
邏輯迴歸-logistic regression 詳解
一, 為什麼要使用logistic 函式
從線性分類器談起
給定一些資料集合,他們分別屬於兩個不同的類別。例如對於廣告資料來說,是典型的二分類問題,一般將被點選的資料稱為正樣本,沒被點選的資料稱為負樣本。現在我們要找到一個線性分類器,將這些資料分為兩類(當然實際情況中,廣告資料特別複雜,不可能用一個線性分類器區分)。用X表示樣本資料,Y表示樣本類別(例如1與-1,或者1與0)。我們線性分類器的目的,就是找到一個超平面(Hyperplan)將兩類樣本分開。對於這個超平面,可以用以下式子描述:
對於logistic迴歸,有:
其中
這個公式,對機器學習稍微有點了解的同學可能都特別熟悉,不光在logistic迴歸中,在SVM中,在ANN中,都能見到他的身影,應用特別廣泛。大部分資料在談到這個式子時候,都是直接給出來。但是不知道大家有沒有想過,既然這個式子用途這麼廣泛,那我們為什麼要用它呢?
是不是已經有好多人愣住了。大家都是這麼用的。書上都是這麼寫的啊。是的,但是當一個東西老在你眼前晃來晃去的時候,你是不是應該想想為什麼呢?反正對於我來說,如果一個東西在我眼前都出現了第三次了而我還不知其所以然,我一定會去想方設法弄明白為什麼。
為什麼要用Logistic函式
學過模式識別的同學肯定學過各種分類器。分類器中最簡單的自然是線性分類器,線性分類器中,最簡單的應該就屬於感知器了。在上個世紀五六十年代,感知器就出現了:
感知器的思想,就是對所有特徵與權重做點積(內積),然後根據與閾值做大小比較,將樣本分為兩類。稍微瞭解一點神經網路的同學,對一下這幅圖一定不陌生:

沒錯,這幅圖描述的就是一個感知器。
我考研考的是控制原理,如果學過控制原理或者學過訊號系統的同學,就知道感知器相當於那兩門課中的階躍函式:
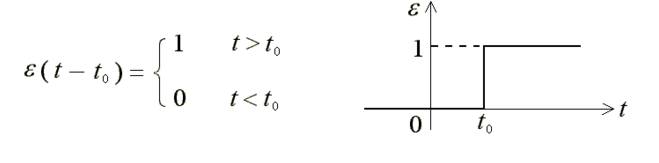
這兩者的本質都是一致的,即通過劃定一個閾值,然後比較樣本與閾值的大小來分類。
這個模型簡單直觀,實現起來也比較容易(要不怎麼說是最簡單的現行分類器呢)。但是問題在於,這個模型不夠光滑。第一,假設
囉囉嗦嗦寫了這麼多了,終於輪到logistic函數出場了。對比前面的感知器或者階躍函式,他有什麼優點呢?
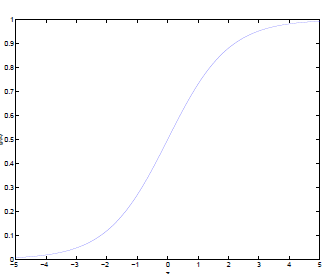
通過logistic函式的影象,我們很容易總結出他的以下優點:
1.他的輸入範圍是
2.他是一個單調上升的函式,具有良好的連續性,不存在不連續點。
寫到這裡,小夥伴們應該都明白為什麼要使用logistic函數了吧。
二,損失函式(cost function)詳解
轉自: http://blog.csdn.net/bitcarmanlee/article/details/51165444
有監督學習
機器學習分為有監督學習,無監督學習,半監督學習,強化學習。對於邏輯迴歸來說,就是一種典型的有監督學習。
既然是有監督學習,訓練集自然可以用如下方式表述:
對於這m個訓練樣本,每個樣本本身有n維特徵。再加上一個偏置項
其中
李航博士在統計學習方法一書中給分類問題做了如下定義:
分類是監督學習的一個核心問題,在監督學習中,當輸出變數Y取有限個離散值時,預測問題便成為分類問題。這時,輸入變數X可以是離散的,也可以是連續的。監督學習從資料中學習一個分類模型或分類決策函式,稱為分類器(classifier)。分類器對新的輸入進行輸出的預測(prediction),稱為分類(classification).
其中一個重要的原因,就是要將Hypothesis(NG課程裡的說法)的輸出對映到0與1之間,既:
同樣是李航博士統計學習方法一書中,有以下描述:
統計學習方法都是由模型,策略,和演算法構成的,即統計學習方法由三要素構成,可以簡單表示為:
對於logistic迴歸來說,模型自然就是logistic迴歸,策略最常用的方法是用一個損失函式(loss function)或代價函式(cost function)來度量預測錯誤程度,演算法則是求解過程,後期會詳細描述相關的優化演算法。
logistic函式求導
此求導公式在後續推導中會使用到
常見的損失函式
機器學習或者統計機器學習常見的損失函式如下:
1.0-1損失函式 (0-1 loss function)
相關推薦
邏輯迴歸-logistic regression 詳解
一, 為什麼要使用logistic 函式 從線性分類器談起 給定一些資料集合,他們分別屬於兩個不同的類別。例如對於廣告資料來說,是典型的二分類問題,一般將被點選的資料稱為正樣本,沒被點選的資料稱為負樣本。現在我們要找到一個線性分類器,將這些資料分為
邏輯迴歸(Logistic Regression)詳解,公式推導及程式碼實現
邏輯迴歸(Logistic Regression) 什麼是邏輯迴歸: 邏輯迴歸(Logistic Regression)是一種基於概率的模式識別演算法,雖然名字中帶"迴歸",但實際上是一種分類方法,在實際應用中,邏輯迴歸可以說是應用最廣泛的機器學習演算法之一 迴歸問題怎麼解決分類問題? 將樣本的特徵和
機器學習專案實戰--邏輯迴歸(Logistic Regression)
(一)邏輯迴歸 邏輯迴歸演算法是一種廣義的線性迴歸分析模型, 可用於二分類和多分類問題, 常用於資料探勘、疾病自動診斷、經濟預測等領域。通俗來說, 邏輯迴歸演算法通過將資料進行擬合成一個邏輯函式來預估一個事件出現的概率,因此被稱為邏輯迴歸。因為演算法輸出的為事件發生概率, 所以其輸出值應該在0
機器學習演算法與Python實踐之邏輯迴歸(Logistic Regression)(二)
#!/usr/bin/python # -*- coding:utf-8 -*- import numpy as np from numpy import * import matplotlib.pyplot as plt #處理資料函式 def loadDataSet():
邏輯迴歸(Logistic Regression)演算法小結
一、邏輯迴歸簡述: 回顧線性迴歸演算法,對於給定的一些n維特徵(x1,x2,x3,......xn),我們想通過對這些特徵進行加權求和彙總的方法來描繪出事物的最終運算結果。從而衍生出我們線性迴歸的計算公式: 向量化表示式: &n
林軒田--機器學習技法--SVM筆記5--核邏輯迴歸(Kernel+Logistic+Regression)
核邏輯迴歸 這一章節主要敘述的內容是如何使用SVM來做像logistics regression那樣的soft binary classification(輸出正類的概率值),如何在此基礎上加上核方法。 1. 把SVM看成一種regularization
邏輯迴歸模型(Logistic Regression, LR)基礎
邏輯迴歸(Logistic Regression, LR)模型其實僅線上性迴歸的基礎上,套用了一個邏輯函式,但也就由於這個邏輯函式,使得邏輯迴歸模型成為了機器學習領域一顆耀眼的明星,更是計算廣告學的核心。本文主要詳述邏輯迴歸模型的基礎,至於邏輯迴歸模型的優化、邏輯迴歸與計算廣告學等,請關注後續文章。 1
機器學習/邏輯迴歸(logistic regression)/--附python程式碼
個人分類: 機器學習 本文為吳恩達《機器學習》課程的讀書筆記,並用python實現。 前一篇講了線性迴歸,這一篇講邏輯迴歸,有了上一篇的基礎,這一篇的內容會顯得比較簡單。 邏輯迴歸(logistic regression)雖然叫回歸,但他做的事實際上是分類。這裡我們討論二元分類,即只分兩類,y屬於{0,1}。
機器學習之邏輯迴歸(logistic regression)
概述 邏輯斯蒂迴歸實質是對數機率迴歸(廣義的線性迴歸),是用來解決分類問題的。 其中sigmoid用來解決二分類問題,softmax解決多分類問題,sigmoid是softmax的特殊情況。 數學建模直接針對分類可能性建模。 引數學習可用極大似然估計
Python手擼邏輯迴歸(logistic regression)
與線性迴歸用於預測連續值不同,邏輯歸回用於分類,原理與線性迴歸類似,定義損失函式,然後最小化損失,得到引數既模型,只不過損失的定義不同。 邏輯迴歸的假設如圖1所示,可以理解為線性迴歸外面套了一層sigmoid函式g(z),sigmoid函式影象如圖2所示,該函式有很好的數學
邏輯迴歸(Logistic+Regression)經典例項
房價預測 資料集描述 資料共有81個特徵 SalePrice - the property’s sale price in dollars. This is the target variable that you’re trying to pre
邏輯迴歸(Logistic Regression)
1、總述 邏輯迴歸是應用非常廣泛的一個分類機器學習演算法,它將資料擬合到一個logit函式(或者叫做logistic函式)中,從而能夠完成對事件發生的概率進行預測。 2、由來 要說邏輯迴歸,我們得追溯到線性迴歸,想必大家對線性迴歸都有一定的瞭解,即對於多維空間中存在
邏輯迴歸梯度下降法詳解
引言 邏輯迴歸常用於預測疾病發生的概率,例如因變數是是否惡性腫瘤,自變數是腫瘤的大小、位置、硬度、患者性別、年齡、職業等等(很多文章裡舉了這個例子,但現代醫學發達,可以通過病理檢查,即獲取標本放到顯微鏡下觀察是否惡變來判斷);廣告界中也常用於預測點選率或者轉化
邊框迴歸(Bounding Box Regression)詳解
Bounding-Box regression 最近一直看檢測有關的Paper, 從rcnn, fast rcnn, faster rcnn, yolo, r-fcn, ssd,到今年cvpr最新的yolo9000。這些paper中損失函式都包含了邊框迴歸,除
邏輯迴歸(logistic regression)和線性迴歸(linear regression)
序號 邏輯迴歸 線性迴歸 模型歸類 離散選擇法模型 迴歸分析 數值型別 二元 一元或多元 公式 P(Y=1│X=x)=exp(x'β)/(1+exp(x'β)) 邏輯迴歸 Logit模型(Logit model,也譯作“評定模型”,“分類評定模型”,又作Logistic
樸素貝葉斯法(naive bayes)邏輯迴歸(logistic regression)線性迴歸
樸素貝葉斯法實際上學習到生成資料的機制,所以屬於生成模型。條件獨立假設等於是說用於分類的特徵在類確定的條件下都是條件獨立的,但是有的時候會失去一些分類準確性。對於給定的輸入x,通過學習到的模型計算後驗概率分佈,將後驗概率最大的類作為x的類輸出主要是使用貝葉斯公式推導的過程。在
機器學習演算法與Python實踐之(七)邏輯迴歸(Logistic Regression)
Logistic regression (邏輯迴歸)是當前業界比較常用的機器學習方法,用於估計某種事物的可能性。比如某使用者購買某商品的可能性,某病人患有某種疾病的可能性,以及某廣告被使用者點選的可能性等。(注意這裡是:“可能性”,而非數學上的“概率”,logisitc迴
通俗地說邏輯迴歸【Logistic regression】演算法(一)
在說邏輯迴歸前,還是得提一提他的兄弟,線性迴歸。在某些地方,邏輯迴歸演算法和線性迴歸演算法是類似的。但它和線性迴歸最大的不同在於,邏輯迴歸是作用是分類的。 還記得之前說的嗎,線性迴歸其實就是求出一條擬合空間中所有點的線。邏輯迴歸的本質其實也和線性迴歸一樣,但它加了一個步驟,邏輯迴歸使用sigmoid函式轉換線
通俗地說邏輯迴歸【Logistic regression】演算法(二)sklearn邏輯迴歸實戰
前情提要: 通俗地說邏輯迴歸【Logistic regression】演算法(一) 邏輯迴歸模型原理介紹 上一篇主要介紹了邏輯迴歸中,相對理論化的知識,這次主要是對上篇做一點點補充,以及介紹sklearn 邏輯迴歸模型的引數,以及具體的實戰程式碼。 1.邏輯迴歸的二分類和多分類 上次介紹的邏輯迴歸的內容,基本
廣義線性迴歸之邏輯斯諦迴歸( Logistic Regression)
廣義線性模型 邏輯斯諦迴歸概念可以認為是屬於廣義線性迴歸的範疇,但它是用來進行分類的。 線性模型的表示式為: f (