
深度學習-網路引數初始化Xavier與MSRA
權值初始化的方法主要有:常量初始化(constant)、高斯分佈初始化(gaussian)、positive_unitball初始化、均勻分佈初始化(uniform)、xavier初始化、msra初始化、雙線性初始化(bilinear)。可參考部落格。
重點介紹xavier與msra。
xavier初始化
對於權值的分佈:均值為0,方差為(1 / 輸入的個數) 的 均勻分佈。推導過程參考部落格
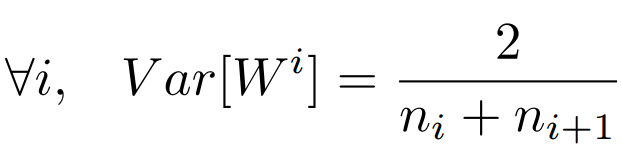
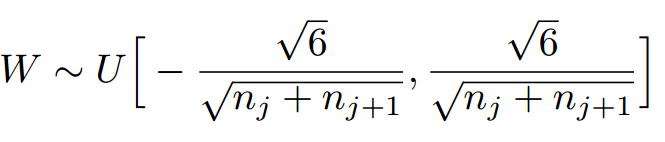
msra初始化
對於權值的分佈:基於均值為0,方差為( 2/輸入的個數)的高斯分佈;它特別適合 ReLU啟用函式,該方法主要是基於Relu函式提出的,推導過程,可以參考
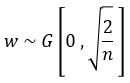
相關推薦
深度學習-網路引數初始化Xavier與MSRA
權值初始化的方法主要有:常量初始化(constant)、高斯分佈初始化(gaussian)、positive_unitball初始化、均勻分佈初始化(uniform)、xavier初始化、msra初始化、雙線性初始化(bilinear)。可參考部落格。 重點介紹xavier
【深度學習】權重初始化
為什麼要初始化?暴力初始化效果如何? 神經網路,或者深度學習演算法的引數初始化是一個很重要的方面,傳統的初始化方法從高斯分佈中隨機初始化引數。甚至直接全初始化為1或者0。這樣的方法暴力直接,但是往往效果一般。本篇文章的敘述來源於一個國外的討論帖子[1],下面就自己的理解闡述一下。 首先我們來思考
神經網路引數初始化
神經網路引數的初始化,在網路層數很深的情況下變得尤為重要。如果引數初始化的過小,很可能導致網路每一層的輸出為都接近於0,那麼可以這樣認為每一層的輸入都會很接近於0,在進行反向傳播的時候,假如我們要更新某一層的引數W,該層的輸出是g(WX)暫且先不考慮偏置項,則求W的梯度就
深度學習網路模型視覺化
在學習Resnet50的時候官網上給出了網路的整個模型圖 http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006 ,但是學RFCN的時候就不知道哪裡能找到,看到同事給的文件裡面有部分圖,諮詢後,同事給了我幾個prototx
PyTorch學習:引數初始化
Sequential 模型的引數初始化 import numpy as np import torch from torch import nn # 定義一個 Sequential 模型 net1 = nn.Sequential( nn.Linear(2, 4),
網路引數初始化
參考:《解析深度學習——卷積神經網路原理與視覺實踐》 網址:http://lamda.nju.edu.cn/weixs/book/CNN_book.pdf 實際應用中,隨機引數服從高斯分佈或均勻分佈 一、Xaiver引數初始化方法和He引數初始化方法 (1)Xaiver引數初始化方法
CNN筆記(2)--網路引數初始化
7網路引數初始化 7.1 全零初始化 網路收斂到穩定狀態時,引數(權值)在理想情況下應基本保持正負各半,期望為0 全0初始化可以使初始化全零時引數期望為0 但是,全0初始化不能訓練 7.2隨機初始化 仍然希望引數期望接近1 隨機引數服從高斯
深層神經網路引數初始化方式對訓練精度的影響
本文是基於吳恩達老師《深度學習》第二週第一課練習題所做,目的在於探究引數初始化對模型精度的影響。文中所用到的輔助程式在這裡。一、資料處理本文所用第三方庫如下,其中init_utils為輔助程式包含構建神經網路的函式。import numpy as np import matp
神經網路引數初始化問題程式碼測試
背景: 神經網路的引數初始化,一般是採用隨機初始化的方式。如果是初始化為全0,會導致每層的多個神經元退化為一個,即在每層中的多個神經元是完全失效的。雖然層與層之間仍然是有效的,但是每層一個神經元的多層神經網路,你真的覺得有意思?有什麼想法,歡迎留言。 程式碼
Spring 原始碼學習 04:初始化容器與 DefaultListableBeanFactory
#### 前言 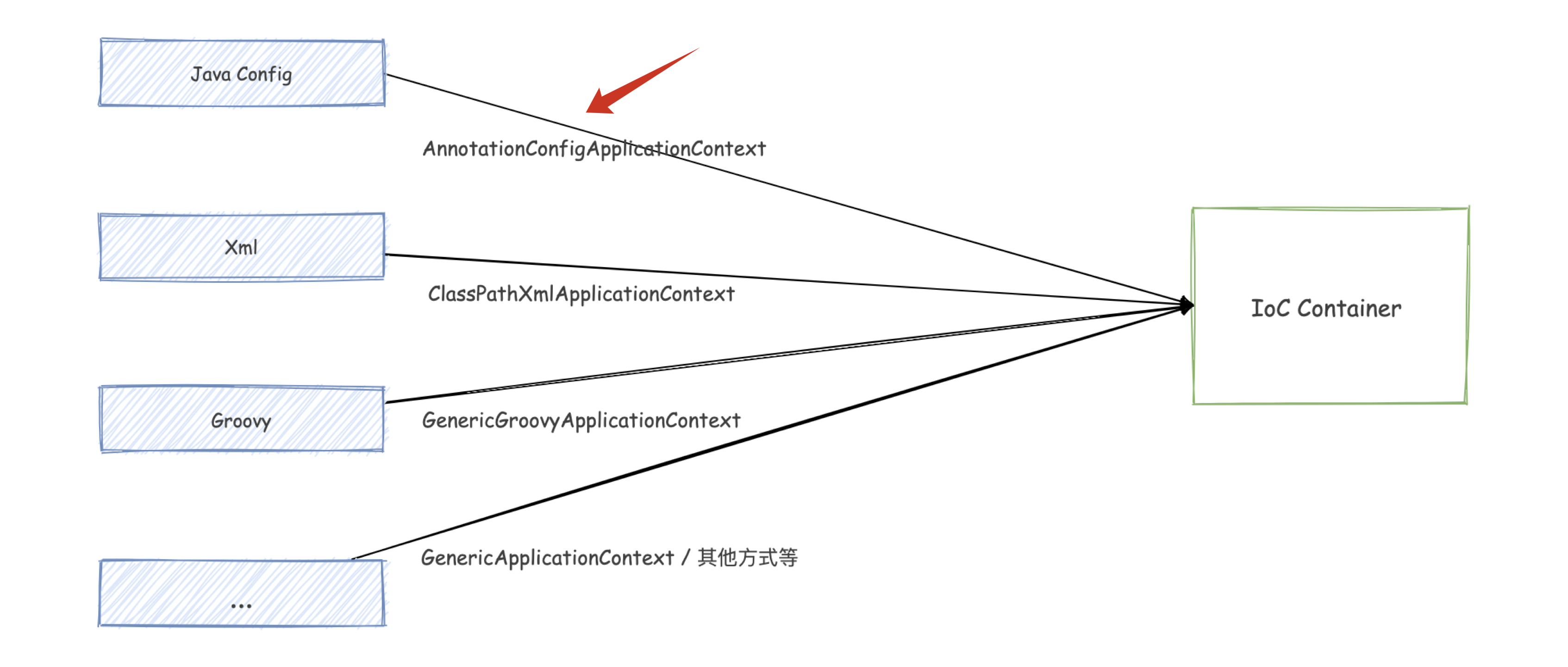 在前一篇文章:[建立 IoC 容器的幾種方式](https://mp.weixin.qq.com/s/V7SjmIFKAXyppBF_
權值初始化 - Xavier和MSRA方法
設計好神經網路結構以及loss function 後,訓練神經網路的步驟如下: 初始化權值引數 選擇一個合適的梯度下降演算法(例如:Adam,RMSprop等) 重複下面的迭代過程: 輸入的正向傳播 計算loss function 的值 反向傳播,計算loss function 相對於權值引數的梯度值 根
卷積神經網路(三):權值初始化方法之Xavier與MSRA
基礎知識 首先介紹一下Xavier等初始化方法比直接用高斯分佈進行初始化W的優勢所在: 一般的神經網路在前向傳播時神經元輸出值的方差會不斷增大,而使用Xavier等方法理論上可以保證每層神經元輸入輸出方差一致。 這裡先介紹一個方差相乘的公式,以便理解Xav
深度學習剖根問底:權值初始化xavier
權值初始化的方法主要有:常量初始化(constant)、高斯分佈初始化(gaussian)、positive_unitball初始化、均勻分佈初始化(uniform)、xavier初始化、msra初始化、雙線性初始化(bilinear)常量初始化(constant)
深度學習總結(一)——引數初始化
1. 引數初始化的目的是什麼? 為了讓神經網路在訓練過程中學習到有用的資訊,這意味著引數梯度不應該為0。而我們知道在全連線的神經網路中,引數梯度和反向傳播得到的狀態梯度以及入啟用值有關。那麼引數初始化應該滿足以下兩個條件: 初始化必要條件一:各
網路權重初始化方法總結(下):Lecun、Xavier與He Kaiming
目錄 權重初始化最佳實踐 期望與方差的相關性質 全連線層方差分析 tanh下的初始化方法 Lecun 1998 Xavier 2010 ReL
Caffe訓練深度學習網路的暫停與繼續
Caffe訓練深度學習網路的暫停與繼續 博主在訓練Caffe模型的過程中,遇到了如何暫停訓練並斷點繼續訓練的問題。在此記錄下有關這個問題的幾種解決方案。更新於2018.10.27。 方法1:臨時暫停 這種方法是用於臨時暫停Caffe訓練,暫停後可以以完全相同的配置從斷點處繼續
權值初始化方法之Xavier與MSRA
首先介紹一下Xavier等初始化方法比直接用高斯分佈進行初始化W的優勢所在: 一般的神經網路在前向傳播時神經元輸出值的方差會不斷增大,而使用Xavier等方法理論上可以保證每層神經元輸入輸出方差一致。 這裡先介紹一個方差相乘的公式,以便理解Xavier: Xavie
spring原始碼學習之路---深度分析IOC容器初始化過程(三)
分析FileSystemXmlApplicationContext的建構函式,到底都做了什麼,導致IOC容器初始化成功。 public FileSystemXmlApplicationContext(String[] configLocations, boolean ref
深度學習基礎--正則化與norm--區域性響應歸一化層(Local Response Normalization, LRN)
區域性響應歸一化層(Local Response Normalization, LRN) 區域性響應歸一化層完成一種“臨近抑制”操作,對區域性輸入區域進行歸一化。 該層實際上證明已經沒啥用了,一般也不用了。 參考資料:見郵件 公式與計算 該層需要的引數包括:
深度學習基礎--正則化與norm--Ln正則化綜述
L1正則化 L1範數是指向量中各個元素的絕對值之和。 對於人臉任務 原版的人臉畫素是 64*64,顯然偏低,但要提高人臉清晰度,並不能僅靠提高圖片的解析度,還應該在訓練方法和損失函式上下功夫。眾所周知,簡單的 L1Loss 是有數學上的均值性的,會導致模糊。