
推薦演算法——基於矩陣分解的推薦演算法
一、推薦演算法概述
對於推薦系統(Recommend System, RS),從廣義上的理解為:為使用者(User)推薦相關的商品(Items)。常用的推薦演算法主要有:
- 基於內容的推薦(Content-Based Recommendation)
- 協同過濾的推薦(Collaborative Filtering Recommendation)
- 基於關聯規則的推薦(Association Rule-Based Recommendation)
- 基於效用的推薦(Utility-Based Recommendation)
- 基於知識的推薦(Knowledge-Based Recommendation)
- 組合推薦(Hybrid Recommendation)
在推薦系統中,最重要的資料是使用者對商品的打分資料,資料形式如下所示:
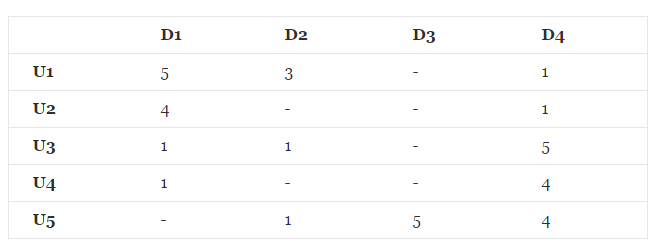
其中,
在推薦系統中有一類問題是對未打分的商品進行評分的預測。
二、基於矩陣分解的推薦演算法
2.1、矩陣分解的一般形式
矩陣分解是指將一個矩陣分解成兩個或者多個矩陣的乘積。對於上述的使用者-商品矩陣(評分矩陣),記為
其中,矩陣
2.2、利用矩陣分解進行預測
在上述的矩陣分解的過程中,將原始的評分矩陣
那麼接下來的問題是如何求解矩陣
2.2.1、損失函式
可以使用原始的評分矩陣
最終,需要求解所有的非“-”項的損失之和的最小值:
2.2.2、損失函式的求解
對於上述的平方損失函式,可以通過梯度下降法求解,梯度下降法的核心步驟是
- 求解損失函式的負梯度:
相關推薦
推薦演算法——基於矩陣分解的推薦演算法
一、推薦演算法概述 對於推薦系統(Recommend System, RS),從廣義上的理解為:為使用者(User)推薦相關的商品(Items)。常用的推薦演算法主要有: 基於內容的推薦(Content-Based Recommendation) 協同過濾
簡單的基於矩陣分解的推薦演算法-PMF, NMF
介紹: 推薦系統中最為主流與經典的技術之一是協同過濾技術(Collaborative Filtering),它是基於這樣的假設:使用者如果在過去對某些專案產生過興趣,那麼將來他很可能依然對其保持熱忱。其中協同過濾技術又可根據是否採用了機器學習思想建模的不同劃分為基於記憶體的協同過濾(Memory-based
基於矩陣分解的推薦演算法(java程式碼實現)
目前推薦系統中用的最多的就是矩陣分解方法,在Netflix Prize推薦系統大賽中取得突出效果。以使用者-專案評分矩陣為例,矩陣分解就是預測出評分矩陣中的缺失值,然後根據預測值以某種方式向用戶推薦。常見的矩陣分解方法有基本矩陣分解(basic MF),正則化矩
基於矩陣分解的電影推薦演算法(使用Tensorflow實現)
#!/usr/bin/env python # -*- coding:utf-8 -*- # 文中部分參考了: # https://blog.csdn.net/u012845311/article/details/77183491 # 改進:要劃分訓練集和測試集,並在進行模型
基於矩陣分解的推薦演算法
一個真正強大的人,不會把太多心思花在取悅和親附別人上面。所謂圈子、資源,都只是衍生品。最重要的是提高自己的內功。只有自己修煉好了,才會有別人來親附。自己是梧桐,鳳凰才會來棲;自己是大海,百川才來匯聚,花香自有蝶飛來。你只有到了那個層次,才會有相應的圈子,而不是倒過來!
推薦系統-基於鄰域的演算法
最近在看項亮的《推薦系統實踐》,文章只有只有程式碼片段,沒有完整的程式碼。所以在原有程式碼之上,根據書籍介紹的內容,還原了部分程式碼。 UserCF演算法(基於使用者的協同過濾演算法): 令N(u)表示使用者u的正反饋的物品集合,令N(v)表示使用者v的正反
好友推薦演算法-基於關係的推薦
最近在搞社交網路的演算法,前面簡單敘述了pagerank的相關以及graphx的實現,現在簡單介紹好友推薦演算法,每當我們在QQ的新增好友等的時候,下面總會出現騰訊推薦給我們的好友,你會發現推薦的好友大多都是你某個好友的好友(即二度好友),而且其中還有一些比較詳
機器學習->推薦系統->基於圖的推薦演算法(PersonalRank)
本博文將介紹PersonalRank演算法,以及該演算法在推薦系統上的應用。 將使用者行為資料用二分圖表示,例如使用者資料是由一系列的二元組組成,其中每個元組(u,i)表示使用者u對物品i產生過行為。 將個性化推薦放在二分圖模型中,那麼給使用者u推薦物品
個性化推薦演算法------基於內容的推薦和基於鄰域的協同過濾
這篇文章主要討論了個性推薦演算法中,基於內容推薦和基於鄰域的協同過濾推薦的分析比較。 資料集:使用者對電影的歷史評價記錄,只有喜歡與不喜歡,喜歡用1表示,不喜歡用2表示,格式如下: 使用者歷史電影評分
推薦系統:矩陣分解與鄰域的融合模型
critical with 分析 但是 rac 公式 download pearson 情況 推薦系統通常分析過去的事務以建立用戶和產品之間的聯系,這種方法叫做協同過濾。 協同過濾有兩種形式:隱語義模型(LFM),基於鄰域的模型(Neighborhood models)。
推薦系統ALS矩陣分解
矩陣分解模型的物理意義 我們希望學習到一個P代表user的特徵,Q代表item的特徵。特徵的每一個維度代表一個隱性因子,比如對電影來說,這些隱性因子可能是導演,演員等。當然,這些隱性因子是機器學習到的,具體是什麼含義我們不確定。 學習到P和Q之後,我們就可以直接P乘以Q就可以預測所有user對ite
mahout基於矩陣分解的協同過濾例項 ALS——WR
問題提出:對於協同過濾,我們就是要預測使用者所喜歡的但是又沒有發現的物品,下面給出一個明確的評分矩陣,設為A,但是A有一部分沒有值,表明使用者沒有對此物品評分,於是我們需要預測出沒有值的評分部分。 解決方法: 我們知道有基於使用者和基於物品的協同過濾演算法,
複雜網路社群結構發現演算法-基於igraph 標籤傳播演算法
【前言】 繼續我們本系列對複雜網路社群結構的方法探索,之前已經嘗試過spark上標籤傳播演算法、igraph 中隨機遊走演算法、networkx中的clique滲透演算法(見筆者相關文章),但一直侷限於無向、無權重圖的分析。本次,向前邁一步,引入權重。選用了
[吳恩達機器學習筆記]16推薦系統5-6協同過濾演算法/低秩矩陣分解/均值歸一化
16.推薦系統 Recommender System 覺得有用的話,歡迎一起討論相互學習~Follow Me 16.5 向量化:低秩矩陣分解Vectorization_ Low Rank M
【筆記3】用pandas實現矩陣資料格式的推薦演算法 (基於使用者的協同)
原書作者使用字典dict實現推薦演算法,並且驚歎於18行程式碼實現了向量的餘弦夾角公式。 我用pandas實現相同的公式只要3行。 特別說明:本篇筆記是針對矩陣資料,下篇筆記是針對條目資料。 ''' 基於使用者的協同推薦 矩陣資料 ''' import pandas as pd from io impor
推薦演算法之用矩陣分解做協調過濾——LFM模型
隱語義模型(Latent factor model,以下簡稱LFM),是推薦系統領域上廣泛使用的演算法。它將矩陣分解應用於推薦演算法推到了新的高度,在推薦演算法歷史上留下了光輝燦爛的一筆。本文將對 LFM原理進行詳細闡述,給出其基本演算法原理。此外,還將介紹使得隱語義模型聲名大噪的演算法FunkSVD和在其基
PersonalRank-基於圖的推薦演算法
演算法介紹 在推薦系統中,使用者行為資料可以表示成圖的形式,具體來說是二部圖。使用者的行為資料集由一個個(u,i)二元組組成,表示為使用者u對物品i產生過行為。本文中我們認為使用者對他產生過行為的物品的興趣度是一樣的,也就是我們只考慮“感興趣”OR“不感興趣”。假設有下圖所示的行為資料集。
基於內容的推薦演算法的實現程式碼例項
本次例項需要三個資料檔案 分別為節目及其所屬標籤型別的01矩陣;使用者--節目評分矩陣;使用者收視了的節目--標籤01矩陣。 可以直接下載下來使用https://download.csdn.net/download/qq_38281438/10757266 具體程式碼如下: #
基於使用者的協同過濾演算法實現的商品推薦系統
基於使用者的協同過濾演算法實現的商品推薦系統 專案介紹 商品推薦是針對使用者面對海量的商品資訊而不知從何下手的一種解決方案,它可以根據使用者的喜好,年齡,點選量,購買量以及各種購買行為來為使用者推薦合適的商品。在本專案中採用的是基於使用者的協同過濾的推薦演算法來實現
從零開始學推薦系統一:基於鄰域的演算法
本系列文章會從最簡單的推薦系統到目前主流的推薦系統解決方案做總結。 1. 基於鄰域的演算法 基於鄰域的演算法是推薦系統中最基本的演算法,在業界得到了廣泛應用。基於鄰域的演算法分為兩大類,一類是基於使用者的協同過濾演算法,另一類是基於物品的協同過濾演算法。 1.1 基於使用者的協同過濾演算法(UserCF