
快速排序 與 隨機快速排序 演算法分析
阿新 • • 發佈:2019-02-10
快速排序是由東尼·霍爾所發展的一種排序演算法。在平均狀況下,排序 n 個專案要Ο(n log n)次比較。在最壞狀況下則需要Ο(n2)次比較,但這種狀況並不常見。事實上,快速排序通常明顯比其他Ο(n log n) 演算法更快,因為它的內部迴圈(inner loop)可以在大部分的架構上很有效率地被實現出來。
快速排序的優點:
(1)原址排序,空間複雜度較小。
(2)雖然最壞情況下(有序陣列)時間複雜度為 (n*n),但是平均效能很好,期望複雜度為( nlg(n) )。
快速排序使用分治法(Divide and conquer)策略來把一個序列(list)分為兩個子序列(sub-lists)
步驟為:
(1)從數列中挑出一個元素,稱為 "基準"(pivot),
(2)重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的後面(相同的數可以到任一邊)。在這個分割槽退出之後,該基準就處於數列的 中間位置。這個稱為分割槽(partition)操作。
(3)遞迴地(recursive)把小於基準值元素的子數列和大於基準值元素的子數列排序。
快速排序 與 隨機快速排序的唯一區別就是:快速排序始終將陣列最後一個元素作為基準,而隨機快速排序是從陣列中隨機挑選一個元素和最後一個元素交換位置後,作為基準。隨機快速排序基準的選擇更能適應大規模隨機資料的快速排序。
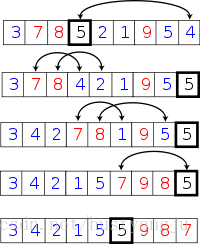
(隨機快速排序演算法)
快速排序原始碼:
#include <iostream> #include <algorithm> #include <cstdlib> using namespace std; class quick_sort_class { public: quick_sort_class(int *a, int n):p_array(a), n_array(n){}; ~quick_sort_class(); void quick_sort(int i, int j); void print(); protected: int partition(int *a, int p, int r); private: int *p_array; int n_array; }; quick_sort_class::~quick_sort_class() { } int quick_sort_class::partition(int *a, int p, int r) { int x = a[r]; int i = p-1; for(int j=p;j<r;++j) { if(a[j]<=x) { ++i; swap(a[i], a[j]); } } swap(a[i+1], a[r]); return i+1; } void quick_sort_class::quick_sort(int i, int j) { if(i<j) { int q = partition(p_array, i, j); quick_sort(i, q-1); quick_sort(q+1, j); } } void quick_sort_class::print() { for(int i=0;i<n_array;++i) cout<<p_array[i]<<" "; cout<<endl; } int main() { int array[10] = {8, 4, 7, 15, 10, 84, 23, 19, 3, 11}; quick_sort_class myQuickSort(array, 10); myQuickSort.print(); myQuickSort.quick_sort(0, 9); myQuickSort.print(); }
測試結果:
