
kafka工作原理與使用
1. Kafka概述
1.1. 什麼是Kafka
Apache Kafka是分散式釋出-訂閱訊息系統(訊息中介軟體)。它最初由LinkedIn公司開發,之後成為Apache專案的一部分。Kafka是一種快速、可擴充套件的、設計內在就是分散式的,分割槽的和可複製的提交日誌服務。
簡單說明什麼是Kafka:
舉個例子,生產者消費者,生產者生產雞蛋,消費者消費雞蛋,生產者生產一個雞蛋,消費者就消費一個雞蛋,假設消費者消費雞蛋的時候噎住了(系統宕機了),生產者還在生產雞蛋,那新生產的雞蛋就丟失了。再比如生產者很強勁(大交易量的情況),生產者1秒鐘生產100個雞蛋,消費者1秒鐘只能吃50個雞蛋,那要不了一會,消費者就吃不消了(訊息堵塞,最終導致系統超時),消費者拒絕再吃了,”雞蛋“又丟失了,這個時候我們放個籃子在它們中間,生產出來的雞蛋都放到籃子裡,消費者去籃子裡拿雞蛋,這樣雞蛋就不會丟失了,都在籃子裡,而這個籃子就是”Kafka“。
雞蛋其實就是“資料流”,系統之間的互動都是通過“資料流”來傳輸的(就是tcp、http什麼的),也稱為報文,也叫“訊息”。
訊息佇列滿了,其實就是籃子滿了,”雞蛋“ 放不下了,那趕緊多放幾個籃子,其實就是Kafka的擴容。Kafka就是例子中的"籃子"。
傳統訊息中介軟體服務RabbitMQ、Apache ActiveMQ等。
Apache Kafka與傳統訊息系統相比,有以下不同:
l 它是分散式系統,易於向外擴充套件;
l 它同時為釋出和訂閱提供高吞吐量;
l 它支援多訂閱者,當失敗時能自動平衡消費者;
l 它將訊息持久化到磁碟,因此可用於批量消費,例如ETL,以及實時應用程式。
2.kafka的幾個重要概念
- Broker:訊息中介軟體處理結點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka叢集;
- Topic:一類訊息,例如page view日誌、click日誌等都可以以topic的形式存在,Kafka叢集能夠同時負責多個topic的分發,主題中的每條訊息包括key-value和timestamp。可以定義多個topic,每個topic又可以劃分為多個分割槽
- Partition:topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的隊,通過key取雜湊後把訊息對映分發到一個指定的分割槽,每個分割槽都對映到broker上的一個目錄。一般不同分割槽儲存在不同broker上
- PartitionId:是一個整數,範圍從0到分割槽數-1。
- 分割槽名;其命名規則為<topic_name>-<partition_id>
- Segment(環節; 部分):每個partition又由多個segment file組成;
- offset:每個partition都由一系列有序的、不可變的訊息組成,這些訊息被連續的追加到partition中。partition中的每個訊息都有一個連續的序列號叫做offset,用於partition唯一標識一條訊息;
- message:這個算是kafka檔案中最小的儲存單位,即是 a commit log。
- kafka的message是以topic為基本單位,不同topic之間是相互獨立的。每個topic又可分為幾個不同的partition,每個partition儲存一部的分message。topic與partition的關係如下:
其中,partition是以資料夾的形式儲存在具體Broker本機上。
- 日誌段
一個日誌又被劃分為多個日誌段(LogSegment),日誌段是Kafka日誌物件分片的最小單位。與日誌物件一樣,日誌段也是一個邏輯概念,一個日誌段對應磁碟上一個具體日誌檔案和兩個索引檔案。日誌檔案是以“.log”為檔名字尾的資料檔案,用於儲存訊息實際資料。兩個索引檔案分別以“.index”和“.timeindex”作為檔名字尾,分別表示訊息偏移量索引檔案和訊息時間戳索引檔案。

2.1segment中的檔案
對於一個partition(在Broker中以資料夾的形式存在),裡面又有很多大小相等的segment資料檔案(這個檔案的具體大小可以在config/server.properties中進行設定),這種特性可以方便old segment file的快速刪除。
下面先介紹一下partition中的segment file的組成:
segment file 組成:
由2部分組成,分別為index file和data file,這兩個檔案是一一對應的,字尾”.index”和”.log”分別表示索引檔案和資料檔案;
其中.log用於儲存真正的訊息資料
segment file 命名規則:partition的第一個segment從0開始,後續每個segment檔名為上一個segment檔案最後一條訊息的offset,ofsset的數值最大為64位(long型別),20位數字字元長度,沒有數字用0填充。如下圖所示:

關於segment file中index與data file對應關係圖,這裡我們選用網上的一個圖片,如下所示:

segment的索引檔案中儲存著大量的元資料,資料檔案中存儲著大量訊息,索引檔案中的元資料指向對應資料檔案中的message的物理偏移地址。以索引檔案中的3,497為例,在資料檔案中表示第3個message(在全域性partition表示第368772個message),以及該訊息的物理偏移地址為497。
注:Partition中的每條message由offset來表示它在這個partition中的偏移量,這個offset並不是該Message在partition中實際儲存位置,而是邏輯上的一個值(如上面的3),但它卻唯一確定了partition中的一條Message(可以認為offset是partition中Message的id)
2.2Kafka分割槽命名規則
partition是以檔案的形式儲存在檔案系統中,比如,建立了一個名為page_visits的topic,其有5個partition,那麼在Kafka的資料目錄中(由配置檔案中的log.dirs指定的)中就有這樣5個目錄: page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4,其命名規則為<topic_name>-<partition_id>,裡面儲存的分別就是這5個partition的資料。
1.2. Kafka術語
|
術語 |
解釋 |
|
Broker |
Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker |
|
Topic |
每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的訊息分開儲存,邏輯上一個Topic的訊息雖然保存於一個或多個broker上但使用者只需指定訊息的Topic即可生產或消費資料而不必關心資料存於何處) |
|
Partition |
Partition是物理上的概念,每個Topic包含一個或多個Partition. |
|
Producer |
負責釋出訊息到Kafka broker |
|
Consumer |
訊息消費者,向Kafka broker讀取訊息的客戶端 |
|
Consumer Group |
每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於預設的group) |
|
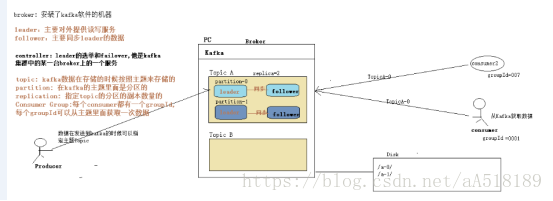
replica |
partition 的副本,保障 partition 的高可用 |
|
leader |
replica 中的一個角色, producer 和 consumer 只跟 leader 互動 |
|
follower |
replica 中的一個角色,從 leader 中複製資料 |
|
controller |
Kafka 叢集中的其中一個伺服器,用來進行 leader election 以及各種 failover |
小白理解:
Ø producer:生產者,就是它來生產“雞蛋”的。
Ø consumer:消費者,生出的“雞蛋”它來消費。
Ø topic:把它理解為標籤,生產者每生產出來一個雞蛋就貼上一個標籤(topic),消費者可不是誰生產的“雞蛋”都吃的,這樣不同的生產者生產出來的“雞蛋”,消費者就可以選擇性的“吃”了。
Ø broker:就是籃子了。
如果從技術角度,topic標籤實際就是佇列,生產者把所有“雞蛋(訊息)”都放到對應的佇列裡了,消費者到指定的佇列裡取。
副本一般不會和leader在同一個機器上
不同的leader的一般不再同一臺機器上,這樣同一臺太忙,效率低
1.3. Kafka叢集結構圖
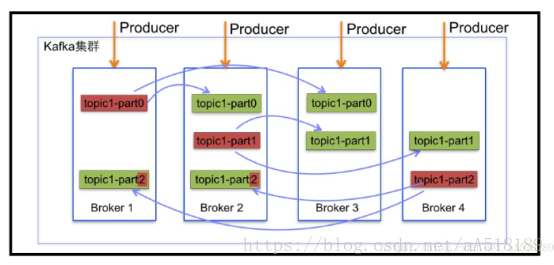
1.4 Kafka細節說明
Ø 細節一:kafka的主體分割槽中,資料是從後向前追加的。
Ø 細節二: 每一個Consumer都有一個group id 一個group id 只能從主體中消費一次資料,僅僅一次。就是consumers是訊息系統的流出介面,多個consumers邏輯上組成consumer Group。CG的目標是實現同一需求的消費吞吐量。同一個topic的message,只能被同一CG的一個Consumer消費;但可以被不同多個CG消費;
Ø 細節三:未來負載均衡,一般不同的leader不在同一臺機器上。不然同一臺機器壓力太大。
Ø 細節四:副本一般不會和leader在一臺機器上,方式宕機帶來的資料丟失。
Kafka功能概述
1.1.1. 首先有幾個概念:
· Kafka作為一個叢集執行在一臺或多臺可以跨越多個數據中心的伺服器上。
· 卡夫卡叢集在稱為主題的類別中儲存記錄流。
· 每個記錄由一個鍵,一個值和一個時間戳組成。
1.1.2. kafka有四個核心API:
· 生產者API允許應用程式釋出的記錄流至一個或多個kafka的話題。
· 消費者API允許應用程式訂閱一個或多個主題,並處理所產生的對他們記錄的資料流。
· 流API允許應用程式充當流處理器,從一個或多個主題消耗的輸入流,併產生一個輸出流至一個或多個輸出的主題,有效地變換所述輸入流,以輸出流。
· 聯結器API允許構建和執行卡夫卡主題連線到現有的應用程式或資料系統中重用生產者或消費者。例如,連線到關係資料庫的聯結器可能會捕獲對錶的每個更改。
Producer API允許應用程式將資料流傳送到Kafka叢集中的主題。
Producer釋出訊息
- producer 採用 push 模式將訊息釋出到 broker,每條訊息都被 append 到 partition 中,屬於順序寫磁碟(順序讀寫極大的提高了寫資料的速度)。
- producer 傳送訊息到 broker 時,會根據分割槽演算法選擇將其儲存到哪一個partition。

|
1. 指定了 partition,則直接使用; 2. 未指定 partition 但指定 key,通過對 key 的 value 進行hash 選出一個 partition 3. partition 和 key 都未指定,使用輪詢選出一個 partition 。 |
寫資料流程
|
1. producer 先從 zookeeper 的 "/brokers/.../state" 節點找到該 partition 的 leader 2. producer 將訊息傳送給該 leader 3. leader 將訊息寫入本地 log 4. followers 從 leader pull 訊息,寫入本地 log 後 leader 傳送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 後,增加 HW(high watermark,最後 commit 的 offset) 並向 producer 傳送 ACK |
Producer內部資料流程

流程:使用者構建producerRcord,然後呼叫kafkaProducer,然後kafkaProducer接受資料進行序列化,然後結合本地快取的元資料一起傳送給partitioner去確定目標分割槽,最後追加寫入記憶體的訊息緩衝池。
要使用生產者,你可以使用下面的maven依賴關係:
|
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency> |
Consumer API允許應用程式從Kafka叢集中的主題讀取資料流。
展示如何使用消費者的示例在javadoc中給出 。
要使用消費者,您可以使用以下maven依賴項:
|
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency> |
該流 API允許將來自輸入主題資料流輸出的主題。
展示如何使用這個庫的例子在javadoc中給出
有關使用Streams API的其他文件可在此處獲得。
要使用Kafka Streams,您可以使用以下maven依賴項:
|
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>1.1.0</version> </dependency> |
1.1.6. 連線API
Connect API允許實現連續性聯結器,這些聯結器可以連續地從某些源資料系統提取到Kafka或從Kafka推送到某些接收器資料系統。
Connect的許多使用者不需要直接使用此API,但他們可以使用預建聯結器而無需編寫任何程式碼。有關使用Connect的更多資訊,請點選這裡。
那些想要實現自定義聯結器的人可以看到javadoc。
AdminClient API支援管理和檢查主題,代理,acl和其他Kafka物件。
要使用AdminClient API,請新增以下Maven依賴項:
|
1 2 3 4 五 6 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency> |
生產者與消費者
學會利用官網學習
相關引數說明:
Spark streaming的引數配置
conf.setMaster("local[*]")
conf.setAppName("spark streaming直連整合kafka")
每秒鐘每個分割槽kafka拉取訊息的速率
conf.set("spark.streaming.kafka.maxRatePerPartition", "5")
程式優雅的關閉
conf.set("spark.streaming.stopGracefullyOnShutdown", "true")
Kafka的引數配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "kk-01:9092,kk-02:9092,kk-03:9092",
"key.deserializer" -> classOf[StringDeserializer], // 類.class.getName
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
// 不記錄消費的偏移量資訊 true 記錄
"enable.auto.commit" -> (false: java.lang.Boolean) )
"auto.offset.reset"引數設定
Kafka單獨寫consumer時
可選引數:
earliest:自動將偏移重置為最早的偏移量
latest:自動將偏移量重置為最新的偏移量(預設)
none:如果consumer group沒有發現先前的偏移量,則向consumer丟擲異常。
其他的引數:向consumer丟擲異常(無效引數)
和SparkStreaming整合時:
注意:和SparkStreaming整合時,上面的可選引數是無效的,只有兩個可選引數:
smallest:簡單理解為從頭開始消費,其實等價於上面的 earliest
largest:簡單理解為從最新的開始消費,其實等價於上面的 latest
遮蔽日誌
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
Kafka原始碼中的Producer Record定義
1. ProducerRecord<K, V> 含義:
傳送給Kafka Broker的key/value 值對
原碼:
public final class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final K key;
private final V value; }
2.內部資料結構:
-- Topic (名字)
-- PartitionID ( 可選)
-- Key[( 可選 )
-- Value
3.生產者記錄(簡稱PR)的傳送邏輯:
<1> 若指定Partition ID,則PR被髮送至指定Partition
<2> 若未指定Partition ID,但指定了Key, PR會按照hasy(key)傳送至對應Partition
<3> 若既未指定Partition ID也沒指定Key,PR會按照round-robin模式傳送到每個Partition
<4> 若同時指定了Partition ID和Key, PR只會傳送到指定的Partition (Key不起作用,程式碼邏輯決定)
4.生產者記錄(PR)的實現:
針對3,提供三種建構函式形參:
-- ProducerRecord(topic, partition, key, value)
-- ProducerRecord(topic, key, value)
-- ProducerRecord(topic, value)
生產者與消費者例項
生產者
程式碼核心:
第一步:使用一個map去封裝一個kafka生產者 的資訊,然後建立一個生產者
val producer = new KafkaProducer[String, String](props)
第二步:根據自己的需求建立一個訊息物件,然後由生產者傳送到kafka中去
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
|
package spark_kafka
val producer = new KafkaProducer[String, String](props) |
消費者
|
import org.apache.spark.streaming._ |