
多標籤影象分類--HCP: A Flexible CNN Framework for Multi-Label Image Classification
HCP: A Flexible CNN Framework for Multi-Label Image Classification
PAMI 2016
本文提出了一個 CNN 網路 HCP 不需要真值訓練資料的情況下可以完成對多標籤影象分類問題。
單標籤和多標籤影象

HCP 是怎麼處理一幅影象的了?
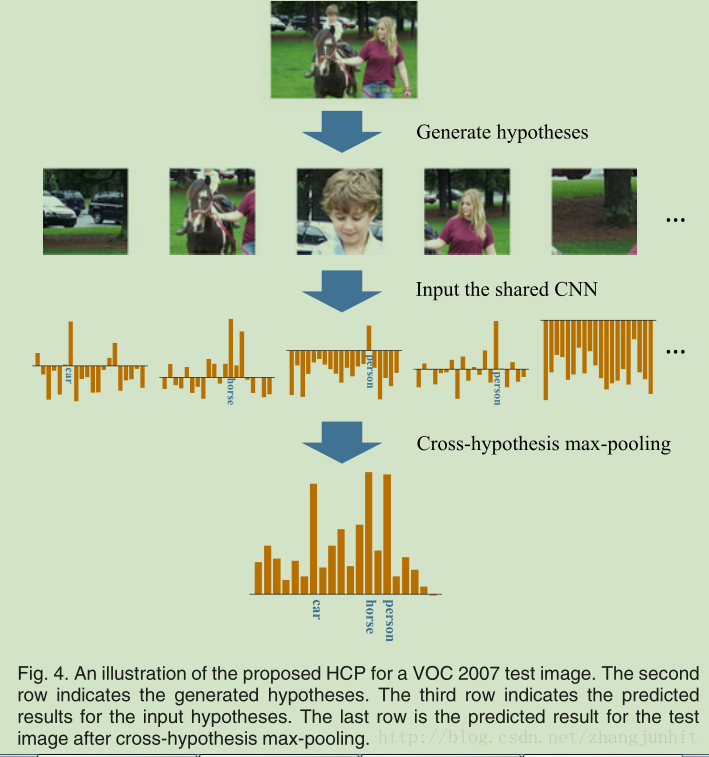
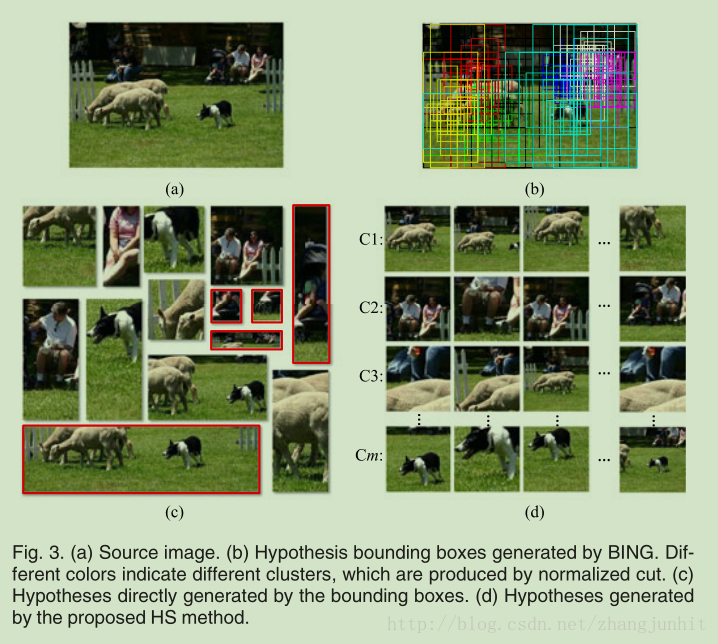
首先提取影象中的候選區域,然後對每個候選區域進行分類,最後使用 cross-hypothesis max-pooling 將影象中所有的候選區域分類結果進行融合,得到整個影象的多類別標籤。
HCP 的框架示意圖:

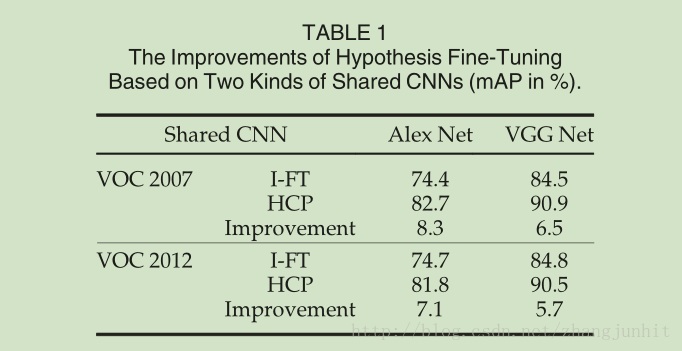
效能提升對比:

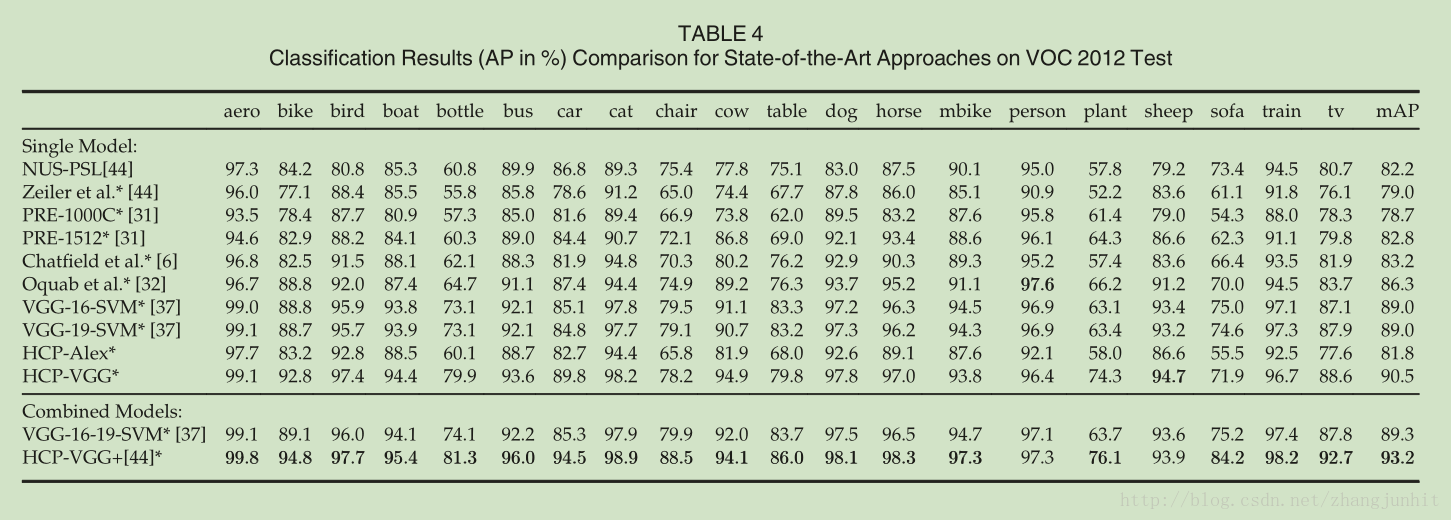
相關推薦
多標籤影象分類--HCP: A Flexible CNN Framework for Multi-Label Image Classification
HCP: A Flexible CNN Framework for Multi-Label Image Classification PAMI 2016 本文提出了一個 CNN 網路 HCP 不需要真值訓練資料的情況下可以完成對多標籤影象分類問題。 單標籤
Caffe實現多標籤影象分類(1)——基於Python介面實現多標籤影象分類(VOC2012)
1.前言 Caffe可以通過LMDB或LevelDB資料格式實現影象資料及標籤的輸入,不過這隻限於單標籤影象資料的輸入。由於研究生期間所從事的研究是影象標註領域,在進行影象標註時,每幅影象都是多標籤的,因此在使用Caffe進行遷移學習時需要實現多標籤影象資料
騰訊AI Lab開源業內最大規模多標籤影象資料集(附下載地址)
參加 2018 AI開發者大會,請點選 ↑↑↑ 今日(10 月 18 日),騰訊AI Lab宣佈正式開源“Tencent ML-Images”專案。該專案由多標籤影象資料集 ML-Images,以及業內目前同類深度學習模型中精度最高的深度殘差網路 ResNet-101 構成。
Hash-retrieval復現之旅(1)------------------------------malti-label 多標籤影象的檢索程式碼復現
本文參考論文是arxiv2015的關於多標籤檢索的論文Deep Semantic Ranking Based Hashing for Multi-Label Image Retrieval,作者 Fang Zhao Yongzhen Huang Li
深度學習與文字分類總結第二篇--大規模多標籤文字分類
上一篇部落格中我們已經總結了文字分類中常用的深度學習模型,因為知乎的本次競賽是多標籤的文字分類任務,這也是我第一次接觸多標籤分類,所以想單獨寫一篇部落格來記錄這方面的相關知識。 在這裡首先列出幾篇參考的文章: 基於神經網路的多標籤分類可以追溯到周志華在20
NLP大賽冠軍總結:300萬知乎多標籤文字分類任務(附深度學習原始碼)
1. 比賽介紹 這是一個文字多分類的問題:目標是“參賽者根據知乎給出的問題及話題標籤的繫結關係的訓練資料,訓練出對未標註資料自動標註的模型”。通俗點講就是:當用戶在知乎上提問題時,程式要能夠根據問題的內容自動為其新增話題標籤。一個問題可能對應著多個話題標籤,如下圖所示。
使用caffe fine-tune一個單標籤影象分類模型
進行網路模型的訓練與測試(基於預訓練的模型)。 準備資料 這步主要是自己先把資料集劃分好,比如訓練集、驗證集和測試集各多少張,並把相應的圖片放到對應的資料夾下。一些針對影象本身的預處理,比如要進行資料增強,就可以在此步實現(資料增強在第2步資料轉換時也可以做,但是沒有自己手動的資料增強靈活)。除此之外
tinymind多標籤圖片分類大賽總結
tinymind是csdn下的一個人工智慧學習交流的平臺,其中也有機器學習的比賽,但由於比較新,所以參與的人並不很多,就像這次參加的多標籤圖片分類大賽,總共參與的隊伍數在300左右,很適合用於練手。 先
基於深度學習的大規模多標籤文字分類任務總結
自然語言處理方向的論文模擬到現在,有以下想法: 1. 很多模型都為啟發式演算法,從直觀上很好理解,但是對於大多數人來說,就是一個黑盒,70%時間都在處理資料和調參。 2. 在資料競賽中,常用的模型就是CNN和RNN,先調出baseline,然後再進行模型融合
2017知乎看山杯總結(多標籤文字分類)
任務描述:參賽者需要根據知乎給出的問題及話題標籤的繫結關係的訓練資料,訓練出對未標註資料自動標註的模型。 標註資料中包含 300 萬個問題,每個問題有 1 個或多個標籤,共計1999 個標籤。每個標籤對應知乎上的一個「話題」,話題之間存在父子關係,並通
基於BOW模型的影象分類Bag Of Visual Words model for image classification
I wanted to play around with Bag Of Words for visual classification, so I coded a Matlab implementation that uses VLFEAT for the features and clustering.
A Learning Based Framework for Depth Ordering
這是賈兆寅在2012年cvpr發表的一篇計算深度的文章, 去想他要程式碼不給, 所以只好自己寫了。 文章用了深度的一些features, 其中包括hoiem在07年論文中提到的一些features。 還有就是採用了svm學習的方法進行計算。 我把論文實現後算了一下結果,
【轉載】細粒度影象識別Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classification
細粒度影象識別Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classification(OPADDL) 論文筆記 原文:"Object-Part Attention Model for Fin
2.CNN圖片多標籤分類(基於TensorFlow實現驗證碼識別OCR)
上一篇實現了圖片CNN單標籤分類(貓狗圖片分類任務) 地址:juejin.im/post/5c0739… 預告:下一篇用LSTM+CTC實現不定長文字的OCR,本質上是一種不固定標籤個數的多標籤分類問題 本文所用到的10w驗證碼資料集百度網盤下載地址(也可使用下文程式碼自行生成): pan.baidu
Keras 多工實現,Multi Loss #########Keras Xception Multi loss 細粒度影象分類
這裡只摘取關鍵程式碼: # create the base pre-trained model input_tensor = Input(shape=(299, 299, 3)) base_model = Xception(include_top=True, weights='imagenet'
多標籤分類的結果評估---macro-average和micro-average介紹
一,多分類的混淆矩陣 多分類混淆矩陣是二分類混淆矩陣的擴充套件 祭出程式碼,畫線的那兩行就是關鍵啦: 二,檢視多分類的評估報告 祭出程式碼,使用了classicfication_report() 三,巨集平均與微平均 公式是神看的,我是學弱...直接看例子,沒有複雜的公
基於keras實現多標籤分類(multi-label classification)
首先討論多標籤分類資料集(以及如何快速構建自己的資料集)。 之後簡要討論SmallerVGGNet,我們將實現的Keras神經網路架構,並用於多標籤分類。 然後我們將實施SmallerVGGNet並使用我們的多標籤分類資料集對其進行訓練。 最後,我們將通過在示例影象上測試我
keras+CNN影象分類
我們的深度學習資料集包括1,191張口袋妖怪影象,(存在於口袋妖怪世界中的動物般的生物,流行的電視節目,視訊遊戲和交易卡系列)。 我們的目標是使用Keras和深度學習訓練卷積神經網路,以識別和分類這些神奇寶貝。 我們將認識到的口袋妖怪包括: Bulbasaur(234影象) Charma
實戰keras——用CNN實現cifar10影象分類
原文:https://blog.csdn.net/zzulp/article/details/76358694 import keras from keras.datasets import cifar10 from keras.models import Sequenti
多標籤分類(multi-label classification)
意義 網路新聞往往含有豐富的語義,一篇文章既可以屬於“經濟”也可以屬於“文化”。給網路新聞打多標籤可以更好地反應文章的真實意義,方便日後的分類和使用。 難點 (1)類標數量不確定,有些樣本可能只有一個類標,有些樣本的類標可能高達幾十甚至上百個。