
Matlab數學建模學習報告(一)
一、學習目標。
(1)瞭解Matlab與數學建模競賽的關係。
(2)掌握Matlab數學建模的第一個小例項—評估股票價值與風險。
(3)掌握Matlab數學建模的迴歸演算法。
二、例項演練。
1、談談你對Matlab與數學建模競賽的瞭解。
Matlab在數學建模中使用廣泛:MATLAB 是公認的最優秀的數學模型求解工具,在數學建模競賽中超過 95% 的參賽隊使用 MATLAB 作為求解工具,在國家獎隊伍中,MATLAB 的使用率幾乎 100%。雖然比較知名的數模軟體不只 MATLAB。
人們喜歡使用Matlab去數學建模的原因:
(1)MATLAB 的數學函式全
(2)MATLAB 足夠靈活,可以按照問題的需要,自主開發程式,解決問題。
(3)MATLAB易上手,本身很簡單,不存在壁壘。掌握正確的 MATLAB 使用方法和實用的小技巧,在半小時內就可以很快地變成 MATLAB 高手了。
正確且高效的 MATLAB 程式設計理念就是以問題為中心的主動程式設計。我們傳統學習程式設計的方法是學習變數型別、語法結構、演算法以及程式設計的其他知識,因為學習時候是沒有目標的,也不知道學的知識什麼時候能用到,收效甚微。而以問題為中心的主動程式設計,則是先找到問題的解決步驟,然後在 MATLAB 中一步一步地去實現。在每步實現的過程中,遇到問題
數學建模競賽中的 MATLAB 水平要求:
要想在全國大學生數學建模競賽中拿到國獎, MATLAB 技能是必備的。 具體的技能水平應達到:
1)瞭解 MATLAB 的基本用法,包括幾個常用的命令,如何獲取幫助,指令碼結構,程式的分節與註釋,矩陣的基本操作,快捷繪圖方式;
2)熟悉 MATLAB 的程式結構,程式設計模式,能自由地建立和引用函式(包括匿名函式);
3)熟悉常見模型的求解演算法和套路,包括連續模型,規劃模型,資料建模類的模型;
4)能夠用 MALTAB 程式將機理建模的過程模擬出來,就是能夠建立和求解沒有套路的數學模型。
要想達到如上要求, 不能按照傳統的學習方式一步一步地學習, 而要結合上述提到的學習理念制定科學的訓練計劃。
2、已知股票的交易資料:日期、開盤價、最高價、最低價、收盤價、成交量和換手率,試用某種方法來評價這隻股票的價值和風險。如何用MATLAB去求解該問題?(交易資料:點選此處獲取資料)
解題步驟:
第一階段:從外部讀取資料
Step1.1:把資料檔案sz000004.xls拖曳進‘當前資料夾區’,選中資料檔案sz000004.xls,右鍵,將彈出右鍵列表,很快可發現有個“匯入資料”選單,如圖 1 所示。

圖1. 啟動匯入資料引擎示意圖
Step1.2:單擊“匯入資料”這個按鈕,則很快發現起到一個匯入資料引擎,如圖 4 所示。

圖2. 匯入資料介面
Step1.3:觀察圖 2,在右上角有個“匯入所選內容”按鈕,則可直接單擊之。馬上我們就會發現在 MATLAB 的工作區(當前記憶體中的變數)就會顯示這些匯入的資料,並以列向量的方式表示,因為預設的資料型別就是“列向量”,當然您可以可以選擇其他的資料型別,大家不妨做幾個實驗,觀察一下選擇不同的資料型別後會結果會有什麼不同。至此,第一步獲取資料的工作的完成。
第二階段:資料探索和建模
現在重新回到問題,對於該問題,我們的目標是能夠評估股票的價值和風險,但現在我們還不知道該如何去評估,MATLAB 是工具,不能代替我們決策用何種方法來評估,但是可以輔助我們得到合適的方法,這就是資料探索部分的工作。下面我們就來嘗試如何在 MATLAB 中進行資料的探索和建模。
Step2.1:檢視資料的統計資訊,瞭解我們的資料。具體操作方式是雙擊工具區(直接雙擊這三個字),此時會得到所有變數的詳細統計資訊。通過檢視這些基本的統計資訊,有助於快速在第一層面認識我們所正在研究的資料。當然,只要大體瀏覽即可,除非這些統計資訊對某個問題都有很重要的意義。資料的統計資訊是認識資料的基礎,但不夠直觀,更直觀也更容易發現數據規律的方式就是資料視覺化,也就是以圖的形式呈現資料的資訊。下面我們將嘗試用 MATLAB 對這些資料進行視覺化。
由於變數比較多,所以還有必要對這些變數進行初步的梳理。對於這個問題,我們一般關心收盤價隨時間的變化趨勢,這樣我們就可以初步選定日期(DateNum)和收盤價(Pclose)作為重點研究物件。也就是說下一步,要對這這兩個變數進行視覺化。
對於一個新手,我們還不知道如何繪圖。但不要緊,新版 MATLAB 提供了更強大的繪圖功能——“繪圖”面板,這裡提供了非常豐富的圖形原型,如圖 3 所示。

圖3 MATLAB繪圖面板中的圖例
要注意,需要在工作區選中變數後繪圖面板中的這些圖示才會啟用。接下來就可以選中一箇中意的圖示進行繪圖,一般都直接先選第一個(plot)看一下效果,然後再瀏覽整個面板,看看有沒有更合適的。下面我們進行繪圖操作。
Step2.2:選中變數 DataNum 和 Pclose,在繪圖面板中單機 plot 圖示,馬上可以得到這兩個變數的視覺化結果,如圖 4 所示,同時還可以在命令視窗區看到繪製此圖的命令:
>> plot(DateNum,Pclose)

圖4 通過 plot 圖示繪製的原圖
這樣我們就知道了,下次再繪製這樣的圖直接用 plot 命令就可以了。一般情況下,用這種方式繪圖的圖往往不能滿足我們的要求,比如我們希望更改:
(1)曲線的顏色、線寬、形狀;
(2)座標軸的線寬、座標,增加座標軸描述;
(3)在同個座標軸中繪製多條曲線。
此時我們就需要了解更多關於命令 plot 的用法,這時就可以通過 MATLAB 強大的幫助系統來幫助我們實現期望的結果。最直接獲取幫助的兩個命令是 doc 和 help,對於新手來說,推薦使用 doc,因為 doc 直接開啟的是幫助系統中的某個命令的用法說明,不僅全,而且有應用例項,這樣就可以“照貓畫虎”,直接參考例項,從而將例項快速轉化成自己需要的程式碼。
接下來我們就要考慮如何評估股票的價值和風險呢?
對於一隻好的股票,我們希望股票的增幅越大越好,體現在數學上,就是曲線的斜率越大越好。
對於風險,則可用最大回撤率來描述更合適,什麼是最大回撤率?
最大回撤率的公式可以這樣表達:
D為某一天的淨值,i為某一天,j為i後的某一天,Di為第i天的產品淨值,Dj則是Di後面某一天的淨值
drawdown=max(Di-Dj)/Di,drawdown就是最大回撤率。其實就是對每一個淨值進行回撤率求值,然後找出最大的。可以使用程式實現。最大回撤率越大,說明該股票的風險越高。所以最大回撤率越小,股票越好。
斜率和最大回撤率不妨一個一個來解決。我們先來看如何計算曲線的斜率。對於這個問題,比較簡單,由於從資料的視覺化結果來看,資料近似成線性,所以不妨用多項式擬合的方法來擬合該改組資料的方程,這樣我們就可以得到斜率。
Step2.3:通過polyfit()多項式擬合的命令,並計算股票的價值,具體程式碼為:
>> p = polyfit(DateNum,Pclose,1); % 多項式擬合
>> value = p(1) % 將斜率賦值給value,作為股票的價值
value =
0.1212
程式碼分析:%後面的內容是註釋。polyfit()有三個引數,前兩個大家都能明白是什麼意思,那第三個引數是什麼意思呢?它表示多項式的階數,也就是最高次數。比如:在本例中,第三個引數為1,說明其為一次項,即一次函式。第三個引數為你要擬合的階數,一階直線擬合,二階拋物線擬合,並非階次越高越好,看擬合情況而定。polyfit()返回階數為 n 的多項式 p(x) 的係數,p 中的係數按降冪排列。在本例中的P(1)指的是最高項的係數,即斜率。
Step2.4:用相似的方法,可以很快得到計算最大回撤的程式碼:
>> MaxDD = maxdrawdown(Pclose); % 計算最大回撤
>> risk = MaxDD % 將最大回撤賦值給risk,作為股票的風險
risk =
0.1155
程式碼分析:最大回撤率當然計算的是每天收盤時的股價。最大回撤率越大,說明該股票的風險越高。所以最大回撤率越小,股票越好。
到此處,我們已經找到了評估股票價值和風險的方法,並能用 MALTAB 來實現了。但是,我們都是在命令列中實現的,並不能很方便地修改程式碼。而 MATLAB 最經典的一種用法就是指令碼,因為指令碼不僅能夠完整地呈現整個問題的解決方法,同時更便於維護、完善、執行,優點很多。所以當我們的探索和開發工作比較成熟後,通常都會將這些有用的程式歸納整理起來,形成指令碼。現在我們就來看如何快速開發解決該問題的指令碼。
Step2.5:像 Step1.1 一樣,重新選中資料檔案,右鍵並單擊“匯入資料”選單,待啟動匯入資料引擎後,選擇“生成指令碼”,然後就會得到匯入資料的指令碼,並儲存該指令碼。
指令碼原始碼中有些地方要注意:
%%在matlab程式碼中的作用是將程式碼分塊,上下兩個%%之間的部分作為一塊,在執行程式碼的時候可以分塊執行,檢視每一塊程式碼的執行情況。常用於除錯程式。%%相當於jupyter notebook中的cell。
%後的內容是註釋。
每句程式碼後面的分號作用為不在命令視窗顯示執行結果。
指令碼原始碼:
%% 預測股票的價值與風險
%% 匯入資料
clc, clear, close all
% clc:清除命令視窗的內容,對工作環境中的全部變數無任何影響
% clear:清除工作空間的所有變數
% close all:關閉所有的Figure視窗
% 匯入資料
[~, ~, raw] = xlsread('sz000004.xlsx', 'Sheet1', 'A2:H7');
% [num,txt,raw],~表示省略該部分的返回值
% xlsread('filename','sheet', 'range'),第二個引數指資料在sheet1還是其他sheet部分,range表示單元格範圍
% 建立輸出變數
data = reshape([raw{:}],size(raw));
% [raw{:}]指raw裡的所有資料,size(raw):6 x 8 ,該語句把6x8的cell型別資料轉換為6x8 double型別資料
% 將匯入的陣列分配列變數名稱
Date = data(:, 1); % 第一個引數表示從第一行到最後一行,第二個引數表示第一列
DateNum = data(:, 2);
Popen = data(:, 3);
Phigh = data(:, 4);
Plow = data(:, 5);
Pclose = data(:, 6);
Volum = data(:, 7); % Volume 表示股票成交量的意思,成交量=成交股數*成交價格 再加權求和
Turn = data(:, 8); % turn表示股票週轉率,股票週轉率越高,意味著該股股性越活潑,也就是投資人所謂的熱門股
% 清除臨時變數data和raw
clearvars data raw;
%% 資料探索
figure % 建立一個新的影象視窗
plot(DateNum, Pclose, 'k'); % 'k',曲線是黑色的,列印後不失真
datetick('x','mm-dd'); % 更改日期顯示型別。引數x表示x軸,mm-dd表示月份和日。yyyy-mm-dd,如2018-10-27
xlabel('日期') % x軸
ylabel('收盤價') % y軸
figure
bar(Pclose) % 作為對照圖形
%% 股票價值的評估
p = polyfit(DateNum, Pclose, 1); % 多項式擬合
% polyfit()返回階數為 n 的多項式 p(x) 的係數,p 中的係數按降冪排列
P1 = polyval(p,DateNum); % 得到多項式模型的結果
figure
plot(DateNum,P1,DateNum,Pclose,'*g'); % 模型與原始資料的對照, '*g'表示綠色的*
value = p(1) % 將斜率賦值給value,作為股票的價值。p(1)最高項的次數
%% 股票風險的評估
MaxDD = maxdrawdown(Pclose); % 計算最大回撤
risk = MaxDD % 將最大回撤賦值給risk,作為股票的風險3、迴歸演算法演練。
(1)一元線性迴歸
[ 例1 ] 近 10 年來,某市社會商品零售總額與職工工資總額(單位:億元)的資料見表1,請建立社會商品零售總額與職工工資總額資料的迴歸模型。

該問題是典型的一元迴歸問題,但先要確定是線性還是非線性,然後就可以利用對應的迴歸方法建立他們之間的迴歸模型了,具體實現的 MATLAB 程式碼如下:
(1)輸入資料
%% 輸入資料
clc, clear, close all
% 職工工資總額
x = [23.8,27.6,31.6,32.4,33.7,34.90,43.2,52.8,63.8,73.4];
% 商品零售總額
y = [41.4,51.8,61.7,67.9,68.7,77.5,95.9,137.4,155.0,175.0];(2)採用最小二乘迴歸
%% 採用最小二乘法迴歸
% 作散點圖
figure
plot(x,y,'r*') % 散點圖,散點為紅色
xlabel('x(職工工資總額)','fontsize',12)
ylabel('y(商品零售總額)','fontsize',12)
set(gca, 'linewidth',2) % 座標軸線寬為2
% 採用最小二乘法擬合
Lxx = sum((x-mean(x)).^2); %在列表運算中,^與.^不同
Lxy = sum((x-mean(x)).*(y-mean(y)));
b1 = Lxy/Lxx;
b0 = mean(y) - b1 * mean(x);
y1 = b1 * x + b0;
hold on % hold on是當前軸及影象保持而不被重新整理,準備接受此後將繪製的圖形,多圖共存
plot(x,y1, 'linewidth',2);執行本節程式,會得到如圖5所示的迴歸圖形。在用最小二乘迴歸之前,先繪製了資料的散點圖,這樣就可以從圖形上判斷這些資料是否近似成線性關係。當發現它們的確近似在一條線上後,再用線性迴歸的方法進行迴歸,這樣也更符合我們分析資料的一般思路。

圖5
(3)採用 LinearModel.fit 函式進行線性迴歸
%% 採用 LinearModel.fit 函式進行線性迴歸
m2 = LinearModel.fit(x, y)
執行結果如下:
m2 =
Linear regression model:
y ~ 1 + x1
Estimated Coefficients:Estimate SE tStat pValue
(Intercept) -23.549 5.1028 -4.615 0.0017215
x1 2.7991 0.11456 24.435 8.4014e-09
R-squared: 0.987, Adjusted R-Squared 0.985
F-statistic vs. constant model: 597, p-value = 8.4e-09
如下圖,我們只需記住-23.594是一次函式的中x的係數,2.7991是一次函式中的常數項即可,其它的不用理會。

4)採用 regress 函式進行迴歸
%% 採用 regress 函式進行迴歸
Y = y'
X = [ones(size(x,2),1),x']
[b,bint,r,rint,s] = regress(Y,X)執行結果如下:
b =
-23.5493
2.7991
我們只需記住-23.594是一次函式的中x的係數,2.7991是一次函式中的常數項即可,其它的不用理會。
(2)一元非線性迴歸
[ 例2 ] 為了解百貨商店銷售額 x 與流通率(這是反映商業活動的一個質量指標,指每元商品流轉額所分攤的流通費用)y 之間的關係,收集了九個商店的有關資料(見表2)。請建立它們關係的數學模型。


為了得到 x 與 y 之間的關係,先繪製出它們之間的散點圖,如圖 2 所示的“雪花”點圖。由該圖可以判斷它們之間的關係近似為對數關係或指數關係,為此可以利用這兩種函式形式進行非線性擬合,具體實現步驟及每個步驟的結果如下:
(1)輸入資料
%% 輸入資料
clc, clear all, close all
x = [1.5, 4.5, 7.5,10.5,13.5,16.5,19.5,22.5,25.5];
y = [7.0,4.8,3.6,3.1,2.7,2.5,2.4,2.3,2.2];
plot(x, y, '*', 'linewidth', 1) % 這裡的linewidth指的是散點大小
set(gca,'linewidth',2) % 設定座標軸的線寬為2
xlabel('銷售額x/萬元','fontsize',12)
ylabel('流通率y/%','fontsize',12)(2)對數形式非線性迴歸
%% 對數形式非線性迴歸
m1 = @(b,x) b(1) + b(2)*log(x);
nonlinfit1 = fitnlm(x,y,m1,[0.01;0.01])
b = nonlinfit1.Coefficients.Estimate;
Y1 = b(1,1) + b(2,1)*log(x);
hold on
plot(x, Y1, '--k', 'linewidth',2)執行結果如下:
nonlinfit1 =
Nonlinear regression model:
y ~ b1 + b2*log(x)
Estimated Coefficients:
Estimate SE tStat pValue
b1 7.3979 0.26667 27.742 2.0303e-08
b2 -1.713 0.10724 -15.974 9.1465e-07
R-Squared: 0.973, Adjusted R-Squared 0.969
F-statistic vs. constant model: 255, p-value = 9.15e-07
(3)指數形式非線性迴歸
%% 指數形式非線性迴歸
m2 = 'y ~ b1*x^b2';
nonlinfit2 = fitnlm(x,y,m2, [1;1])
b1 = nonlinfit2.Coefficients.Estimate(1,1);
b2 = nonlinfit2.Coefficients.Estimate(2,1)
Y2 = b1*x.^b2;
hold on;
plot(x,Y2,'r','linewidth',2)
legend('原始資料','a+b*lnx','a*x^b') % 圖例
執行結果如下:
nonlinfit2 =
Nonlinear regression model:
y ~ b1*x^b2
Estimated Coefficients:
Estimate SE tStat pValue
b1 8.4112 0.19176 43.862 8.3606e-10
b2 -0.41893 0.012382 -33.834 5.1061e-09
R-Squared: 0.993, Adjusted R-Squared 0.992
F-statistic vs. zero model: 3.05e+03, p-value = 5.1e-11
在該案例中,選擇兩種函式形式進行非線性迴歸,從迴歸結果來看,對數形式的決定係數為 0.973 ,而指數形式的為 0.993 ,優於前者,所以可以認為指數形式的函式形式更符合 y 與 x 之間的關係,這樣就可以確定他們之間的函式關係形式了。
2.多元迴歸
1.多元線性迴歸
[ 例3 ] 某科學基金會希望估計從事某研究的學者的年薪 Y 與他們的研究成果(論文、著作等)的質量指標 X1、從事研究工作的時間 X2、能成功獲得資助的指標 X3 之間的關係,為此按一定的實驗設計方法調查了 24 位研究學者,得到如表3 所示的資料( i 為學者序號),試建立 Y 與 X1 , X2 , X3 之間關係的數學模型,並得出有關結論和作統計分析。

該問題是典型的多元迴歸問題,但能否應用多元線性迴歸,最好先通過資料視覺化判斷他們之間的變化趨勢,如果近似滿足線性關係,則可以執行利用多元線性迴歸方法對該問題進行迴歸。具體步驟如下:
(1)作出因變數 Y 與各自變數的樣本散點圖
作散點圖的目的主要是觀察因變數 Y 與各自變數間是否有比較好的線性關係,以便選擇恰當的數學模型形式。圖3 分別為年薪 Y 與成果質量指標 X1、研究工作時間 X2、獲得資助的指標 X3 之間的散點圖。從圖中可以看出這些點大致分佈在一條直線旁邊,因此,有比較好的線性關係,可以採用線性迴歸。繪製圖3的程式碼如下:
%% 作出因變數Y與各自變數的樣本散點圖
% x1,x2,x3,Y的資料
x1=[3.5 5.3 5.1 5.8 4.2 6.0 6.8 5.5 3.1 7.2 4.5 4.9 8.0 6.5 6.5 3.7 6.2 7.0 4.0 4.5 5.9 5.6 4.8 3.9];
x2=[9 20 18 33 31 13 25 30 5 47 25 11 23 35 39 21 7 40 35 23 33 27 34 15];
x3=[6.1 6.4 7.4 6.7 7.5 5.9 6.0 4.0 5.8 8.3 5.0 6.4 7.6 7.0 5.0 4.0 5.5 7.0 6.0 3.5 4.9 4.3 8.0 5.0];
Y=[33.2 40.3 38.7 46.8 41.4 37.5 39.0 40.7 30.1 52.9 38.2 31.8 43.3 44.1 42.5 33.6 34.2 48.0 38.0 35.9 40.4 36.8 45.2 35.1];
% 繪圖,三幅圖橫向並排
subplot(1,3,1),plot(x1,Y,'g*')
subplot(1,3,2),plot(x2,Y,'k+')
subplot(1,3,3),plot(x3,Y,'ro')
繪製的圖形如下:

(2)進行多元線性迴歸
這裡可以直接使用 regress 函式執行多元線性迴歸,注意以下程式碼模板,以後碰到多元線性問題直接套用程式碼,具體程式碼如下:
%% 進行多元線性迴歸
n = 24; m = 3; % 每個變數均有24個數據,共有3個變數
X = [ones(n,1),x1',x2',x3'];
[b,bint,r,rint,s]=regress(Y',X,0.05) % 0.05為預定顯著水平,判斷因變數y與自變數之間是否具有顯著的線性相關關係需要用到。
執行結果如下:
b =
18.0157
1.0817
0.3212
1.2835
bint =
13.9052 22.1262
0.3900 1.7733
0.2440 0.3984
0.6691 1.8979
r =
0.6781
1.9129
-0.1119
3.3114
-0.7424
1.2459
-2.1022
1.9650
-0.3193
1.3466
0.8691
-3.2637
-0.5115
-1.1733
-1.4910
-0.2972
0.1702
0.5799
-3.2856
1.1368
-0.8864
-1.4646
0.8032
1.6301
rint =
-2.7017 4.0580
-1.6203 5.4461
-3.6190 3.3951
0.0498 6.5729
-4.0560 2.5712
-2.1800 4.6717
-5.4947 1.2902
-1.3231 5.2531
-3.5894 2.9507
-1.7678 4.4609
-2.7146 4.4529
-6.4090 -0.1183
-3.6088 2.5859
-4.7040 2.3575
-4.8249 1.8429
-3.7129 3.1185
-3.0504 3.3907
-2.8855 4.0453
-6.2644 -0.3067
-2.1893 4.4630
-4.4002 2.6273
-4.8991 1.9699
-2.4872 4.0937
-1.8351 5.0954
s =
0.9106 67.9195 0.0000 3.0719看到如此長的執行結果,我們不要害怕,因為裡面很多資料是沒用的,我們只需提取有用的資料。
在執行結果中,很多資料我們不需理會,我們真正需要用到的資料如下:
b =
18.0157
1.0817
0.3212
1.2835
s =
0.9106 67.9195 0.0000 3.0719迴歸係數 b = (β0,β1,β2,β3) = (18.0157, 1.0817, 0.3212, 1.2835),迴歸係數的置信區間,以及統計變數 stats(它包含四個檢驗統計量:相關係數的平方R^2,假設檢驗統計量 F,與 F 對應的概率 p,s^2 的值)。觀察表4的資料,會發現它來源於執行結果中的b和s:

根據β0,β1,β2,β3,我們初步得出迴歸方程為:
![]()
如何判斷該回歸方程是否符合該模型呢?有以下3種方法:
1)相關係數 R 的評價:本例 R 的絕對值為 0.9542 ,表明線性相關性較強。
2)F 檢驗法:當 F > F1-α(m,n-m-1) ,即認為因變數 y 與自變數 x1,x2,...,xm 之間有顯著的線性相關關係;否則認為因變數 y 與自變數 x1,x2,...,xm 之間線性相關關係不顯著。本例 F=67.919 > F1-0.05( 3,20 ) = 3.10。
3)p 值檢驗:若 p < α(α 為預定顯著水平),則說明因變數 y 與自變數 x1,x2,...,xm之間顯著地有線性相關關係。本例輸出結果,p<0.0001,顯然滿足 p<α=0.05。
以上三種統計推斷方法推斷的結果是一致的,說明因變數 y 與自變數之間顯著地有線性相關關係,所得線性迴歸模型可用。s^2 當然越小越好,這主要在模型改進時作為參考。
3. 逐步迴歸
[ 例4 ] (Hald,1960)Hald 資料是關於水泥生產的資料。某種水泥在凝固時放出的熱量 Y(單位:卡/克)與水泥中 4 種化學成品所佔的百分比有關:
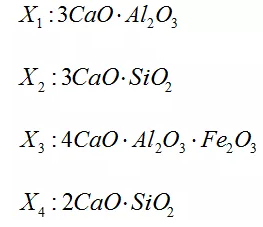
在生產中測得 12 組資料,見表5,試建立 Y 關於這些因子的“最優”迴歸方程。

對於例 4 中的問題,可以使用多元線性迴歸、多元多項式迴歸,但也可以考慮使用逐步迴歸。從逐步迴歸的原理來看,逐步迴歸是以上兩種迴歸方法的結合,可以自動使得方程的因子設定最合理。對於該問題,逐步迴歸的程式碼如下:
%% 逐步迴歸
X=[7,26,6,60;1,29,15,52;11,56,8,20;11,31,8,47;7,52,6,33;11,55,9,22;3,71,17,6;1,31,22,44;2,54,18,22;21,47,4,26;1,40,23,34;11,66,9,12]; %自變數資料
Y=[78.5,74.3,104.3,87.6,95.9,109.2,102.7,72.5,93.1,115.9,83.8,113.3]; %因變數資料
stepwise(X,Y,[1,2,3,4],0.05,0.10)% in=[1,2,3,4]表示X1、X2、X3、X4均保留在模型中
程式執行後得到下列逐步迴歸的視窗,如圖 4 所示。

圖4
在圖 4 中,用藍色行顯示變數 X1、X2、X3、X4 均保留在模型中,視窗的右側按鈕上方提示:將變數X4剔除迴歸方程(Move X4 out),單擊 Next Step 按鈕,即進行下一步運算,將第 4 列資料對應的變數 X4 剔除迴歸方程。單擊 Next Step 按鈕後,剔除的變數 X3 所對應的行用紅色表示,同時又得到提示:將變數 X3 剔除迴歸方程(Move X3 out),單擊 Next Step 按鈕,這樣一直重複操作,直到 “Next Step” 按鈕變灰,表明逐步迴歸結束,此時得到的模型即為逐步迴歸最終的結果。最終結果如下:

4. 邏輯迴歸
[ 例5 ] 企業到金融商業機構貸款,金融商業機構需要對企業進行評估。評估結果為 0 , 1 兩種形式,0 表示企業兩年後破產,將拒絕貸款,而 1 表示企業 2 年後具備還款能力,可以貸款。在表 6 中,已知前 20 家企業的三項評價指標值和評估結果,試建立模型對其他 5 家企業(企業 21-25)進行評估。

對於該問題,很明顯可以用 Logistic 模型來回歸,具體求解程式如下:
% logistic迴歸
%% 匯入資料
clc,clear,close all
X0 = xlsread('logistic_ex1.xlsx','A2:C21'); % 前20家企業的三項評價指標值,即迴歸模型的輸入
Y0 = xlsread('logistic_ex1.xlsx','D2:D21'); % 前20家企業的評估結果,即迴歸模型的輸出
X1 = xlsread('logistic_ex1.xlsx','A2:C26'); % 預測資料輸入
%% 邏輯函式
GM = fitglm(X0,Y0,'Distribution','binomial');
Y1 = predict(GM,X1);
%% 模型的評估
N0 = 1:size(Y0,1); % N0 = [1,2,3,4,……,20]
N1 = 1:size(Y1,1); % N1 = [1,2,3,4,……,25]
plot(N0',Y0,'-kd'); % N0'指的是對N0'進行轉置,N0'和Y0的形式相同,該行程式碼繪製的是前20家企業的評估結果
% plot()中的引數'-kd'的解析:-代表直線,k代表黑色,d代表菱形符號
hold on;
scatter(N1',Y1,'b'); % N1'指的是對N1'進行轉置,N1'和Y1的形式相同
xlabel('企業編號');
ylabel('輸出值');得到的迴歸結果與原始資料的比較如圖5所示。

圖5
三、總結與感悟。
總結:通過這次學習,我瞭解到Matlab在數學建模競賽中使用廣泛;在評估股票價值與風險的小例項中,我掌握了用Matlab去建模的基本方法和步驟;在迴歸演算法的學習過程中,我掌握了一元線性迴歸、一元非線性迴歸、多元線性迴歸、逐步迴歸、邏輯迴歸的演算法。
感悟:正確且高效的 MATLAB 程式設計理念就是以問題為中心的主動程式設計。我們傳統學習程式設計的方法是學習變數型別、語法結構、演算法以及程式設計的其他知識,因為學習時候是沒有目標的,也不知道學的知識什麼時候能用到,收效甚微。而以問題為中心的主動程式設計,則是先找到問題的解決步驟,然後在 MATLAB 中一步一步地去實現。在每步實現的過程中,遇到問題,查詢知識(網際網路時代查詢知識還是很容易的),定位方法,再根據方法,查詢 MATLAB 中的對應函式,學習函式用法,回到程式,解決問題。在這個過程中,知識的獲取都是為了解決問題的,也就是說每次學習的目標都是非常明確的,學完之後的應用就會強化對知識的理解和掌握,這樣即學即用的學習方式是效率最高,也是最有效的方式。最重要的是,這種主動的程式設計方式會讓學習者體驗到學習的成就感的樂趣,有成就感,自然就強化對程式設計的自信了。這種內心的自信和強大在建模中會發揮意想不到的力量,所為信念的力量。