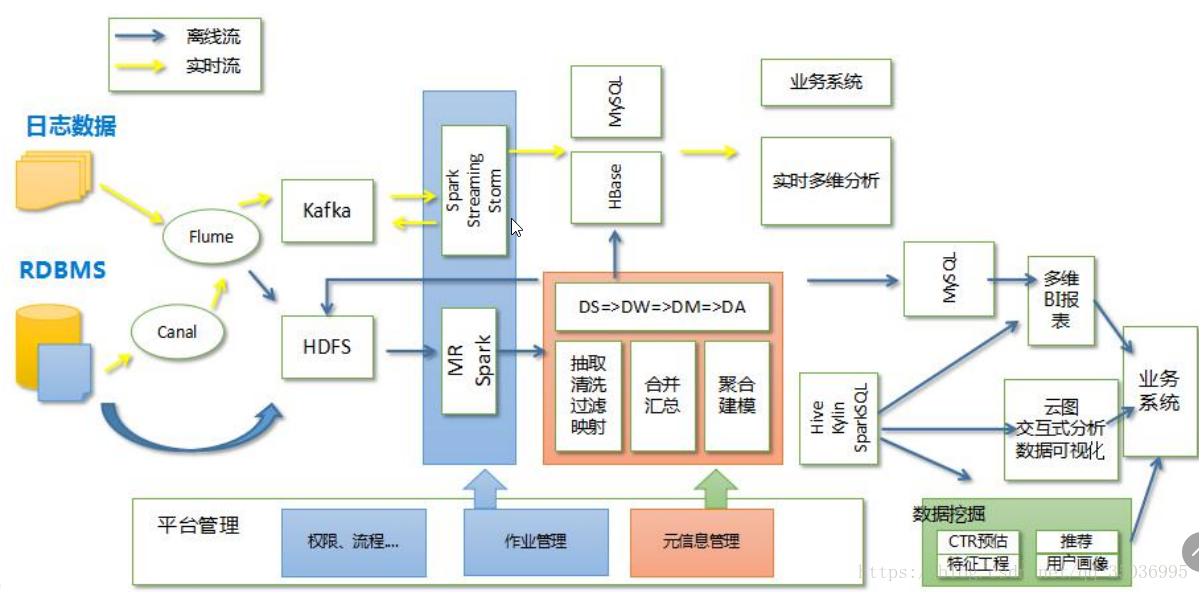
三、系統資料流動:
四、hive概述:

結構化資料:資料型別,欄位,value---》hive
非結構化資料:比如文字、圖片、音訊、視訊---》會有非關係型資料庫儲存,或者轉換為結構化
結構化日誌資料:伺服器生成的日誌資料,會以空格或者指表符分割的資料,比如:apache、nginx等等

Hive 可以理解為一個工具,不存在主從架構,不需要安裝在每臺伺服器上,只需要安裝幾臺就行了
hive還支援類sql語言,它可以將結構化的資料檔案對映為一張資料庫表,並提供簡單的SQL查詢功能
hive有個預設資料庫:derby,預設儲存元資料---》後期轉換成關係型資料庫儲存mysql
hive的版本:apache-hive-1.2.1 、hive-0.13.1-cdh5.3.6
主要檢視版本的依賴
下載地址:
apache的:
cdh的:http://archive.cloudera.com/cdh5/cdh/5/
sql on hadoop的框架:
hive--》披著sql外衣的map-reduce
impala--》查詢引擎,適用於互動式的實時處理場景
presto--》分散式的sql查詢引擎,適用於實時的資料分析
spark sql
等等。。。。
詳細瞭解sql on hadoop請訪問博主的部落格:
五、Hive在Hadoop生態體系中

六、hive體系結構:
hive架構圖


client:
命令列 -常用
JDBC
metastore元資料:儲存在資料庫
預設的資料庫derby 後期開發改成mysql
元資料:表名,表的所屬的資料庫,表的擁有者,表的分割槽資訊,表的型別,表資料的儲存的位置
cli-》metastore
TBLS-》DBS-》hdfs的路徑
Hadoop:
使用mapreduce的計算模型
使用hdfs進行儲存hive表資料
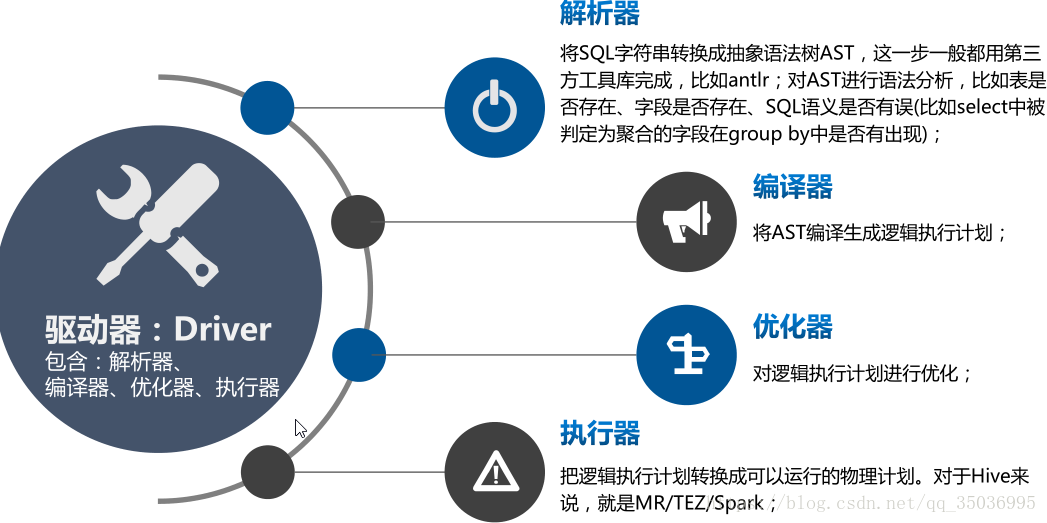
Driver:
解析器:解析的HQL語句
編譯器:把HQL翻譯成mapreduce程式碼
優化器:優化
執行器:把程式碼提交給yarn

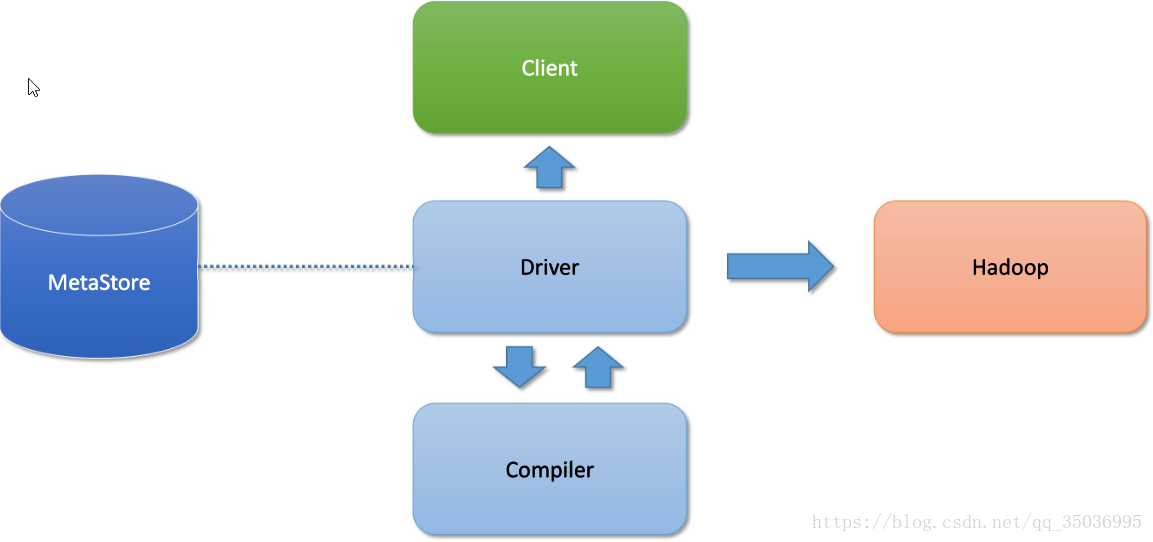
hive通過client提交的job,Driver經過解析、編譯、優化、執行-》最後提交給hadoop的MapReduce處理
七、Hive安裝及使用
八、Hive客戶端的基礎語句:
1、進入到hive的客戶端:bin/hive;2、檢視資料庫:show databases;
3、建立資料庫:create database test;
4、進入到資料庫:use test;
5、查看錶:show tables;
6、資料型別:
tinyint、smallint、int、bigint -》int
float、double、date
string、vachar、char -》string
7、create table hive_table(
id int,
name string
);
8、載入資料:
load data local inpath '/opt/datas/hive_test.txt' into table hive_table;
local:指定本地的資料檔案存放路徑
不加local:指定資料在hdfs的路徑
9、查詢語句:
select * from hive_table;
10、hive的預設資料分隔符是\001,也就是^A ,分割符 " ", "," ,"\t"等等
如果說資料的分隔符與表的資料分隔符不一致的話,讀取資料為null
按下crtl+v然後再按下crtl+a就會出來^A(\001)
create table row_table(
id int,
name string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
load data local inpath '/opt/datas/hive_test.txt' into table row_table;
九、hive在hdfs上的檔案結構
資料倉庫的位置 資料庫目錄 表目錄 表的資料檔案/user/hive/warehouse /test.db /row_table /hive_test.txt
default預設的資料庫:指的就是這個/user/hive/warehouse路徑
十、修改元資料儲存的資料庫:
1、用bin/hive同時開啟多個客戶端會報錯java.sql.SQLException: Another instance of Derby may have already booted the database /opt/modules/apache/hive-1.2.1/metastore_db.

derby資料庫預設只能開啟一個客戶端,這是一個缺陷,換個資料庫儲存元資料
資料庫可選有這幾種:derby mssql mysql oracle postgres
一般選擇mysql元資料儲存
十一、Hive操作命令
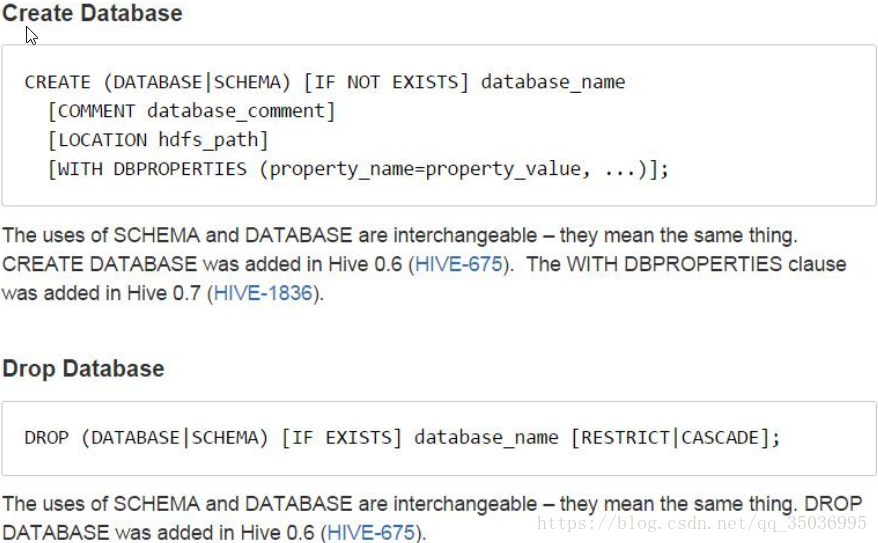

desc tablename;
desc extended 表名;
desc formatted 表名;
2、修改表名
alter table table_oldname rename to new_table_name;
3、給表增加一個列
alter table new_table add columns(age int);
alter table new_table add columns(sex string comment 'sex');添加註釋
4、修改列的名字以及型別
create table test_change(a int,b int,c int);
修改列名 a -> a1
alter table test_change change a a1 int;
a1改a2,資料型別改成String,並且放在b的後面;
alter table test_change change a1 a2 string after b int;
將c改成c1,並放在第一列
alter table test_change change c c1 int first;
5、替換列(不能刪除列,但是可以修改和替換,)是全表替換
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
alter table test_change replace columns(foo int , too string);
6、清除表資料truncate
只清除表資料,元資料資訊還是存在的,表的結構已經表還是在的

truncate table row_table;

drop table row_table;
清除資料,表以及表的結構清除,元資料也清除
8、刪除資料庫
drop database test_db CASCADE;
刪除資料庫的資訊,如果資料庫不為空的話,則要加CASCADE欄位
9、檢視hive自帶的函式: show functions;
desc function when;
desc function extended when; ->檢視詳細的用法
十二、hive的常用配置

修改 hive-log4j.properties.template 修改為hive-log4j.properties
修改 hive.log.dir=/opt/modules/apache/hive-1.2.1/logs
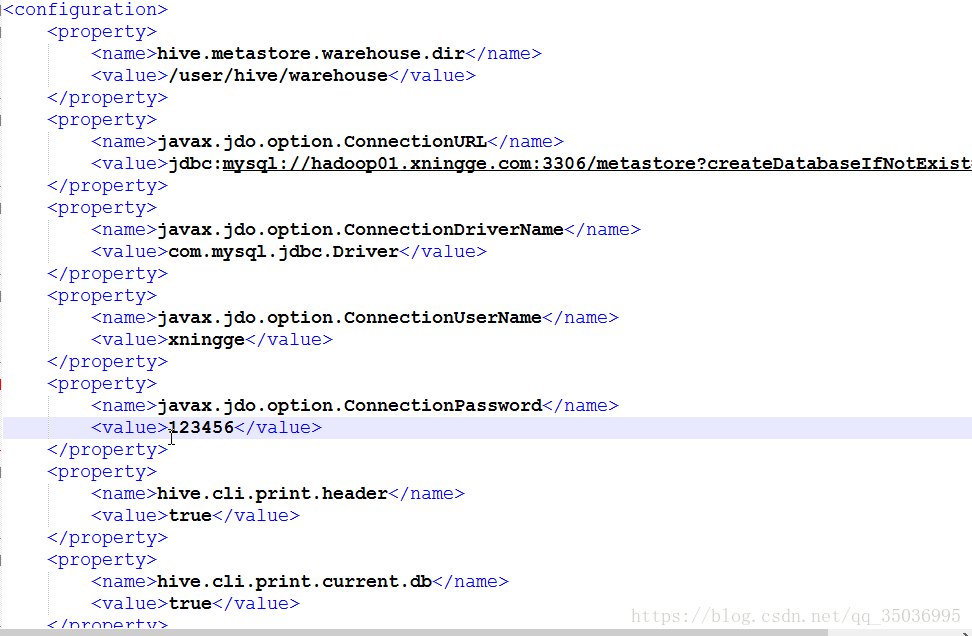
2、顯示資料庫和列名,新增配置資訊到hive-site.xml
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
如下圖:
十三、hive常用的linux命令選項
檢視幫助資訊 bin/hive -help1、--database指定登陸到哪個database 下面去
bin/hive --database mydb;
2、指定一條sql語句,必須用引號包裹
bin/hive -e 'show databses'
bin/hive -e 'select * from mydb.new_table'
3、指定寫sql語句的檔案,執行sql
bin/hive -f hivesql
指定一些較為的sql語句,週期性的執行
4、檢視sql語句檔案
bin/hive -i hivesql
執行檔案的sql語句並進入到hive的客戶端
用來初始化一些操作
5、bin/hive -S hivesql
靜默模式
6、在當前回話視窗修改引數的屬性,臨時生效
bin/hive --hiveconf hive.cli.print.header=false;
7、在hive的客戶端中使用set修改引數屬性(臨時生效),以及檢視引數的屬性
set hive.cli.print.header -》檢視引數的屬性
set hive.cli.print.header=true; -》修改引數屬性
8、常用的shell : ! 和 dfs
-》! 表示訪問的linux本地的檔案系統 ->! ls /opt/modules/apache/
-》dfs表示訪問的是hdfs的檔案系統 -> dfs -ls /;
9、CREATE database_name[LOCATION hdfs_path]
create database hive_test LOCATION "/location";
自定義資料庫在hdfs上的路徑,把指定/location當成預設的資料庫,
所以這邊資料庫的名字不顯示
十四、hive三種表的建立方式
1、【普通的建立】create table stu_info(
num int,
name string
)
row format delimited fields terminated by " ";
載入資料到本地:將本地的資料複製到表對應的位置
load data local inpath '/opt/datas/test.txt' into table stu_info; 注意:'/opt/datas/test.txt' 本地資料目錄位置
載入hdfs資料:將hdfs上的資料移動到表對應的位置load data inpath '/table_stu.txt' into table stu_info; 注意:'/table_stu.txt' 本地資料目錄位置

[AS select_statement];
create table stu_as as select name from stu_info;
將查詢的資料和表的結構賦予一張新的表
類似於儲存一箇中間結果集

LIKE existing_table_or_view_name
create table stu_like like stu_info;
複製表的結構賦予一張新的表
接下來建立兩張表(為學習其他表建立基本表):

【databases】
create database db_emp;【員工表】
create table emp(
empno int comment '員工編號',
ename string comment '員工姓名',
job string comment '員工職位',
mgr int comment '領導編號',
hiredate string comment '入職時間',
sal double comment '薪資',
comm double comment '獎金',
deptno int comment '部門編號'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp;注意: '/opt/datas/emp.txt'本地資料目錄位置
【部門表】
create table dept(
deptno int comment '部門編號',
dname string comment '部門名稱',
loc string comment '地址'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/dept.txt' into table dept;
【覆蓋表的資料overwrite】內部機制有刪除的操作,刪除原來的資料載入表中
load data local inpath '/opt/datas/dept.txt' overwrite into table dept;注意: '/opt/datas/dept.txt' 本地資料目錄位置
十五、hive外部表


關鍵詞 [EXTERNAL]
[LOCATION hdfs_path]共享資料:去載入hdfs上所屬路徑下的資料
create table emp_part(
empno int comment '員工編號',
ename string comment '員工姓名',
job string comment '員工職位',
mgr int comment '領導編號',
hiredate string comment '入職時間',
sal double comment '薪資',
comm double comment '獎金',
deptno int comment '部門編號'
)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/emp_db.db/emp';
如果你改變emp這張表的資料,那麼emp1也會發生改變如果你改變emp1這張表的資料,那麼emp也會發生改變
刪除表drop table emp1;
-》資料共用一份資料,結果就把共享的資料刪除了
-》刪除表的時候會刪除表對應的元資料資訊(emp)
-》清除表對應的hdfs上的資料夾
建立外部表
create EXTERNAL table dept_ext(
deptno int comment '部門編號',
dname string comment '部門名稱',
loc string comment '地址'
)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/db_emp.db/dept';
表的型別Table Type: EXTERNAL_TABLE
刪除表:drop table dept_ext;-》外部表只是刪除元資料(dept_ext)
-》不會刪除對應的資料夾
-》一般先建立內部表,然後根據需求建立多張外部表
-》外部表主要是資料安全性的作用
hive內部表和外部表的區別:
1)建立表的時候:建立內部表時,會將資料移動到資料倉庫指向的路徑;若建立外部表,僅記錄資料所在的路徑,不對資料的位置做任何的改變
2)刪除表時:在刪除表的時候,內部表的元資料和資料一起刪除,而外部表只刪除元資料,不刪除資料。這樣外部表相對於內部表來說更加安全一些,資料組織也更加靈活,方便資料共享
十六、hive臨時表
create table dept_tmp(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/dept.txt' into table dept_tmp;
資料存放路徑location:
Location:hdfs://hadoop01.com:8020/tmp/hive/hadoop/23a93177-f22f-4035-a2e3-c51cf315625f/_tmp_space.db/962463c2-6563-47a8-9e62-2a1e8eb6ed19
關閉hive cli:
自動刪除臨時表
也可以手動刪除drop
CREATE TEMPORARY TABLE IF NOT EXISTS dept_tmp(
deptno int ,
dname string ,
loc string
)row format delimited fields terminated by '\t';
LOCATION '/user/hive/warehouse/db_emp.db/dept';
關閉hive cli:
自動刪除臨時表的資料
也可以手動刪除drop,刪除臨時表的資料及資料檔案
十七、hive分割槽表

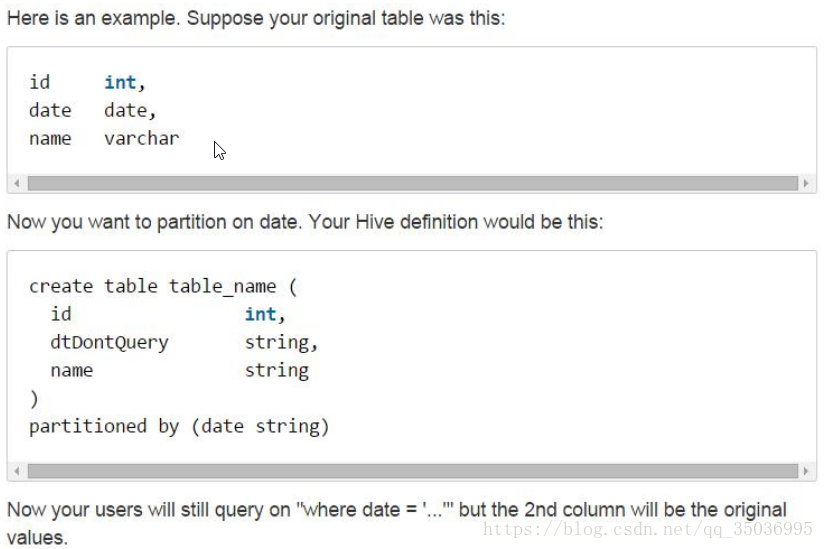


企業中如何使用分割槽表

[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
普通表:select * from logs where `date`='2018120'
執行流程:對全表的資料進行查詢,然後才會進行過濾
分割槽表:select * from logs where `date`='2018120' and hour='00'
執行流程:直接載入對應資料夾路徑下的資料
分割槽表的欄位是邏輯性的,體現在hdfs上形成一個資料夾存在,並不在資料中,
必須不能是資料中包含的欄位
【一級分割槽】
create table emp_part(
empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)PARTITIONED BY(`date` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018120');load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018121');
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018122');
select * from emp_part where `date`='2018120';
【二級分割槽】
create table emp_part2(
empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)
PARTITIONED BY(`date` string,hour string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='2018120',hour='01');
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='2018120',hour='02');
select * from emp_part2 where `date`='2018120';
select * from emp_part2 where `date`='2018120' and hour='01';
-》分割槽表的作用主要是提高了查詢的效率
十八、hive桶表
桶表:獲取更高的處理效率、join、抽樣資料
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
create table emp_bu(empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)CLUSTERED BY (empno) INTO 4 BUCKETS
row format delimited fields terminated by '\t';
先建表,然後設定
set hive.enforce.bucketing = true;
insert overwrite table emp_bu select * from emp;
十九、hive分析函式

官網:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
分析函式over:分析函式用於計算基於組的某種聚合值,它和聚合函式不同之處是對於每個組返回多行,而聚合函式對於每個組返回一行資料。
主要作用:對於分組後的資料進行處理,然後輸出處理後的結果
需求1: 查詢部門編號為10的所有員工,按照薪資進行降序排序desc(預設升序)
select * from emp where deptno=10 order by sal desc;
結果:
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
需求2:將每個部門薪資最高的那個人的薪資顯示在最後一列
select empno,ename, deptno,sal, max(sal) over(partition by deptno order by sal desc ) as sal_111 from emp;
結果:
7839 KING 10 5000.0 5000.0 1
7782 CLARK 10 2450.0 5000.0 2
7934 MILLER 10 1300.0 5000.0 3
7788 SCOTT 20 3000.0 3000.0
7902 FORD 20 3000.0 3000.0
7566 JONES 20 2975.0 3000.0
7876 ADAMS 20 1100.0 3000.0
7369 SMITH 20 800.0 3000.0
7698 BLAKE 30 2850.0 2850.0
7499 ALLEN 30 1600.0 2850.0
7844 TURNER 30 1500.0 2850.0
7654 MARTIN 30 1250.0 2850.0
7521 WARD 30 1250.0 2850.0
7900 JAMES 30 950.0 2850.0
需求3:將每個部門薪資最高的那個人的薪資顯示在最後一列並且顯示唯一的編號
select empno,ename, deptno,sal, row_number() over(partition by deptno order by sal desc ) as sal_111 from emp ;結果:
7839 KING 10 5000.0 1
7782 CLARK 10 2450.0 2
7934 MILLER 10 1300.0 3
7788 SCOTT 20 3000.0 1
7902 FORD 20 3000.0 2
7566 JONES 20 2975.0 3
7876 ADAMS 20 1100.0 4
7369 SMITH 20 800.0 5
7698 BLAKE 30 2850.0 1
7499 ALLEN 30 1600.0 2
7844 TURNER 30 1500.0 3
7654 MARTIN 30 1250.0 4
7521 WARD 30 1250.0 5
7900 JAMES 30 950.0 6
需求4:獲取每個部門薪資最高的前兩位(巢狀子查詢的方式)
select empno,ename, deptno,sal from(select empno,ename, deptno,sal,row_number() over (partition by deptno order by sal desc) as rn from emp) as tmp where rn < 3;
結果:
7839 KING 10 5000.0
7782 CLARK 10 2450.0
7788 SCOTT 20 3000.0
7902 FORD 20 3000.0
7698 BLAKE 30 2850.0
7499 ALLEN 30 1600.0
二十、hive資料匯入和匯出

【匯入】
1、load data [loacl]
-》本地,將資料檔案copy到hdfs對應的目錄,適合大部分的場景使用
load data local inpath 'loac_path' into table tablename;
-》HDFS,將資料檔案move到hdfs對應的目錄上,適合大資料集的儲存
load data inpath 'hdfs_path' into table tablename;
2、load data + overwrite 【覆蓋資料】
load data [local] inpath 'path' overwrite into table tablename;
-》適合重複寫入資料的表,一般指的臨時表,作為過渡使用
3、子查詢 as select
create table tb2(先建表) as select * from tb1;
-》適合資料查詢結果的儲存
4、insert方式
insert into table tablename select sql; -》追加
insert overwrite table tablename select sql; -》覆蓋
測試:create table tb like dept;
insert into table tb select * from dept;
在關係型資料庫插入一條資料:insert into table tablename values();
在hive中:insert into table tb values(50,'AA','bb');
注意:這種方式適合資料量非常小的情況下去使用,如果說資料量大,避免這種操作
show tables出現values__tmp__table__1這個臨時表,關閉會話就消失
5、location方式

【匯出】
1、insert
insert overwrite [local] directory 'path' select sql;
-》本地
insert overwrite local directory '/opt/datas/emp_in01' select * from emp;
insert overwrite local directory '/opt/datas/emp_in01' row format delimited fields terminated by "\t" select * from emp;
-》HDFSinsert overwrite directory '/emp_insert' select * from emp;
insert overwrite directory '/emp_insert' row format delimited fields terminated by "\t" select * from emp;
2、bin/hdfs dfs -get xxx 下載資料檔案
hive> dfs -get xxx (hive的客戶端)
3、bin/hive -e 或者 -f + >> 或者 > (追加和覆蓋符號)
4、sqoop 方式:import匯入和export 匯出
二十一、hive常見的hql語句


相關推薦
大資料資料倉庫——hive學習權威指南
學習hive權威指南目錄:ETL介紹大資料平臺架構概述系統資料流動hive概述hive在hadoop生態系統中hive體系結構hive安裝及使用hive客戶端的基本語句hive在HDFS檔案系統中的結構修改hive元資料儲存的資料庫hive操作命令hive常用配置hive常用
大資料協作框架——sqoop學習權威指南
大資料協作框架“大資料協作框架”其實是一個統稱,實際上就是Hadoop 2.x生態系統中幾個輔助Hadoop 2.x框架。在此,主要是以下四個框架:資料轉換工具Sqoop檔案收集庫框架Flume任務排程框架Oozie大資料WEB工具Hue選擇CDH5.3.x版本框架Cloud
大資料的倉庫Hive原理(三)
上次我們簡單說了一下Hive的工作原理,今天我們來深入看一下它是如何把Hql語句轉換為m/r來執行的。 1、編譯器 簡介 Hive編譯器將一個Hive
大資料的倉庫Hive原理(二)
上次我們說到了大資料應用中的資料倉庫hive,我們知道了利用hive可以更方便的處理資料,而且它的擴充套件性、延展性和容錯性都比較好,但是它是如何利用Hql(類Sql語句)來實現資料處
大資料最經典的學習路線指南(最全知識點總結)
開發十年,就只剩下這套架構體系了! >>>
《Hadoop 權威指南 - 大資料的儲存與分析》學習筆記
第一章 初識Hadoop 1.2 資料的儲存與分析 對多個硬碟中的資料並行進行讀/寫資料,有以下兩個重要問題: 硬體故障問題。解決方案:複製(replication),系統儲存資料的副本(replica)。 以某種方式結合大部分資料來共同完成分析。MapReduce
Hadoop權威指南-大資料的儲存與分析第四版——學習筆記——第2章——1
MapReduce 適合處理半結構化的資料 MapReduce任務階段 Map階段+Reduce階段 Key-Value作為輸入輸出 實現兩個函式:map(),reduce() Map階段 輸入的Key:文字中的偏移量 輸入的value:文字 輸出的k-v給reduce處
《Hadoop權威指南大資料的儲存與分析第版修訂版升級版》pdf附網盤下載連結+(附一個菜鳥的java學習之路)
技術書閱讀方法論 一.速讀一遍(最好在1~2天內完成) 人的大腦記憶力有限,在一天內快速看完一本書會在大腦裡留下深刻印象,對於之後複習以及總結都會有特別好的作用。 對於每一章的知識,先閱讀標題,弄懂大概講的是什麼主題,再去快速看一遍,不懂也沒有關係,但是一定要在不懂的
學習大資料技術,Hive實踐分享之儲存和壓縮的坑
在學習大資料技術的過程中,HIVE是非常重要的技術之一,但我們在專案上經常會遇到一些儲存和壓縮的坑,本文通過科多大資料的武老師整理,分享給大家。 大家都知道,由於叢集資源有限,我們一般都會針對資料檔案的「儲存結構」和「壓縮形式」進行配置優化。在我實際檢視以後,發現叢集的檔案儲存格式為Parque
大資料環境---資料倉庫(hive+mysql+hadoop)的構建
前面已經配置好了叢集環境zookeeper,hadoop。 以及分散式資料庫hbase。 這個階段要開始構建資料倉庫的練習。涉及到的軟體: mysql, hive 。 背景: &nbs
大資料入門學習必備指南
大資料方向的工作目前分為三個主要方向: 01.大資料工程師 02.資料分析師 03.大資料科學家 04.其他(資料探勘本質算是機器學習,不過和資料相關,也可以理解為大資料的一個方向吧) 一、大資料工程師的技能要求 二、大資料學習路徑 三、學習資源推薦(書籍、部落格、網站)
大資料學習路線指南(最全知識點總結)
大資料是對海量資料進行儲存、計算、統計、分析處理的一系列處理手段,處理的資料量通常是TB級,甚至是PB或EB級的資料,這是傳統資料處理手段所無法完成的,其涉及的技術有分散式計算、高併發處理、高可用處理、叢集、實時性計算等,彙集了當前IT領域熱門流行的IT技術。 大資料入門,需要
大資料學習系列——HIVE學習分割槽
分割槽查詢 Hive查詢執行分割槽語法 SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08'; 分割槽表的意義在於優化查詢。查詢時儘量利用分割槽欄位。如果不使用分割槽欄位,就會全部掃描
大資料入門-Hive學習從這裡開始
Hive是基於Hadoop HDFS分散式檔案系統的分散式資料倉庫架構。它為資料倉庫的管理提供了許多功能:資料ETL(抽取、轉換和載入)工具,資料儲存管理和大型資料集的查詢和分析能力。同時Hive還定義了類SQL的語言(HiveQL)。允許使用者進行和SQL相似的操作,它可以
MongoDB大資料處理權威指南 第2版 pdf 免費下載
本書根據MongoDB的版本做了相應更新,其中包含MongoDBn*的所有特性,包括版本2.2中引入的聚集框架和版本2.4中引入的雜湊索引。MongoDB是最流行的“大資料”NoSQL資料… 下載地址
Hadoop權威指南學習——從Hadoop URL讀取資料
一、準備工作 在hadoop-env.sh中配置好 HADOOP_CLASSPATH 變數,值為編譯後的.class檔案所放置的地方。 export HADOOP_CLASSPATH=/usr/software/hadoop/hadoop-2.2.0/cl
《MongoDB大資料處理權威指南(第2版)》之MongoDB入門
想象一下這樣的世界:資料庫使用是如此的簡單,以至於你忘記了正在使用它。再想象一下這樣的世界:不需要任何複雜配置或設定,資料庫仍然能夠快速執行,並且具有良好的擴充套件性。想一下,如何可以只關注gg於手上的任務,完成它,並可以按時下班。這聽起來有點神奇,但是Mon
大資料基礎知識學習-----Hive學習筆記(二)Hive安裝環境準備
Hive安裝環境準備 Hive安裝地址 Hive安裝部署 Hive安裝及配置 把apache-hive-1.2.1-bin.tar.gz上傳到linux的/opt/software目錄下 解壓apache-hive-1.2.
大資料系列之資料倉庫Hive知識整理(四)Hive的嚴格模式,動態分割槽,排序,事務,調優
1.Hive的嚴格模式Hive提供了一個嚴格模式,可以防止使用者執行那些產生意想不到的不好的影響的查詢。想想看在那麼大的資料量的前提下,如果我們在分割槽上表上使用查詢所有,或是使用了笛卡爾積查詢資料等等不良情況,那得花費我們多少時間和資源成本,Hive在預設情況下會開啟一種模
大資料技術原理與應用 第二章 大資料處理架構Hadoop 學習指南
本指南介紹Linux的選擇方案,並詳細指引讀者根據自己選擇的Linux系統安裝Hadoop。請務必仔細閱讀完廈門大學林子雨編著的《大資料技術原理與應用》第2章節,再結合本指南進行學習。Hadoop是基於Java語言開發的,具有很好跨平臺的特性。Hadoop的所要求系統環境適用於Windows,Linux,Ma