
大資料的倉庫Hive原理(三)
上次我們簡單說了一下Hive的工作原理,今天我們來深入看一下它是如何把Hql語句轉換為m/r來執行的。
1、編譯器
簡介
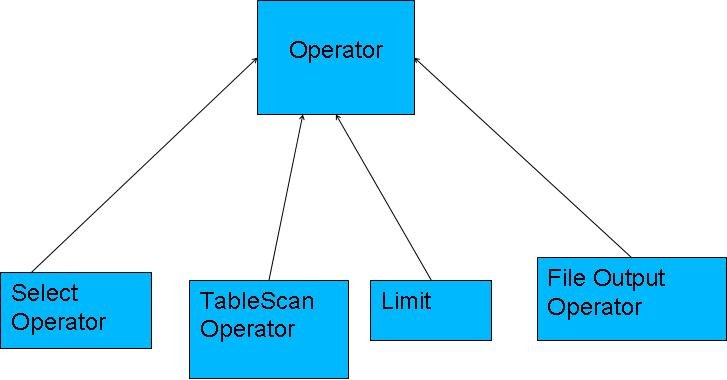
Hive編譯器將一個Hive QL轉換操作符。操作符Operator是Hive的最小的處理單元,每個操作符代表HDFS的一個操作或者一道MapReduce作業。
Operator都是hive定義的一個處理過程,其定義有:protected List <Operator<? extends Serializable >> childOperators; protected List <Operator<? extends Serializable >> parentOperators; protectedboolean done; // 初始化值為false所有的操作構成了Operator圖,hive正是基於這些圖關係來處理諸如limit, group by, join等操作。
執行流程
2、轉換過程
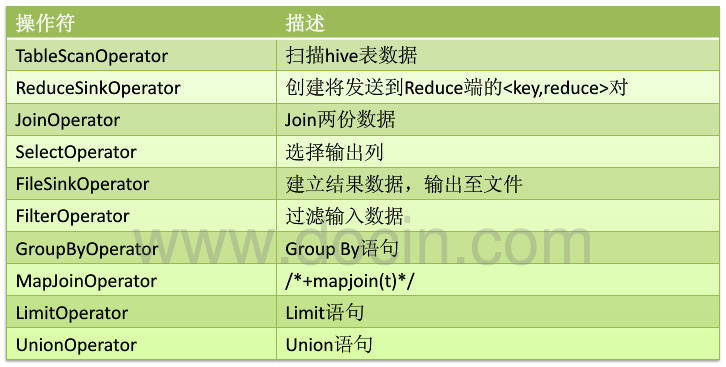
Antlr定義SQL的語法規則,完成SQL詞法,語法解析,將SQL轉化為抽象語法樹AST Tree遍歷AST Tree,抽象出查詢的基本組成單元QueryBlock遍歷QueryBlock,翻譯為執行操作樹OperatorTree邏輯層優化器進行OperatorTree變換,合併不必要的ReduceSinkOperator,減少shuffle資料量
遍歷OperatorTree,翻譯為MapReduce任務
物理層優化器進行MapReduce任務的變換,生成最終的執行計劃3、具體實現
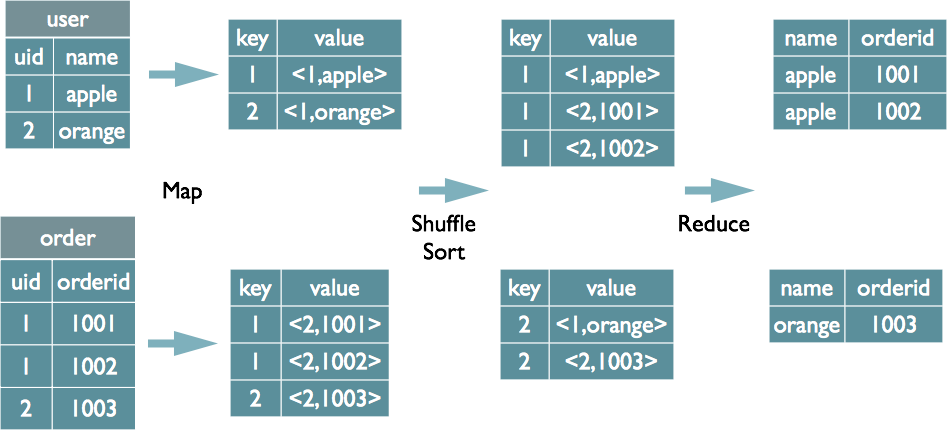
Join的實現原理
select u.name, o.orderid from order o join user u on o.uid = u.uid;在map的輸出value中為不同表的資料打上tag標記,在reduce階段根據tag判斷資料來源。MapReduce的過程如下(這裡只是說明最基本的Join的實現,還有其他的實現方式)
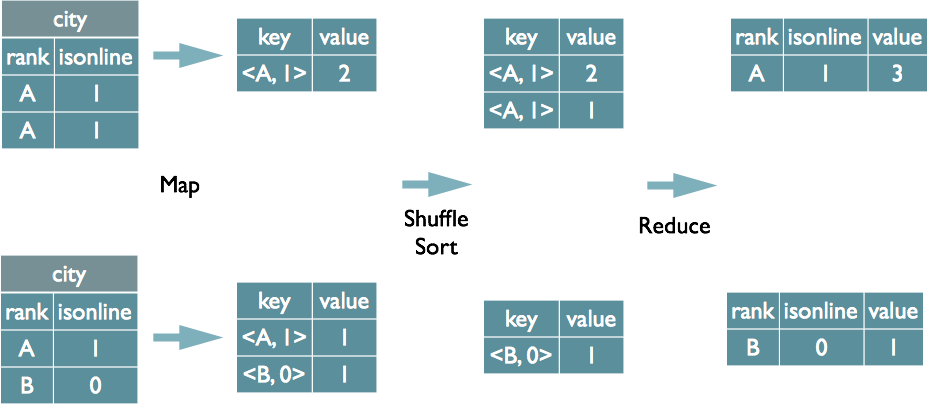
Group By的實現原理
select rank, isonline, count(*) from city group by rank, isonline;將GroupBy的欄位組合為map的輸出key值,利用MapReduce的排序,在reduce階段儲存LastKey區分不同的key。MapReduce的過程如下(當然這裡只是說明Reduce端的非Hash聚合過程)
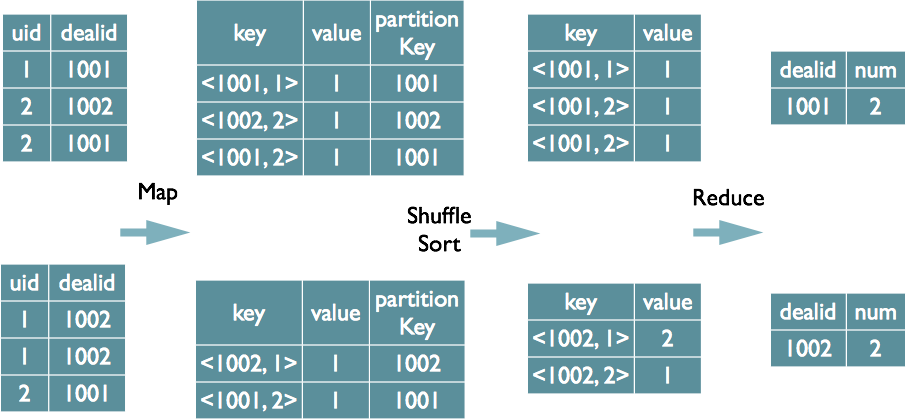
Distinct的實現原理
select dealid, count(distinct uid) num from order group by dealid;當 只有一個distinct欄位時,如果不考慮Map階段的Hash GroupBy,只需要將GroupBy欄位和Distinct欄位組合為map輸出key,利用mapreduce的排序,同時將GroupBy欄位作 為reduce的key,在reduce階段儲存LastKey即可完成去重
總結:
我們從認識Hive到理解它的執行原理,已經對其有了一定的瞭解。當然在實際應用中還會遇到各種問題,只要我們堅持去做,就沒有什麼做不到的。
相關推薦
大資料的倉庫Hive原理(三)
上次我們簡單說了一下Hive的工作原理,今天我們來深入看一下它是如何把Hql語句轉換為m/r來執行的。 1、編譯器 簡介 Hive編譯器將一個Hive
什麼是Hive——大資料倉庫Hive基礎
Hive是什麼: Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映成一張表,並提供類SQL查詢功能;其本質是將HQL轉化成MapReduce程式。 構建在Hadoop之上的資料倉庫: 使用HQL作為查詢介面
大資料的倉庫Hive原理(二)
上次我們說到了大資料應用中的資料倉庫hive,我們知道了利用hive可以更方便的處理資料,而且它的擴充套件性、延展性和容錯性都比較好,但是它是如何利用Hql(類Sql語句)來實現資料處
大資料環境---資料倉庫(hive+mysql+hadoop)的構建
前面已經配置好了叢集環境zookeeper,hadoop。 以及分散式資料庫hbase。 這個階段要開始構建資料倉庫的練習。涉及到的軟體: mysql, hive 。 背景: &nbs
大資料系列之資料倉庫Hive知識整理(四)Hive的嚴格模式,動態分割槽,排序,事務,調優
1.Hive的嚴格模式Hive提供了一個嚴格模式,可以防止使用者執行那些產生意想不到的不好的影響的查詢。想想看在那麼大的資料量的前提下,如果我們在分割槽上表上使用查詢所有,或是使用了笛卡爾積查詢資料等等不良情況,那得花費我們多少時間和資源成本,Hive在預設情況下會開啟一種模
大資料時代--Hive技術原理解析
本文旨在講解Hive的執行原理,幫助使用者更好的瞭解在使用的過程中它做了些什麼工作,深入的理解他的工作機制,提高開發人員理論層面的知識。後面會逐漸推出Hive使用、Hbase原理與使用等大資料專題類文
大資料資料倉庫——hive學習權威指南
學習hive權威指南目錄:ETL介紹大資料平臺架構概述系統資料流動hive概述hive在hadoop生態系統中hive體系結構hive安裝及使用hive客戶端的基本語句hive在HDFS檔案系統中的結構修改hive元資料儲存的資料庫hive操作命令hive常用配置hive常用
大資料開發----Hive(入門篇)
前言 本篇介紹Hive的一些常用知識。要說和網上其他manual的區別,那就是這是筆者寫的一套成體系的文件,不是隨心所欲而作。 本文所用的環境為: CentOS 6.5 64位 Hive 2.1.1 Java 1.8 Hive Arc
【大資料】Hive作者肯定進修過藍翔挖掘機
正經標題應該是:解決hive初始化mysql資料庫錯誤的一種方式 Hive安裝包下載地址: https://mirrors.tuna.tsinghua.edu.cn/apache/hive/ 事情原因是這樣的,我按照書上的步驟一步一步走,到了該用hiv
大資料之Spark(三)--- Spark核心API,Spark術語,Spark三級排程流程原始碼分析
一、Spark核心API ----------------------------------------------- [SparkContext] 連線到spark叢集,入口點. [HadoopRDD] extends RDD 讀取hadoop
大資料之scala(三) --- 類的檢查、轉換、繼承,檔案,特質trait,操作符,apply,update,unapply,高階函式,柯里化,控制抽象,集合
一、類的檢查和轉換 -------------------------------------------------------- 1.類的檢查 isInstanceOf -- 包括子類 if( p.isInstanceOf[Employee]) {
#18 資料倉庫(hive)和資料庫(mysql)有什麼區別?
資料倉庫(hive)和資料庫(mysql)的區別 資料庫(DB=Data Base) 資料倉庫(DW=Data Warehouse) (1)資料的型別 資料庫(mysql):線上交易資料 資料倉庫(hive):歷史資料 (2)
大資料平臺hive原生搭建教程
環境準備 centos 7.1系統 需要三臺雲主機: master(8) 作為 client 客戶端 slave1(9) 作為 hive server 伺服器端 slave2(10) 安裝 mysql server 安裝包使用的是官網下載的 將hive上傳到master ,mys
學習筆記:從0開始學習大資料-10. hive安裝部署
1. 下載 wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz 2.解壓 tar -zxvf hive-1.1.0-cdh5.15.1.tar.gz 3. hive的元資料(如表名,列
電商大資料分析平臺(三)nginx配置及flume讀取日誌資訊
一、nginx配置 在本專案中nginx的作用只是接收客戶端傳送的事件,並將相應的session寫入日誌檔案中,所以配置較為簡單,只需要配置寫入的日誌檔案和寫入的格式 1.地址配置 server { listen
大資料利用hive on spark程式操作hive
hive on spark 作者:小濤 Hive是資料倉庫,他是處理有結構化的資料,當資料沒有結構化時hive就無法匯入資料,而它也是遠行在mr程式之上
大資料8-Hive簡介和叢集搭建
1.Hive特點: 1.1可擴充套件性 :Hive可以自由的擴充套件叢集的規模,一般情況下不需要重啟服務; 1.2延展性:Hive支援使用者自定義函式,使用者可以根據自己的需求來實現自己的函式; 1.3容錯:良好的容錯性,節點出現問題,SQ
大資料離線---Hive的表操作介紹
這次我們主要針對hive的操作表做簡單的介紹: 託管表和外部表 分割槽和桶 這2個部分做簡介 Hive表格邏輯上有儲存的資料和描述表格中資料形式的相關元資料組成。資料一般儲存在HDFS上,也可以存放在本地檔案系統中。元資料存放在關係資料庫中。 1. 託管表
大資料之hive基礎理論
關於大資料 Hadoop是什麼 海量資料分散式的儲存和計算框架 資料儲存:HDFS: Hadoop Distributed File System 資料計算:YARN/MapReduce 1 hive 產生背景 hive定義: The Apache Hive ™
大資料之Hive概況與部署
Hive產生背景 (1)MapReduce程式設計不方便:開發、測試都不方便,需求變更 (2)傳統關係型資料庫人員的需要,資料庫存不下了,同時避開資料儲存在hdfs時上不得不用MapReduce來進行計算的麻煩,產生既能儲存資料又能處理分析資料的工具,就像使用s