Spark-基於scala實現文章特徵提取(TF-IDF)
阿新 • • 發佈:2019-02-10
一.基本原理:
TF-IDF(term frequency–inverse document frequency):TF表示 詞頻,IDF表示 反文件頻率.TF-IDF主要內容就是:如果一個詞語在本篇文章出現的頻率(TF)高,並且在其他文章出現少(即反文件頻率IDF高),那麼就可以認為這個詞語是本篇文章的關鍵詞,因為它具有很好的區分和代表能力.二.SparkML庫:
TF:HashingTF 是一個Transformer,在文字處理中,接收詞條的集合然後把這些集合轉化成固定長度的特徵向量。這個演算法在雜湊的同時會統計各個詞條的詞頻。IDF:IDF是一個Estimator,在一個數據集上應用它的fit()方法,產生一個IDFModel。 該IDFModel 接收特徵向量(由HashingTF產生),然後計算每一個詞在文件中出現的頻次。IDF會減少那些在語料庫中出現頻率較高的詞的權重。
三.Spark例項:
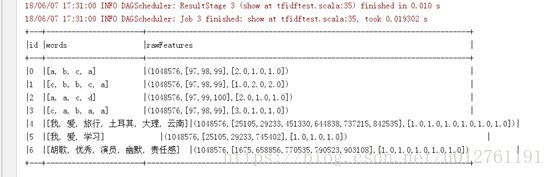
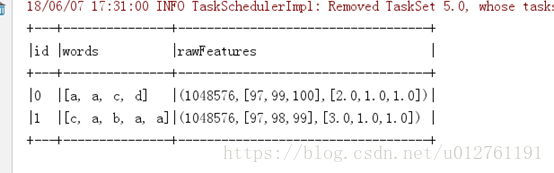
import java.io.{FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream, _} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.ml.feature._ import org.apache.spark.sql.SQLContext object tfidftest { def main(args: Array[String]): Unit = { val masterUrl = "local[2]" val appName ="tfidf_test" val sparkConf = new SparkConf().setMaster(masterUrl).setAppName(appName) @transient val sc = new SparkContext(sparkConf) val sqlContext = new SQLContext(sc) import sqlContext.implicits._ val df = sc.parallelize(Seq( (0, Array("a", "b", "c","a")), (1, Array("c", "b", "b", "c", "a")), (2, Array("a", "a", "c","d")), (3, Array("c", "a", "b", "a", "a")), (4, Array("我", "愛", "旅行", "土耳其", "大理","雲南")), (5, Array("我", "愛", "學習")), (6, Array("胡歌", "優秀","演員", "幽默", "責任感")) )).map(x => (x._1, x._2)).toDF("id", "words") df.show(false) //展示資料 val hashModel = new HashingTF() .setInputCol("words") .setOutputCol("rawFeatures") .setNumFeatures(Math.pow(2, 20).toInt) val featurizedData = hashModel.transform(df) featurizedData.show(false) //展示資料 val df3 = sc.parallelize(Seq( (0, Array("a", "a", "c","d")), (1, Array("c", "a", "b", "a", "a")) )).map(x => (x._1, x._2)).toDF("id", "words") hashModel.transform(df3).show(false) val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features") val idfModel = idf.fit(featurizedData) val rescaledData = idfModel.transform(featurizedData) rescaledData.select("words", "features").show(false) try { val fileOut: FileOutputStream = new FileOutputStream("idf.jserialized") val out: ObjectOutputStream = new ObjectOutputStream(fileOut) out.writeObject(idfModel) out.close() fileOut.close() System.out.println("\nSerialization Successful... Checkout your specified output file..\n") } catch { case foe: FileNotFoundException => foe.printStackTrace() case ioe: IOException => ioe.printStackTrace() } val fos = new FileOutputStream("model.obj") val oos = new ObjectOutputStream(fos) oos.writeObject(idfModel) oos.close val fis = new FileInputStream("model.obj") val ois = new ObjectInputStream(fis) val newModel = ois.readObject().asInstanceOf[IDFModel] val df2 = sc.parallelize(Seq( (0, Array("a", "b", "c","a")), (1, Array("c", "b", "b", "c", "a")), (2, Array("我", "愛", "旅行", "土耳其", "大理","雲南")), (3, Array("我", "愛", "工作")), (4, Array("胡歌", "優秀","演員", "幽默", "責任感")) )).map(x => (x._1, x._2)).toDF("id", "words") val hashModel2 = new HashingTF() .setInputCol("words") .setOutputCol("rawFeatures") .setNumFeatures(Math.pow(2, 20).toInt) val featurizedData2 = hashModel2.transform(df2) val rescaledData2 = newModel.transform(featurizedData2) rescaledData2.select("words", "features").show(false) } }