
SMO演算法理解
SMO演算法看了近3遍感覺還是有點朦朦朧朧,模模糊糊。
所以索性,理解多少寫多少,避免遺忘。可能會有很多錯誤,歡迎指正。
主要基於李航的《統計學習方法》
SMO(sequential minimal optimization)序列最小最優化演算法
我們在討論支援向量機的學習問題時,可以將其轉換成求解凸二次規劃問題。實現支援向量機的學習是要找到這樣的凸二次規劃問題的全域性最優解,SMO就是支援向量機學習的一種快速演算法,也是一種啟發式演算法。
基本思路:
如果所有變數的解都滿足此優化問題的KKT條件,那麼這個最優化問題的解就得到了。(KKT條件是該最優化問題的充分必要條件)。否則,選擇兩個變數,固定其他變數,針對這兩個變數構建一個二次規劃問題。子問題的兩個變數,一個是違反KKT條件最嚴重的那一個,另一個由約束條件自動確定。如此,SMO演算法將原問題不斷分解為子問題求解,進而達到求解原問題的目的。[1]
特點:
將原始的二次規劃問題分解為只含有兩個變數的二次規劃子問題,對子問題不斷求解,使得所有的變數滿足KKT條件
包含兩部分:
1、求解兩個變數二次規劃的解析方法
2、選擇變數的啟發式方法
SMO演算法要解的是如下凸二次規劃的對偶問題:
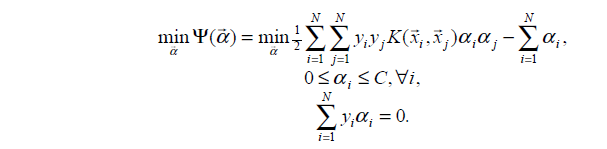
其中,K( ,)是核函式
兩個變數二次規劃的求解方法
1、SMO的最優化問題的子問題
前面提到將原始的二次規劃問題分解為只含有兩個變數的二次規劃子問題,所以假設選定兩個變數、
,其他變數相當於常數,省略常數後,SMO的最優化問題的子問題可以化簡成以下形式:

最終的優化目標是:
![]() ………… (1)
………… (1)
原來的約束條件變成:
s.t. (用
表示)…………(*)
還有
(注意,對於式子,我們在用
表示
時,等式兩邊同時乘
就可以,不要用除以
的方式,要時刻記住
=1)
2、視為一元函式,求導取極值
(1)式可以看成是一個二元函式,根據於和
的約束關係,可以把
消去。不過我們的目的是為了關於
求導,導數為0的點就是要找的極值點,所以這裡既可以把
消去後對
求導,也可以直接在現在這個式子上對
求導。
根據(*)式得
![]() …………(2)
…………(2)
代入(1)式中,可以看成是一個一元函式
用來表示最優化的目標,將
帶入得到
對上式中的求導等於0
![]() …………(3)
…………(3)
借用參考3中部落格解析

把(4)(6)(7)式帶入到(3)式中去,並進行化簡
其中
得到…………(8)
3、對原始解進行裁剪
裁剪的問題,部落格2裡得部分講的很詳細(具體的就不貼出來,請參看最後的參考博文連結)
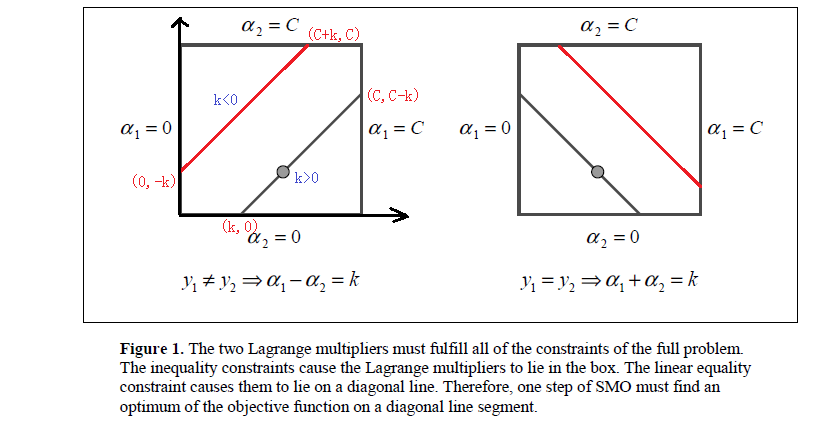
對約束條件對應的*式,考慮兩種情況,分別如上圖所示。
需要滿足約束條件
,所以最優值
的取值範圍也要滿足條件
L和H分別是坐在的對角線段端點的界。
當時,
的可行域為
,區間端點分別為:
,
當時,
的可行域為
,區間端點分別為:
,
所以在更新時,要先求出
的可行域,然後用之前的那個公式求出極值點
,然後看極值點
處的在不在可行域範圍內,在的話就使用極值點處的
,不在的話就使用邊界值H或者L更新,具體更新規則為:

4、求解
由於只有兩個變數,根據
可以求得…………(9)
其他一些內容涉及到論文《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》
等看完再補充
選擇變數的啟發式方法
1、第1個變數的選擇
SMO稱第1個變數的選擇稱為外迴圈。外迴圈在訓練樣本中選取違反KKT條件最嚴重的樣本點,將其作為第一個變數。
遍歷的時候首先遍歷滿足的樣本點,也就是在間隔邊界上的支援向量點,檢驗是否滿足KKT條件;
如果都滿足,那麼遍歷整個訓練集,檢驗是否滿足KKT條件。

2、第2個變數的選擇
SMO稱第2個變數的選擇稱為內迴圈。在找到第一個變數的基礎上,第二個變數的標準是希望能使有足夠大的變化。
由上述的(8)式,是依賴於|E1−E2|,為了加快計算的速度,做簡單的就是選擇|E1−E2|最大時的
當E1為正時,那麼選擇最小的Ei作為E2;如果E1為負,選擇最大Ei作為E2。
為了節省時間,通常為每個樣本的Ei儲存在一個列表中,選擇最大的|E1−E2|來近似最大化步長。
3、計算閾值b和差值
這一部分還沒理解。空著先……
參考:
1、李航的《統計學習方法》