
排序穩定性的意義
阿新 • • 發佈:2019-02-11
首先,為什麼會有排序演算法穩定性的說法?只要能排好不就可以了嗎?
看例子
第1行是數字2 記作 1 2
第2行是數字4 記作 2 4
第3行是數字2 記作 3 2
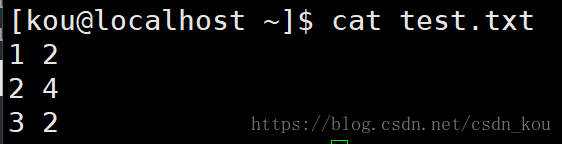
排序後的結果(如果看不懂命令的意思,參照這個部落格)

那麼引入我們的問題,有沒有可能排序結果是這樣子

排序的結果是正確的,可是它卻打亂了原本的檔案順序。
那麼在什麼場景會出現這種情況呢?
我們在管理資料的時候,比如有ID和體重。那麼胖的排前面,輕的排後面,沒問題!如果是體重相等呢?那就按服從ID排序了!
起始穩定排序的意義就是保證兩次排序結果相同,好好體會這句話的意義。
快速排序和歸併排序的平均時間複雜度都是一樣的,那為什麼不全部都用歸併排序?
歸併排序需要開闢額外的空間,在資料較小時,可能不佔優勢。
| 陣列長度 | 快速排序(執行時間/毫秒) | 歸併排序(執行時間/毫秒) |
|---|---|---|
| 100 | 0 | 0 |
| 1000 | 1 | 1 |
| 10000 | 1 | 3 |
| 100000 | 14 | 14 |
| 1000000 | 79 | 120 |
| 10000000 | 982 | 1186 |
| 100000000 | 55733 | 12328 |
| 演算法 | 最壞時間複雜性 | 平均時間複雜性 |
|---|---|---|
| 快速排序 | n^2 | n*log(n) |
| 歸併排序 | n*log(n) | n*log(n) |