
Deep Learning(深度學習)之(六)【深度神經網路壓縮】Deep Compression (ICLR2016 Best Paper)
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman coding
這篇論文是Stanford的Song Han的 ICLR2016 的 best paper,Song Han寫了一系列網路壓縮的論文,這是其中一篇,更多論文筆記也會在後續部落格給出。
首先,給這篇論文的清晰結構點贊,論文題目就已經概括了文章的三個重點,而且每個部分圖文並茂,文章看起來一點都不費力,不愧是 ICLR 2016 best paper !
摘要
為什麼要壓縮網路?
做過深度學習的應該都知道,NN大法確實效果很贊,在各個領域輕鬆碾壓傳統演算法,不過真正用到實際專案中卻會有很大的問題:
- 計算量非常巨大;
- 模型特別吃記憶體;
這兩個原因,使得很難把NN大法應用到嵌入式系統中去,因為嵌入式系統資源有限,而NN模型動不動就好幾百兆。所以,計算量和記憶體的問題是作者的motivation;
如何壓縮?
論文題目已經一句話概括了:
- Prunes the network:只保留一些重要的連線;
- Quantize the weights:通過權值量化來共享一些weights;
- Huffman coding:通過霍夫曼編碼進一步壓縮;
效果如何?
Pruning:把連線數減少到原來的 1/13~1/9;
Quantization
最終效果:
- 把AlextNet壓縮了35倍,從 240MB,減小到 6.9MB;
- 把VGG-16壓縮了49北,從 552MB 減小到 11.3MB;
- 計算速度是原來的3~4倍,能源消耗是原來的3~7倍;
Network Pruning
其實 network pruning 技術已經被廣泛應用到CNN模型的壓縮中了。 早期的一些工作中,LeCun 用它來減少網路複雜度,從而達到避免 over-fitting 的效果; 近期,其實也就是作者的第一篇網路壓縮論文中,通過剪枝達到了 state-of-the-art 的結果,而且沒有減少模型的準確率;

從上圖的左邊的pruning階段可以看出,其過程是:
- 正常的訓練一個網路;
- 把一些權值很小的連線進行剪枝:通過一個閾值來剪枝;
- retrain 這個剪完枝的稀疏連線的網路;
為了進一步壓縮,對於weight的index,不再儲存絕對位置的index,而是儲存跟上一個有效weight的相對位置,這樣index的位元組數就可以被壓縮了。
論文中,對於卷積層用 8bits 來儲存這個相對位置的index,在全連線層中用 5bits 來儲存;

上圖是以用3bits儲存相對位置為例子,當相對位置超過8(3bits)的時候,需要在相對位置為8的地方填充一個0,防止溢位;
Trained Quantization and Weight Sharing
前面已經通過權值剪枝,去掉了一些不太重要的權值,大大壓縮了網路; 為了更進一步壓縮,作者又想到一個方法:權值本身的大小能不能壓縮?
答案當然是可以的,具體怎麼做請看下圖:

假設有一個層,它有4個輸入神經元,4個輸出神經元,那麼它的權值就是4*4的矩陣; 圖中左上是weight矩陣,左下是gradient矩陣。可以看到,圖中作者把 weight矩陣 聚類成了4個cluster(由4種顏色表示)。屬於同一類的weight共享同一個權值大小(看中間的白色矩形部分,每種顏色權值對應一個cluster index);由於同一cluster的weight共享一個權值大小,所以我們只需要儲存權值的index 例子中是4個cluster,所以原來每個weight需要32bits,現在只需要2bits,非常簡單的壓縮了16倍。而在 權值更新 的時候,所有的gradients按照weight矩陣的顏色來分組,同一組的gradient做一個相加的操作,得到是sum乘上learning rate再減去共享的centroids,得到一個fine-tuned centroids,這個過程看上圖,畫的非常清晰了。
實際中,對於AlexNet,卷積層quantization到8bits(256個共享權值),而全連線層quantization到5bits(32個共享權值),並且這樣壓縮之後的網路沒有降低準確率
Weight Sharing
具體是怎麼做的權值共享,或者說是用什麼方法對權值聚類的呢?
其實就用了非常簡單的 K-means,對每一層都做一個weight的聚類,屬於同一個 cluster 的就共享同一個權值大小。 注意的一點:跨層的weight不進行共享權值;
Initialization of Shared Weights
做過 K-means 聚類的都知道,初始點的選擇對於結果有著非常大的影響,在這裡,初始點的選擇同樣會影響到網路的效能。作者嘗試了很多生產初始點的方法:Forgy(random), density-based, and linear initialization。

畫出了AlexNet中conv3層的權重分佈,橫座標是權值大小,縱座標表示分佈,其中紅色曲線表示PDF(概率密度分佈),藍色曲線表示CDF(概率密度函式),圓圈表示的是centroids:黃色(Forgy)、藍色(density-based)、紅色(linear)。
作者提到:大的權值往往比小的權值起到更重要的作用,不過,大的權值往往數量比較少;可以從圖中看到,Forgy 和 density-based 方法產生的centroids很少落入到大權值的範圍中,造成的結果就是忽略了大權值的作用;而Linear initialization產生的centroids非常平均,沒有這個問題存在;
後續的實驗結果也表明,Linear initialization 的效果最佳。
Huffman Coding
Huffman Coding 是一種非常常用的無損編碼技術。它按照符號出現的概率來進行變長編碼。

上圖的權重以及權值索引分佈來自於AlexNet的最後一個全連線層。由圖可以看出,其分佈是非均勻的、雙峰形狀,因此我們可以利用Huffman編碼來對其進行處理,最終可以進一步使的網路的儲存減少20%~30%。
Experiment Results
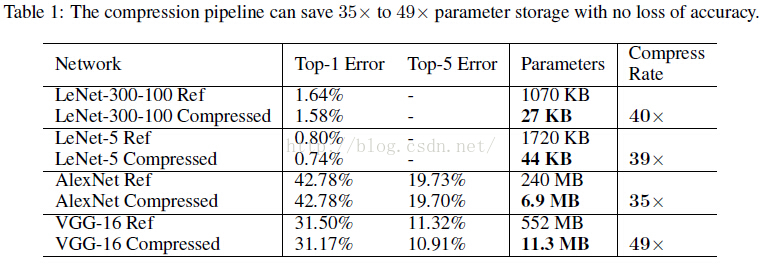
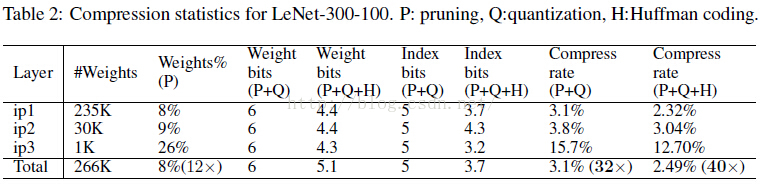

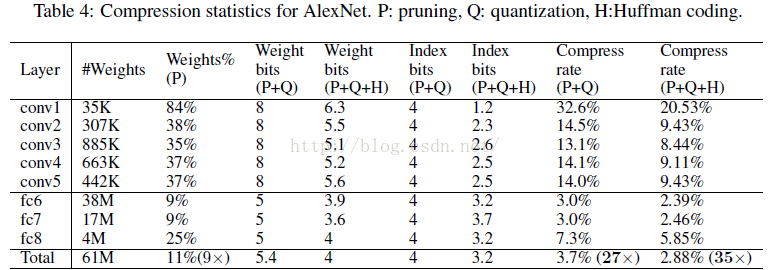
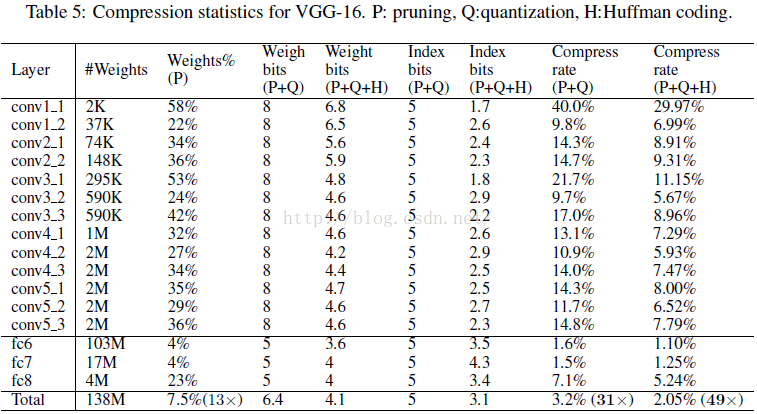

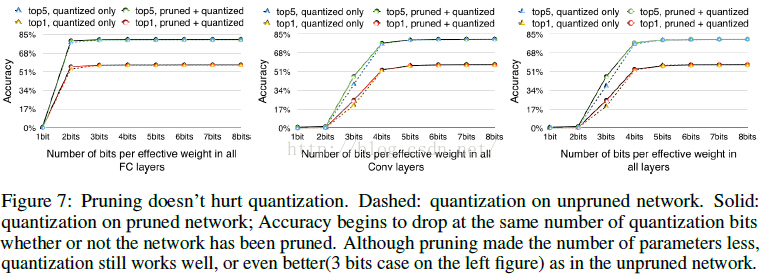
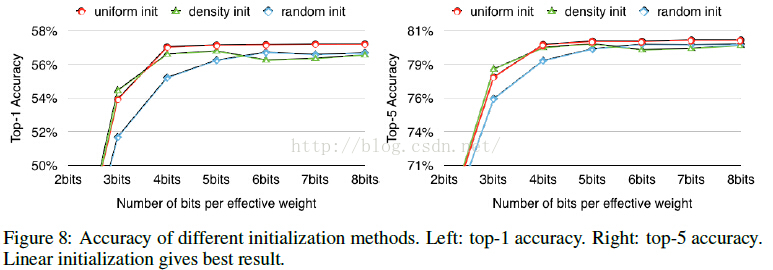

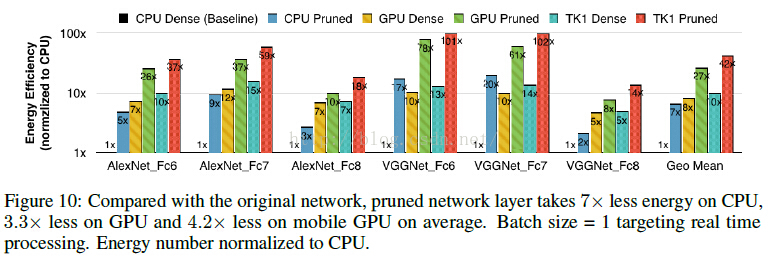
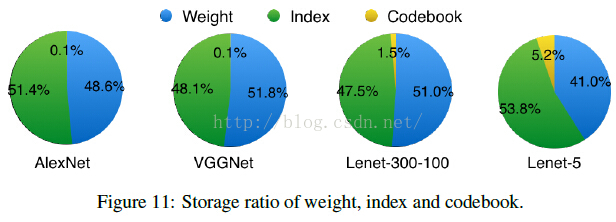
簡單貼一個最終得到的模型跟BVLC baseline 和其他基於alexnet的壓縮網路的效能對比:

更詳細內容,請參考原文。