
機器學習中怎樣的特徵才是好特徵
講座視訊:What Makes a Good Feature? - Machine Learning Recipes #3
https://www.youtube.com/watch?v=N9fDIAflCMY
分類器只有在你使用好的feature時,才能有好的效能。提供或找出好的feature是使用機器學習時的最重要工作之一。
假設要對狗的類別進行分類,區分是greyhound還是labrador。

我們考慮兩個特徵,身高(inches)和眼睛顏色。
我們這裡假設這兩種狗眼睛只有blue和brown兩種顏色。
我們先分析特徵身高。
通常情況下,greyhound要比labrador高,但現實世界會比較複雜,兩種狗的身高都在一個範圍內變化。
我們用python寫些程式碼來生成隨機的身高資料,其中,greyhound平均身高為28,labrador平均身高為24。我們畫出直方圖。紅色是greyhound,藍色是labrador。

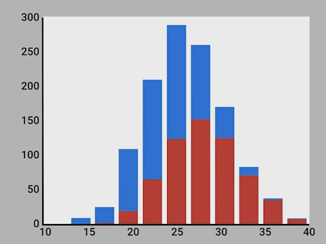
我們來分析這張直方圖。先看左邊,比如,身高為20 inches時,如果要估計這種身高的狗,我們應該認為它是labrador,因為這種身高情況下,80%可能性是labrador,而只有20%可能性是greyhound。再看右邊,比如,身高為35 inches時,這時95%的可能性是greyhound,所以,我們應該估計這種情況下的狗為greyhound。
但是,我們也注意到中間部分,比如25 inches處,在這些地方,兩種狗的可能性相差不大,所以身高為這些值時,很難區分。
所以,身高是一個useful的feature,但不perfect。
如果要找出你應該用什麼樣的特徵,那你可以做一個模擬的思考實驗,假設你自己就是分類器,你現在試圖區分一條狗是greyhound,還是labrador,你希望知道其他一些什麼東西?你可能會問:它們頭髮的稀疏程度怎麼樣?它們跑的速度怎麼樣?它們多重?
事實上,應該用多少特徵,更多一種art,而不是一種science。但從經驗上來說,你自己需要多少特徵來分類,那麼分類器可能也需要多少。
現在再來看另一個特徵,眼睛的顏色。我們假設兩種狗都只有2種顏色:Blue和Brown,且狗的顏色和它品種無關。
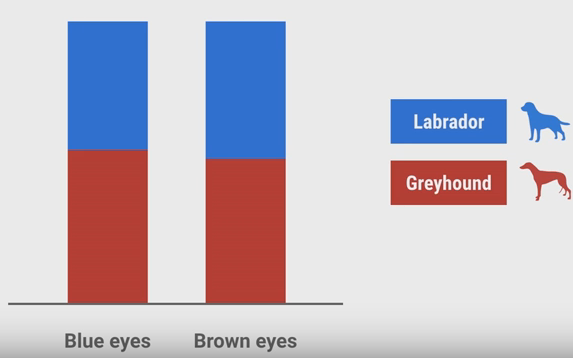
它的直方圖統計結果可能像上圖一樣。這張圖沒有告訴我們任何東西,因為兩種顏色下,兩種狗的可能性都差不多,所以,狗的顏色也是沒有用的特徵。如果在使用分類器時,加入了這樣沒用的特徵,那麼,會影響分類器的分類準確性。這樣的特徵可能會看起來有用,但僅僅是因為資料本身的偶然性。特別是當你的訓練資料非常少的情況下,更可能使你錯誤地認為這樣的特徵有用。
而且,我們應該使用相互independent的特徵。因為相互independent的特徵能給你不用角度的資訊。例如,你在資料中已經有了以inches表示的身高,如果再加入以cm表示的身高就沒有意義,因為提供不了更多的資訊。你應該儘量去掉類似的冗餘的特徵,因為很多分類器很敏感,遇見這樣高度相關的特徵時,它會錯誤地認為這個特徵更加重要,這顯然不是我們所希望的。
此外,我們應該使用容易理解的特徵。比如,我們現在要預測從一個城市寄一個紙質mail,要多少天才能到另一個城市。顯然,兩個城市越遠,花的天數越多。
這裡,城市之間的英里數miles就是一個非常好的特徵。還有一種很差的選擇是使用兩個城市的座標:

從人理解的角度來說,知道miles很容易估計出天數,而僅僅知道座標就不太容易估計。而如果使用座標這樣難理解的特徵,你會比使用容易理解的特徵需要使用多得多的資料來訓練分類器。
總結一下,理想的特徵應該是:
1) Informative,有資訊的;
2) Independent,與其他特徵相獨立的;
3) Simple,簡單容易理解的。