
相似性度量--Pearson相關係數
Pearson 相關係數
Pearson 相關係數介紹
pearson是一個介於-1和1之間的值,用來描述兩組線性的資料一同變化移動的趨勢。
當兩個變數的線性關係增強時,相關係數趨於1或-1;當一個變數增大,另一個變數也增大時,表明它們之間是正相關的,相關係數大於0;如果一個變數增大,另一個變數卻減小,表明它們之間是負相關的,相關係數小於0;如果相關係數等於0,表明它們之間不存線上性相關關係。
用數學公式表示,皮爾森相關係數等於兩個變數的協方差除於兩個變數的標準差。

協方差(Covariance):在概率論和統計學中用於衡量兩個變數的總體誤差。如果兩個變數的變化趨於一致,也就是說如果其中一個大於自身的期望值,另一個也大於自身的期望值,那麼兩個變數之間的協方差就是正值;如果兩個變數的變化趨勢相反,則協方差為負值。
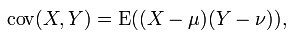
其中u表示X的期望E(X), v表示Y的期望E(Y)
由於pearson描述的是兩組資料變化移動的趨勢,所以在基於user-based的協同過濾系統中,經常使用。描述使用者購買或評分變化的趨勢,若趨勢相近則pearson係數趨近於1,也就是我們認為相似的使用者。
Pearson 相關係數的缺陷
直觀的可以看出,pearson不適用於文字的相似性分析。
pearson存在以下3個問題: 以下圖的資料作為測試用例
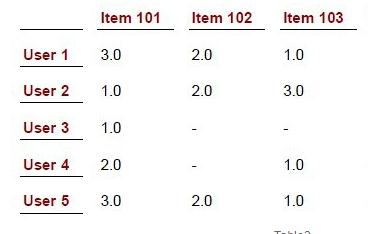
1. 未考慮重疊記錄項的數量對相似度的影響
上表中,行表示使用者(1~5)對專案(101~103)的一些評分值。直觀來看,User1和User5用3個共同的評分項,並且給出的評分趨勢相
同,User1與User4只有2個相同評分項,雖然他們的趨勢也相似,但是由於102的未知,可能是User2對102未發生行為,或者對102很討厭,所以我們更希望User1和User5更相似,但結果是User1與User4有著更高的結果。
可以看出pearson係數只會對重疊的記錄進行計算。
同樣的場景在現實生活中也經常發生,比如兩個使用者共同觀看了200部電影,雖然不一定給出相同或完全相近的評分,但只要他們之間的趨勢相似也應該比另一位只觀看了2部相同電影的相似度高!但事實並不如此,如果對這兩部電影,兩個使用者給出的相似度相同或很相近,通過Pearson相關性計算出的相似度會明顯大於觀看了相同的200部電影的使用者之間的相似度。
2.如果只有一個重疊項則無法計算相關性
從數學上講,若只有一個重疊的記錄,那麼至少有一組記錄的標準差為0,導致分母為0
從這一點也可以看出,pearson係數不適用與小的或者非常稀疏的資料集。當然,這一特性也有它的好處,無法計算pearson係數可以認為這兩組資料沒有任何相關性。
3.如果一組記錄的所有評分都一樣則無法計算相關性
理由同2.
4.Pearson係數對絕對數值不敏感
考慮這三組資料,1:(1.0,2.0,3.0,4.0),2:(40.0,50.0,70.0,80.0),3:(50.0,60.0,70.0,80.0),我們可以直觀的認為2和3更為相似,它們的重疊評分數目一致,趨勢也相同,記錄1雖然也滿足上述的條件,但是它整體數值很低。在現實中,有人習慣於給出更高的評分,而有人則恰恰相反。
利用pearson計算它們之間的相似度為:
1&2: 0.9899494936611665
2&3: 0.9899494936611665
1&3: 0.9999999999999999
可以看出pearson係數對絕對數值並不敏感,它確實只是描述了兩組資料變化的趨勢。