
2017知乎看山杯總結(多標籤文字分類)
任務描述:參賽者需要根據知乎給出的問題及話題標籤的繫結關係的訓練資料,訓練出對未標註資料自動標註的模型。
標註資料中包含 300 萬個問題,每個問題有 1 個或多個標籤,共計1999 個標籤。每個標籤對應知乎上的一個「話題」,話題之間存在父子關係,並通過父子關係組織成一張有向無環圖(DAG)。
由於涉及到使用者隱私及資料安全等問題,本次比賽不提供問題、話題描述的原始文字,而是使用字元編號及切詞後的詞語編號來表示文字資訊。同時,鑑於詞向量技術在自然語言處理領域的廣泛應用,比賽還提供字元級別的 embedding 向量和詞語級別的 embedding 向量,這些 embedding 向量利用知乎上的海量文字語料,使用 google word2vec 訓練得到。
簡單來說,這是一個多標籤文字分類問題,基本上都是使用深度學習方法。
結果:在public board 上排名第五,private board 上排名第六。
 |
 |
我是從7月1號開始報名比賽,一直到8月16日早上結束,一共一個半月時間,除了開始三週有些其他事情,後面差不多一個月時間基本上都在做比賽。之前也做過一個文字的比賽(命名實體識別+分類),但是之前積累不夠,有沒有找到合適的隊友,所以那個比賽最後成績很差,後期基本上就放棄了。這次還是一個人參賽(一個人打比賽好累…)這一個半月確實很累,經常寫程式碼寫到半夜,然後一大早又起來看模型跑的結果,發現出錯了趕緊改過來;跟同學搶機器;各種想法沒提升;有一次把驗證集寫成訓練集來用結果過擬合白白高興了…和我一個實驗室的還有兩組同學參加了,他們分別拿了第一和第二…唉唉,自己還是太菜了。不過在這次比賽中,確實學習了好多,這裡寫下比賽中的一些經驗,希望對大家特別是對於競賽入門者能有所幫助
硬體準備
在這次比賽中,訓練集有300萬個問題;測試集有21.7萬個問題。賽方提供了預訓練好的詞向量矩陣,一共有40+萬個詞。所以資料量還是非常大的,如果沒有伺服器,基本上沒法做。我們組一共就一臺伺服器,一塊顯示卡titan X,64G記憶體,CPU12程序。但是,我們有十幾個同學呀,雖然平時主要就三四個人用,但是和其他大佬們多卡多機相比,這配置確實寒酸。跑一個模型幾個小時到二三十個小時,所以,沒有機器,根本別想取得好成績。
此外,一定要準備充足的硬碟空間,最好能有500G, 1T或者更多。因為在這次比賽中,我就因為硬碟滿了,只能把資料放在兩個分割槽進行操作,可能是前期沒有注意管理,導致後來檔案組織非常混亂。
檔案管理
所有的比賽都應該一樣, 就是“不擇手段”地達到更好的成績,而要取得較好的成績,不可避免地會用到整合學習,所以你不可能靠一兩個模型就能夠取得很好的結果。在這次比賽中最後獲獎的所有隊伍都用了模型融合,模型數量少的有十幾個,多個兩百多個,我最後提交的結果用了37個模型。所以從一開始,你就應該管理好模型和檔案的命名,這樣才不至於後期命名混亂,因為缺乏經驗,所以我也在這上面吃了不少虧。
模型儲存
因為詞向量非常大,所以每個模型儲存下來都非常大(1G+),這樣就非常佔空間。所以應該怎麼儲存模型也是有講究的,我的經驗大概如下:
- 設定一個最低 f1值(last_f1, 這次比賽評價函式是 f1,如果是準確率的話應該設定一個最低的準確率);每迭代 valid_step 步,就預測整個驗證集,計算f1值,如果高於last_f1, 則儲存模型。
- 每個網路儲存最好的模型即可,也就是說設定 max_keep=1
為什麼只儲存最好的一個就好了?我嘗試過儲存最好的三個模型,假設為m1, m2, m3 然後把這三個模型以平均加權的方式融合得到 M,這樣M的結果要比最好模型 m1 的結果好(在這次比賽中,能高2.5個千分點左右,這已經很好了),但是,但是,但是,在後面和其他結構的模型再次融合,M的效果不如直接使用 m1。我覺得可能是與 M 相比,對於每個樣本的預測概率,m1 的方差更大些。比如對於樣本a和b,m1預測分別屬於類別1的概率是0.9 和 0.1; M預測分別屬於類別1的概率是0.7和0.3。這種情況下和其他模型融合,m1的作用會更大一些,因為它對正樣本的確定性很高,決定性更大。在其他資料或者比賽中,我覺得應該也是一樣的。所以,只需要儲存最好的一個模型,這樣能節省不少硬碟空間。
使用 tensorboard
tensorboard 很好用,通過 tensorboard 檢視損失變化能夠很好地幫助我們進行調參,當然同時也可以看看模型結構有沒有寫錯了… 但是有一點需要注意,如果你的模型很大,那麼tensorboard中儲存的資料也會非常大,所以還是很佔空間的。

圖3 網路結構
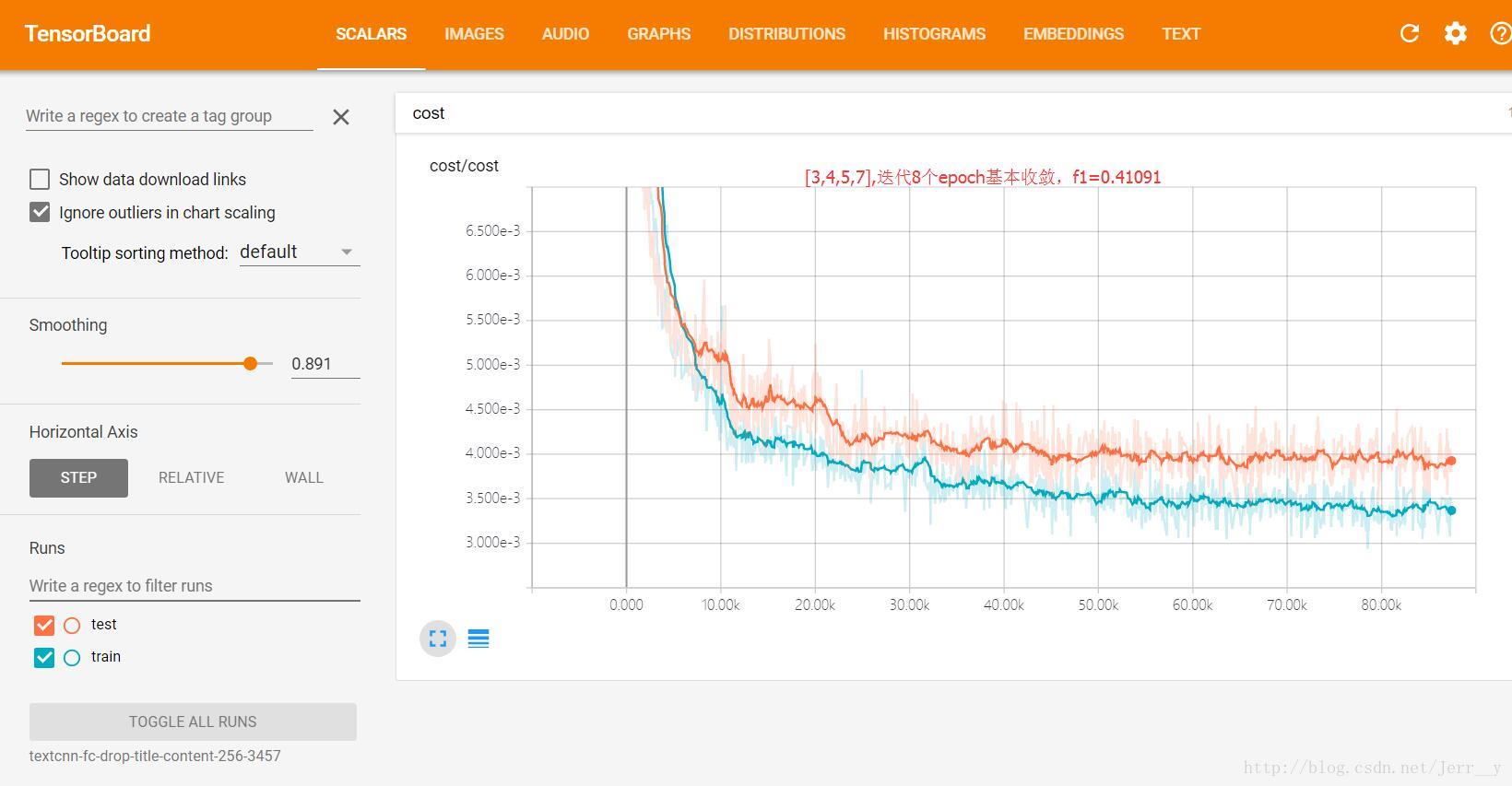
圖4 損失變化
模型構造與調參
在這次比賽中,主要使用的基本模型有 TextCNN, BiGRU, HAN(Hierarchical Attention Networks ), FastText, RNN+CNN(區別與RCNN)。然後各種結構拼接,修改。比賽的目的很明確,就是取得更好的分數。所以我們的目的並不只是把原論文的結構套過來看看結果,而是要在給定的資料集上不斷改進,不斷調整引數。同樣的一個模型,可能就是某個地方有一點小小的差別,或者學習率沒調好結果就會差很多。這些都是需要自己不斷積累,在實驗過程中不斷總結出來的。但是在大體上,有些問題還是需要注意的。
- 關於學習率和學習率衰減。學習率非常重要,一般都會使用自適應的優化器,比如 adam, 但是還是需要嚴謹地選擇初始學習率。至於學習率衰減,TensorFlow 中提供了tf.train.exponential_decay()函式,這函式有個引數staircase,我的經驗是一定要設為staircase=True,也就是迭代好多步以後再跳一次,而不是沒迭代一次都調整學習率。你會在tensorboard中看到,學習率衰減的那一瞬間,loss都會迅速地下降一次。在TextCNN中特別明顯。我看到有些人用adam優化器的時候並沒有使用 decay,而是隻提供了一個初始學習率,但是我在實驗中發現,使用Exponential Decay效果明顯要比沒用好。而且decay_rate 和 decay_step 的選擇也很關鍵。但是有些隊伍根本就沒做這個效果卻非常好,所以現在我還是比較疑惑。之後弄清楚了再來補充。相關討論可參考下面:
It depends. ADAM updates any parameter with an individual learning rate. This means that every parameter in the network have a specific learning rate associated.
But the single learning rate for parameter is computed using lambda (the initial learning rate) as upper limit. This means that every single learning rate can vary from 0 (no update) to lambda (maximum update).
The learning rates adapt themselves during train steps, it’s true, but if you want to be sure that every update step do not exceed lambda you can than lower lambda using exponential decay or whatever. It can help to reduce loss during the latest step of training, when the computed loss with the previously associated lambda parameter has stopped to decrease.
adam對於每個引數都會自動調整學習率,但是我們傳進去的學習率是進行適應學習率計算的基礎。所以加上decay還是會有作用的,不過具體問題具體嘗試才能知道有沒有用。
關於模型大小。這個其實很關鍵,首先要看資料量,像知乎的這次比賽資料量還是非常大的,所以模型也是應該比較大的。就這個資料集,相同結構,大一點的模型可能比小一點的模型更加節省時間。因為模型引數多了,迭代一次學習到的資訊要比模型多,所以收斂的速度可能比小模型更加快。所以,在比賽初期,你可以先用小模型把一個結構跑通,然後開始可以嘗試改進結構,加深模型,加寬模型。在這次比賽中,第三名的隊伍他們的模型比我的基本大了5,6倍,他們最好的CNN模型訓了一週,但是對於我來說這是絕對不允許的,因為就一臺機器,如果一個模型訓上一週意味著我都不用做了,萬一效果還不好呢。所以,硬體非常非常關鍵。
關於 batch_size。一般來說,幾十到幾百的batch_size都是可以接受的,那麼選擇大batch_size 還是小的batch_size呢?我認為,在這麼大的一個數據集下,儘量把GPU撐滿是個不錯的選擇,但是也不能太大,最好別超過1000。batch_size 大些,收斂速度相對來說應該會快些。batch_size越大,那麼梯度的方向相對會更貼合“全域性梯度”,更加“準確”。這樣的話,我覺得學習率也可以稍微調大一點。但是,因為有很多很多的區域性最優點,我們不能把 batch_size 設得太大,這樣每個batch 的梯度才會帶有一些“噪聲”來幫助我們跳出這些區域性最優點。具體的大小當然還是要根據資料集,通過實驗來選擇,還有你的視訊記憶體大小來選擇。
因為賽方提供了預訓練好的詞向量和字向量,而且都是在更大的資料集上訓練的,所以肯定會比自己訓練的要好。但是,embedding 可以在迭代一定輪次(epoch)以後再進行fine-tune,這樣有兩個好處:一是embedding非常大,如果不對embedding計算梯度的話能減少不少計算,節省時間;二是一開始就是用大學習率優化embedding,容易把原本預訓練學習到的資訊丟失。在TensorFlow中要想先固定embedding,在一定輪次以後再優化的話,可以通過定義兩個優化器來實現。可以參考這個程式碼中main()部分。對於知乎的這個資料集,這樣做對於RNN效果比較好,但是對於TextCNN似乎幫助不大。
關於融合。一定要從一開始就為最後模型融合做好準備。模型融合的方法有很多,最常見的比如bagging, stacking 等。在這次比賽中,由於資料量太大,而且計算時間非常長,所以對於我來說,基本上沒有辦法做stacking,所以最後使用了線性加權。好而不同,這是模型融合最最關鍵的地方。所以BIGRU與TextCNN融合要比BIGRU與HAN效果好很多,因為TextCNN與BIGRU結構相差非常大,而HAN裡邊就是用了 BIGRU。所以在訓練不同模型時,一定儘量增加模型之間的差異性。在這個比賽中,使用字向量訓練的模型要比詞向量訓練的模型差很多(1個百分點以上),但是在模型融合中,一個好的字向量模型帶來的提升非常大。
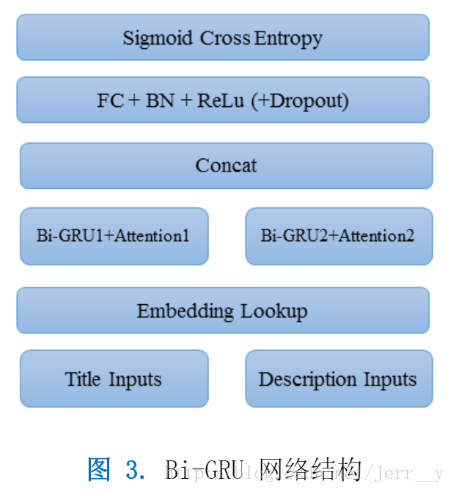
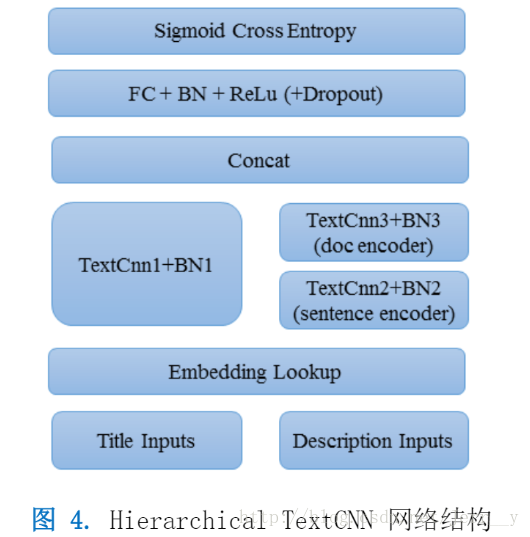
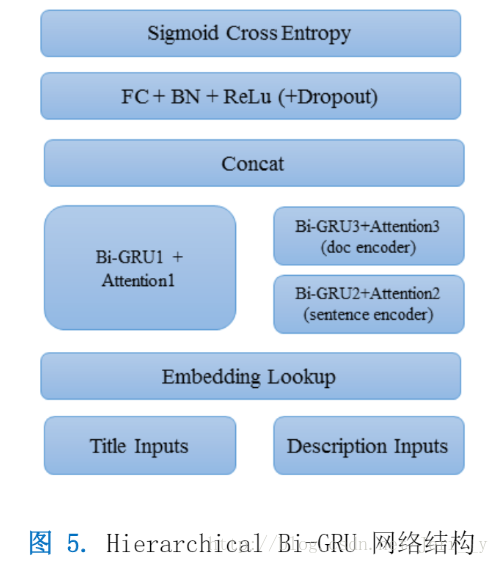
在這次比賽中,主要使用的模型結構如下:
 |
 |
 |
 |
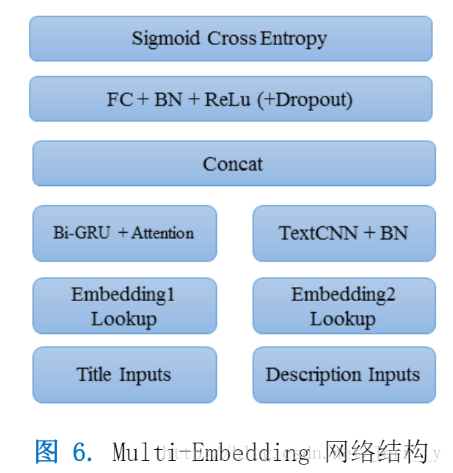 |
其他
比賽結束後,學習其他組的參賽方案,確實有很多值得學習的地方。非常感謝知乎組織的這次比賽,最後他們還公佈了所有獲獎隊伍的參賽方案,詳細見:「2017 知乎 · 看山杯機器學習挑戰賽」結束,誰獲獎了?知乎還會做什麼?