
LDA主題模型困惑度計算
阿新 • • 發佈:2019-02-10
對於LDA模型,最常用的兩個評價方法困惑度(Perplexity)、相似度(Corre)。
其中困惑度可以理解為對於一篇文章d,所訓練出來的模型對文件d屬於哪個主題有多不確定,這個不確定成都就是困惑度。困惑度越低,說明聚類的效果越好。
計算公式 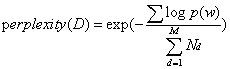 分母是測試集中所有單詞之和,即測試集的總長度,不用排重。其中p(w)指的是測試集中每個單詞出現的概率,計算公式如下
分母是測試集中所有單詞之和,即測試集的總長度,不用排重。其中p(w)指的是測試集中每個單詞出現的概率,計算公式如下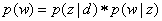 。p(z|d)表示的是一個文件中每個主題出現的概率,就是程式中的.theta檔案,p(w|z)表示的是詞典中的每一個單詞在某個主題下出現的概率,就是程式中的.phi檔案。
。p(z|d)表示的是一個文件中每個主題出現的概率,就是程式中的.theta檔案,p(w|z)表示的是詞典中的每一個單詞在某個主題下出現的概率,就是程式中的.phi檔案。

1 public void getRe(double[][] phi, double[][] theta){
2 double count = 0;
3 int i = 0;
4 Iterator iterator = userWords.entrySet().iterator();
5 while(iterator.hasNext()){
6 Map.Entry entry = (Map.Entry) iterator.next();
7 ArrayList<String> list = (ArrayList<String>) entry.getValue();
8 double mul = 0;
9 for(int j = 0; j < list.size(); j++){
10 double sum = 0;
11 String word = list.get(j);
12 int index = wordMap.get(word);
13 for (int k = 0; k < K; k++){
14 sum = sum + phi[k][index] * theta[i][k];
15 }
16 mul = mul + Math.log(sum);
17 }
18 count = count + mul;
19 i++;
20 }
21 count = 0 - count;
22 P = Math.exp(count / N);
23 System.out.println("Perplexity:" + P);
對於不同Topic所訓練出來的模型,計算它的困惑度。最小困惑度所對應的Topic就是最優的主題數。