
LCA的tarjan演算法的理解
阿新 • • 發佈:2019-02-08
tarjan演算法的步驟是(當dfs到節點u時):
1 在並查集中建立僅有u的集合,設定該集合的祖先為u
1 對u的每個孩子v:
1.1 tarjan之
1.2 合併v到父節點u的集合,確保集合的祖先是u
2 設定u為已遍歷
3 處理關於u的查詢,若查詢(u,v)中的v已遍歷過,則LCA(u,v)=v所在的集合的祖先
舉例說明(非證明):
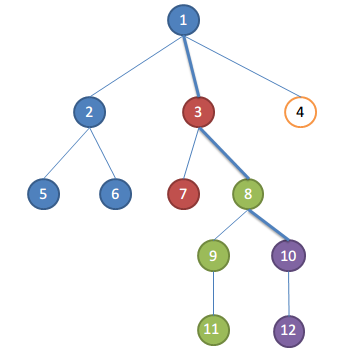
假設遍歷完10的孩子,要處理關於10的請求了
取根節點到當前正在遍歷的節點的路徑為關鍵路徑,即1-3-8-10
集合的祖先便是關鍵路徑上距離集合最近的點
比如此時:
1,2,5,6為一個集合,祖先為1,集合中點和10的LCA為1
3,7為一個集合,祖先為3,集合中點和10的LCA為3
8,9,11為一個集合,祖先為8,集合中點和10的LCA為8
10,12為一個集合,祖先為10,集合中點和10的LCA為10
你看,集合的祖先便是LCA吧,所以第3步是正確的
道理很簡單,LCA(u,v)便是根至u的路徑上到節點v最近的點
為什麼要用祖先而且每次合併集合後都要確保集合的祖先正確呢?
因為集合是用並查集實現的,為了提高速度,當然要平衡加路徑壓縮了,所以合併後誰是根就不確定了,所以要始終保持集合的根的祖先是正確的
關於查詢和遍歷孩子的順序:
wikipedia上就是上文中的順序,很多人的程式碼也是這個順序
但是網上的很多講解卻是查詢在前,遍歷孩子在後,對比上文,會不會漏掉u和u的子孫之間的查詢呢?
不會的
如果在剛dfs到u的時候就設定u為visited的話,本該回溯到u時解決的那些查詢,在遍歷孩子時就會解決掉了
這個順序問題就是導致我頭大看了很久這個演算法的原因,也是絮絮叨叨寫了本文的原因,希望沒有理解錯= =
int f[maxn],fs[maxn];//並查集父節點 父節點個數 bool vit[maxn]; int anc[maxn];//祖先 vector<int> son[maxn];//儲存樹 vector<int> qes[maxn];//儲存查詢 typedef vector<int>::iterator IT; int Find(int x) { if(f[x]==x) return x; else return f[x]=Find(f[x]); } void Union(int x,int y) { x=Find(x);y=Find(y); if(x==y) return; if(fs[x]<=fs[y]) f[x]=y,fs[y]+=fs[x]; else f[y]=x,fs[x]+=fs[y]; } void lca(int u) { anc[u]=u; for(IT v=son[u].begin();v!=son[u].end();++v) { lca(*v); Union(u,*v); anc[Find(u)]=u; } vit[u]=true; for(IT v=qes[u].begin();v!=qes[u].end();++v) { if(vit[*v]) printf("LCA(%d,%d):%d\n",u,*v,anc[Find(*v)]); } }
ref:
http://purety.jp/akisame/oi/TJU/
http://en.wikipedia.org/wiki/Tarjan%27s_off-line_least_common_ancestors_algorithm
http://techfield.us/blog/2008/11/lowest_common_ancester_tarjan_alogrithm/