
如何通過各種資料探勘運維價值
關於作者
溫崢峰,百田資訊運維技術專家,DevOps team leader,運維自動化平臺負責人,曾就職於網易遊戲,專注於 運維自動化建設、DevOps實踐 與 海量遊戲技術運營。知乎ID @Hi峰兄
前言
改進一個功能是否真的有效果,需要資料說話;
一個運維操作是否有效果,也需要資料說話;
杜絕拍腦袋,資料為王。
「可量化」是一個嚴謹的技術人員需要追求的客觀準則,用一個更加高階的詞彙來描述是「可計價」。
一切行為都是有價值的,特別是對線上環境的各種的運維操作、變更,會造成怎樣的影響,我們如何判斷其價值所在?
作者之前所寫的《中小型運維團隊如何設計運維自動化系統》https://
在運維自動化體系裡面,資料是一個非常核心且是承上啟下的重要元素,它即可以反映運維服務的效率、故障比例、高可性,也可以衡量業務運維狀態的穩定性、成本、速度、質量等。
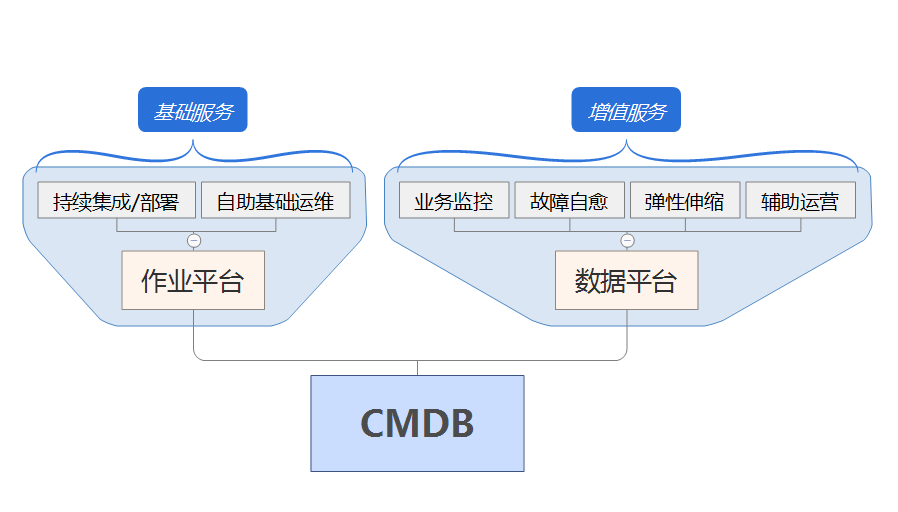
而且在前文的最後部分,就有一個利用作業平臺執行資料來挖掘運維價值的例子,因為和本文主題相關,所以也推薦給讀者,這兩個例子分別是關於運維人力價值和故障分析價值。
除此之外,怎樣利用資料來提供運維團隊的增值服務,本文通過幾個實戰例子來描述說明。
技術棧的選擇
關於資料收集、處理和展示,業界比較常見的技術棧主要這幾類:
第一類是著名的ELK,即 Elasticsearch、Logstash、Kibana(或者EFK,F 是 Fluentd 代替 Logstash,畢竟Logstash因效能問題所以口碑不咋的);
第二類是 Flume + Kafka + Storm,Java系的技術團隊會比較傾向選用這套工具集;
還有一類比較少見的是用 Scribe 作為收集工具;
以上是主流的技術選型方案,但本文的重點不是介紹各種資料分析技術的優缺點,這是屬於「怎麼做」。
本文的主要目的是介紹「做什麼」,哪些資料值得我們分析?以及資料背後價值是什麼?
因為通常來說分析這類資料在技術上都不會存在多大的障礙,有各種現成的開源的技術解決方案可以供我們隨意選擇。
但是如何挖掘自家業務該有哪些資料值得分析卻沒有一個統一的業界標準或者參考,更多的是需要運維工程師深入理解自家業務後,通過系統運維技術加上業務運營理解的雙重緯度結合才能得出一套比較完整、立體化、精細化的分析方法。
業務的誕生過程
一個站點或者App,大致經歷著這樣的誕生過程:PM設計出產品原型,交給 Dev 開發實現,最後交付給 Ops 部署到線上執行,最後供使用者使用。
在這幾個簡單步驟中卻涉及了眾多的人、角色、交付等物件,這是一個完整、複雜的系統工程,而任意一個環節的失誤都可能影響最終呈現給使用者的體驗以及效果。
但是我們卻不可能一個個子步驟都去加監控、加資料分析,這樣做是非常吃力不討好的事情,甚至會產生很多監控冗餘的情況,所以我們要做的是抓住核心指標。
什麼是監控冗餘
隨著我們的業務發展慢慢變得龐大、複雜,其需要監控的點會變得越來越多,如果我們對每個環節、每個元件可能的異常都做對應的監控,那麼一臺host可能會要有數十個監控項,這是不太科學的做法。監控的意義在於迅速發現問題,如果存在過多的冗餘監控,可能會影響運維人員對於告警的敏感性。例如每天好幾百條告警簡訊接收下來,又沒有非常準確地發現真正的故障情況的話,這個告警就沒有存在的意義。
我們該如何監控,首先是找到核心指標。
什麼是核心指標?對於不同角色會有不同的側重點:
- 對於PM:PV、UV、日活、月活、ARPU等
- 對於Dev:Bug、TPS、QPS、JVM、訊息佇列 等
- 對於Ops:服務可用性、機器負載、頻寬流量 等
以上都是核心指標,但是缺偏偏少關注了一個重要角色--使用者,對於使用者來說,他們不會關心站點的PV、日活,也不會關心TPS,更加不會關心我們線上用了多少機器多少頻寬。
使用者只關注我們的業務產品更否提供穩定的、快速的、高質量的服務,用通俗的語言來描述,就是我開啟網站是否秒開,登入app是否秒進,購物付款是否快速完成等等。
從使用者的角度分析問題,才算是真正的通過運維技術加上運營理解來保證服務的高效穩定執行,這就是所謂的技術運營需要關注的。
那麼問題來了,到底什麼才是使用者關注的核心指標?
不同業務形態有不同的使用者關注指標:
- 對於資訊類站點(例如入口網站等):首屏時間、完整首頁時間
- 對於電商類站點:首屏時間、登入時間、付款時間
- 對於頁遊:首屏時間、登入時間、進服時間
- 對於手遊:啟動時間、登入時間、進服時間
這需要不同業務形態的運維工程師從使用者角度來分析,通過技術手段來挖掘、定位出一些核心的步驟,然後在這些核心步驟作出可監控的方法,如 URL撥測、服務端監控API、頁面JS被動檢測等方式。
業務監控
前面鋪墊了那麼多內容,目的就是要引出業務監控這個概念。
監控的作用是對業務具有全面的診斷能力,按各種層次各種維度的監控方法,建立一套立體的監控模型,對影響業務的各個核心資料指標進行採集、分析、建模、展示、處理,最終得到一套可量化可計價的業務執行狀況,以確保業務正常穩定執行以及最佳的使用者體驗效果。
而監控的工具很多,如 zabbix、nagios 等,是否用這些工具就夠了呢?
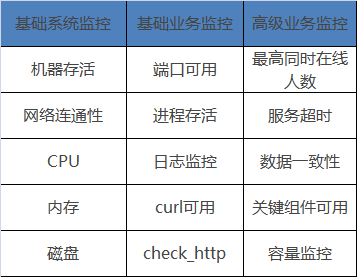
一般運維團隊都可以做到基礎系統和基礎業務監控,然而高階業務監控才是衡量運維團隊能力水平的指標。
業務監控--PCU
【最高同時線上人數】即 PCU(Peak Concurrent Users),對遊戲專案來說是標配的關鍵業務監控項,該指標在運營角度反映了遊戲業務的受歡迎程度,在系統運維的角度反映了整個線上環境的執行負載狀態如伺服器機器的負載情況、網路頻寬使用情況、資料庫的壓力情況等。
一般PCU資料都可以從業務資料庫或者後端API獲得,然後在運維平臺通過圖表展示,但是這個資料只是展示出來供運維偶爾看看的話,就沒發揮到它的真正作用。
歷史對比
可以把 PCU 和歷史對比,如上週同期、上月同期 或者 去年同期。通過對比可以根據偏差值自動判斷 PCU 是否有異常,有異常則告警通知運維同事review線上環境情況。
對於偏差值的閾值設定需要比較複雜的判斷,比如歷史同期是公眾假期或者寒暑假會使得 PCU 劇增,或者 PCU 本來偏低(如100以下)則不能按百分比來作判斷條件等等。
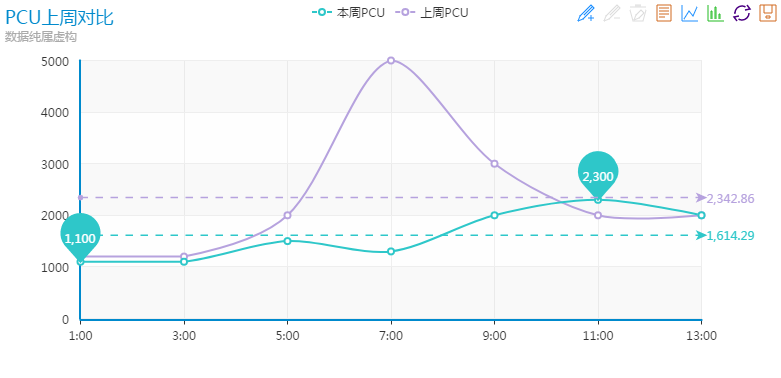
如圖所示,紫色線為上週PCU,綠色線為當天PCU,可以看出在7:00有個異常的下降,通過平臺自動判斷並告警通知,當然實際的監控時間粒度可以設定為1分鐘或者5分鐘,讓監控更加及時且不會太影響系統性能。
舉一反三,其實不止 PCU 這個數值可以這樣利用,還有其他如新增註冊人數、新增登入人數等也可以用類似的方法來分析。
業務監控--模擬使用者行為
一個網際網路產品可以看作由一系列獨立且具有特定功能的模組組合而成,這些模組間的相互作用構成了整個產品的所有功能。而任意模組的故障都會影響整個業務的正常執行,所以我們都會對產品的關鍵模組會重點關注。
對於關鍵模組,我們可以要求 Dev 提供監控介面,通過 curl 或者 API 的形式,定期獲取響應碼以及響應時間,儲存歷史資料並製作圖表。
監控介面應該是完整的,可以模仿使用者行為的,比如一個電商站點,一個使用者必然會做這些操作:
- 註冊
- 登入
- 新增購物車
- 生成訂單
- 付款
這些步驟都屬於使用者級別的核心體驗指標,必須提供相應的監控介面供運維長期監控其正常執行,監控資料也需要視覺化處理,任何異常都能直接通過圖表反映出來,後期也根據實際情況建立相應指標的告警模型和容量管理模型。
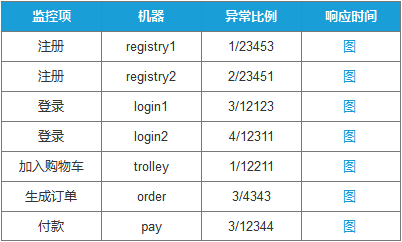
點選某個監控項的圖,可以看到具體的響應時間監控曲線
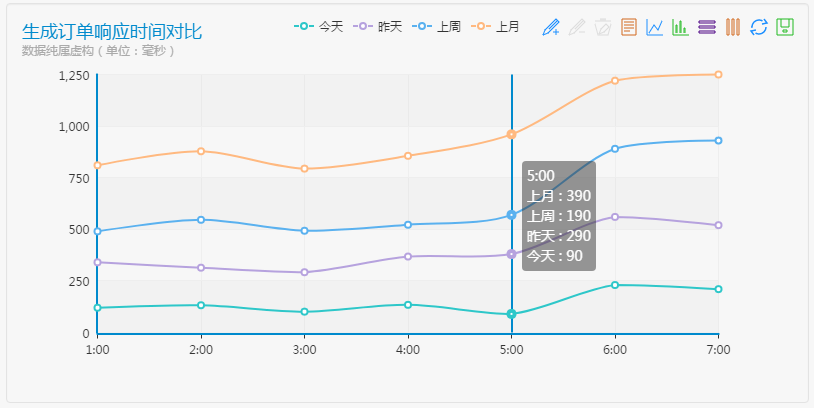
業務監控--使用者來源分析
使用者來源分析也是一個非常實用的業務級監控,通過各種客戶端技術獲取使用者真實IP,如果是通過HTTP協議則需要 x-forwarded-for 來跟蹤使用者的真實IP,收集好IP資訊和使用者對應關係後,通過資料分析IP庫得出使用者所在地區、ISP等資訊,然後就可以得出我們實際業務的當前使用者地區、ISP分佈圖,然後結合中國地圖前端控制元件製造圖表。
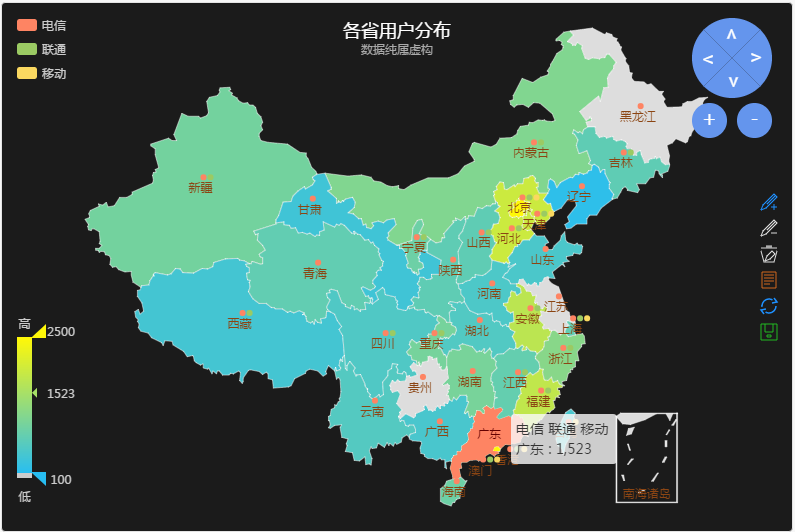
只是展示還是不夠的,還要結合類似前面例子的歷史對比方法,如果發現某省份或者某ISP的使用者比上個對比周期劇減了,那就反映了當地骨幹網、DNS或者CDN等發生故障,讓運維工程師可以迅速定位故障源頭。
智慧伸縮 與 輔助運營
輔助運營的說法是運維業界近幾年才提出來的,以往的輔助運營的工作一般是交給BI資料團隊負責,他們把線上資料收集分析並出報表,得到 日活、月活、各種留存率、ARPU
等業務資料供 PM 或者運營同事分析並做業務決策。其實運維部門也可以用技術方法輔助運營,下面就用遊戲專案的開服合服作為實踐例子。
遊戲行業經常有開服、合服的操作,用通用的說法就是擴容和縮容,因為一個遊戲的生存週期很短,從內測、公測、引入期、成長期、成熟期到衰退期說不定總共就一兩年的時間,擴容和縮容操作的高效、快速反映了運維團隊的服務能力,也對公司的運營成本節約有著重大的意義。
開服,即擴容的操作一般經常發生在引入期和成長期;合服,一般是在成熟期和衰退期。
開新服是遊戲運營中的一種刺激玩家人數增長的良好手段,因為在老服中排名相對一般的玩家,去新服往往可以獲得更多的進步空間和利益,刺激使用者消費來換取使用者成就感。
而合併老伺服器,可以把N個活躍人數較低的鬼服組合在一起重新煥發生命力,遊戲必須基於一定的人數才能完全體現遊戲價值,這樣使用者才有繼續升級的慾望。
開服策略
那麼怎樣選擇最佳的開服時間呢,運維部門怎樣利用技術手段協助判斷?
根據運營策略,開服的最佳時間是使用者登入數最高的時間段,因為這樣使用者才更高的概率發現有新服開了並進入新服。
在前面的業務監控部分,我們已經掌握了各種業務指標資料,當然必須包含使用者登陸數這個重要資料。
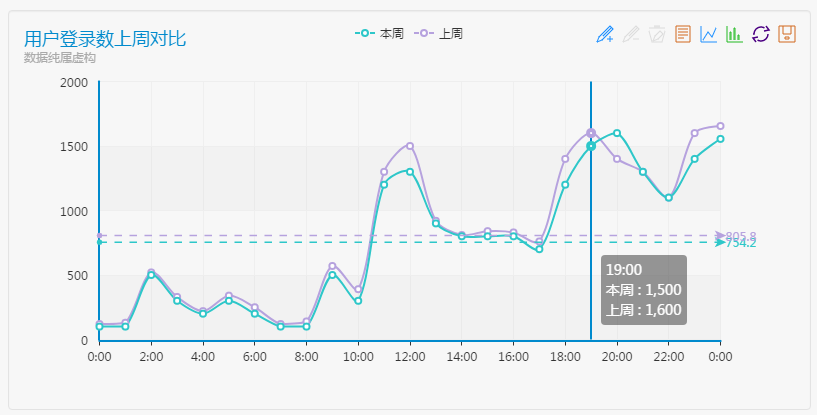
可以看出,對於手游來說使用者登入數在12點、19點以及23點左右都有一個峰值出現,分別對應午休、下班和臨睡覺的三個時刻,我們該如何選擇呢?
一般在開服前,運維工程師已經對機器初始化完畢,並部署好業務程式碼,聯調各種輔助系統並交給QA測試。測試完畢後會經過清檔、業務活動配置、再次測試等流程。
這些環節都需要技術同事和運營同事共同參以確保整個流程正確無誤,所以開服時間理論上放在工作時間會比較好,因為這個時間大家都在公司可以更好地溝通交流。
如果遊戲是聯運專案還需要和第三方供應商聯調,就更加需要在雙方都線上的時間比較好,否則一旦出現異常情況就會影響處理的響應時間。
綜上,開新服時間要麼定在12點要麼在19點比較合適,至於具體的精確時間,可以根據歷史峰值所在的時刻自動觸發即可,這在技術層面很容易實現。
合服策略
對比開服,合服是一個更加複雜的業務操作,能否正確選擇哪些服該合併既反映了運營人員的業務水平的高低,也對公司的業務運營情況有正面促進的作用。
我們也可以通過系統運維的角度來協助分析,利用資料指標來給他們提供更優的選擇。
合服需要考慮的指標大概有以下兩大類:業務指標和系統指標。
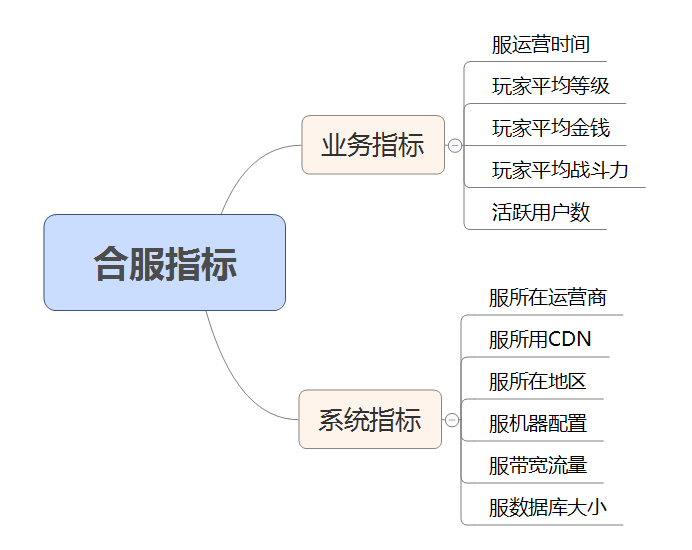
其中業務指標大多數需要通過業務資料庫統計獲得,而系統指標需要根據 CMDB 的各種資訊統計,最終可以匹配出一系列適合合服的服列表資訊。
至於具體的判斷演算法和評判標準,需要和 運營、開發 等業務部門同事反覆討論確定,因為各家業務情況不同,這裡不多作展開。
總結
怎樣才能挖掘到有用的資料,其核心指導思想是運維工程師要從使用者以及業務運營的角度思考問題,再結合自身的技術思維角度,完善出一套科學且精細化的資料分析方法。
我們可以看出上面例子在實踐中並沒有很高的技術門檻,只是需要我們稍微具備一些業務方面的產品優化或者運營策略知識即可,只要運維部門走出一小步,就可以為整個業務團隊作出非常大的貢獻。

另外,在現在雲端計算技術的普及,讓大多數中小型企業瞬間具備了彈性計算的能力,讓運營成本利用率最大化和使用者體驗價值最優化都有了可落地的技術基礎。
我們緊接下來可以繼續思考以下內容:
- 線上伺服器以及頻寬等硬體資源是否已經達到最優利用率?我們有沒有可量化的分析方法並持續優化?
- 業務是否有不科學的功能點在極度浪費線上硬體成本資源或者對使用者體驗不佳,運維部門如何量化並反饋業務部門整改?
如果運維團隊能做到以上內容,我們的定位就不再是一個支撐後勤崗位,不再是成本中心,而是作為一個可以理解運營策略且可以為業務部門作出價值貢獻的核心環節。