
scipy數值優化與引數估計
引言
優化是一門大學問,這裡不講數學原理,我假設你還記得一點高數的知識,並且看得懂python程式碼。
關於求解方程的引數,這個在資料探勘或問題研究中經常碰到,比如下面的迴歸方程式,是挖掘演算法中最簡單最常用的了,那麼怎麼求解方程中的各個引數呢?
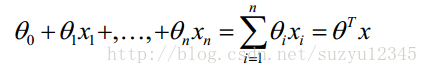
當然,對於常見的挖掘演算法,甚至是複雜的深度學習,在sklearn和tensorflow等工具已經很好解決怎麼求解引數的問題,只需要調介面就好了。
那麼我們再看下面的bass方程式,同樣很簡單,但是沒有現成可用的程式可用,怎麼求解最優的引數呢?

圖片不是很清晰,只是為了說明問題。就是如果你有了明確的數學表示式,也有了一些測量資料,怎麼求解裡面的引數,才是這批文章要說的。
關於求導
其實關於引數求解的方法,是有很標準的方法的,比如最大似然估計,最小二乘法等。這些需要你還記得高數的知識。求導,梯度,然後梯度下降,多麼標準的方法啊,這種思想和方法在大部分的資料探勘演算法裡面都是這麼幹的,而且經過精巧而優美的變化,大部分問題總能將目標函式最小化轉成凸優化問題。
但是在學習中總不是那麼順利的,除了一些常見的演算法可以調程式外,很多研究公式還是要自己想辦法求解方程引數,特別是很多論文中,作者為了顯示自己研究的獨到之處,總是對標準方程加以改造,加入正則項,修正項等等,比如上面的bass方程式,這就尷尬了。
當然,這也可以通過極大似然估計,或者最小二乘的方法,但是不是我們想要的,為什麼,因為我們不是搞研究的啊,在工作中,基本就是拿來就用,不行就扔。
scipy數值優化
其實使用scipy進行數值優化,就是黑盒優化, 我們不依賴於我們優化的函式的算術表示式。注意這個表示式通常可以用於高效的、非黑盒優化。
scipy中的optimize子包中提供了常用的最優化演算法函式實現。我們可以直接呼叫這些函式完成我們的優化問題。optimize中函式最典型的特點就是能夠從函式名稱上看出是使用了什麼演算法。
下面optimize包中函式的概覽:
1.非線性最優化
fmin– 簡單Nelder-Mead演算法fmin_powell– 改進型Powell法fmin_bfgs– 擬Newton法fmin_cg– 非線性共軛梯度法fmin_ncg– 線性搜尋Newton共軛梯度法leastsq– 最小二乘
2.有約束的多元函式問題
fmin_l_bfgs_b—使用L-BFGS-B演算法fmin_tnc—梯度資訊fmin_cobyla—線性逼近fmin_slsqp—序列最小二乘法nnls—解|| Ax - b ||_2 for x>=0
3.全域性優化
anneal—模擬退火演算法brute–強力法
4.標量函式
fminboundbrentgoldenbracket
5.擬合
curve_fit– 使用非線性最小二乘法擬合
6.標量函式求根
brentq—classic Brent (1973)brenth—A variation on the classic Brent(1980)ridder—Ridder是提出這個演算法的人名bisect—二分法newton—牛頓法fixed_point
7.多維函式求根
fsolve—通用broyden1—Broyden’s first Jacobian approximation.broyden2—Broyden’s second Jacobian approximationnewton_krylov—Krylov approximation for inverse Jacobiananderson—extended Anderson mixingexcitingmixing—tuned diagonal Jacobian approximationlinearmixing—scalar Jacobian approximationdiagbroyden—diagonal Broyden Jacobian approximation
8.實用函式
line_search—找到滿足強Wolfe的alpha值check_grad—通過和前向有限差分逼近比較檢查梯度函式的正確性
參考網上資料,以及從scipy的文件找到的,還有一些沒有放上去,這麼多,我也沒完全搞明白,這裡主要講leastsq和fmin_l_bfgs_b,但是它們的用法基本是一樣的。
注意:
1.需要特別說明一點的是,上面的方法,既可以用來求函式的極值,也可以反過來看問題,將引數當做輸入變數X,從而在觀測樣本上計算極值,就是我們要求的引數值。
2.我們下面只講怎麼求解引數,關於用scipy.optimize 求極值的例子很多,官網文件的例子也很好理解,而求解引數的反而沒多少,這促使我要把最近的一些學習成果好好整理一下,算是做筆記吧。
3.要時刻記住,當你使用scipy.optimize 的時候,你是使用黑盒優化,你不知道你的目標函式是不是凸函式,也不知道它計算的數值梯度和解析梯度相差有多大,甚至,當你猜的初值不合理,結果也是有問題的。
4.無論如何,你都需要給出誤差計算方法,也就是說,你需要知道x計算y_hat,通過y_hat和y計算最後的誤差residuals。
引數求解步驟
- 首先是將資料整理成
輸入X−>輸出y
的一一對應關係,這一步看似簡單,其實也是最難的,特別是在時間序列這樣的函式式裡面, - 定義需要最小化的目標函式
residuals.fun(X) - 最後是呼叫
leastsq(),fmin_l_bfgs_b()或其他最小化目標函式
min.residuals.func(X)
最小二乘 leastsq
最小二乘的思想很好理解,就是找到一組引數,使得函式的擬合值和真實值之間的均方誤差最小。
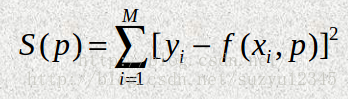
在學習多元迴歸和邏輯迴歸的時候,引數求解,就是通過推誤差進行梯度推導,最後進行隨機梯度下降來計算的。
我們這裡沒那麼複雜,直接使用 scipy.optimize.leastsq 對誤差函式進行最小化即可求出引數值。
# 使用 leastsq 函式求引數,擬合的函式形式是:
# y=A*sin(2*pi*k*x + theta)
#
import numpy as np
from scipy.optimize import leastsq
def func(x, p):
""" 資料擬合所用的函式: A*sin(2*pi*k*x + theta) """
A, k, theta = p
return A*np.sin(2*np.pi*k*x+theta)
def residuals(p, y, x):
""" 實驗資料x, y和擬合函式之間的差,p為擬合需要找到的係數 """
return y - func(x, p)
# 生成輸入資料X和輸出輸出Y
x = np.linspace(-2*np.pi, 0, 100) # x
A, k, theta = 10, 0.34, np.pi/6 # 真實資料的函式引數
y0 = func(x, [A, k, theta]) # 真實資料
y1 = y0 + 2 * np.random.randn(len(x)) # 加入噪聲之後的實驗資料
# 需要求解的引數的初值,注意引數的順序,要和func保持一致
p0 = [7, 0.2, 0]
# 呼叫leastsq進行資料擬合, residuals為計算誤差的函式
# p0為擬合引數的初始值
# args為需要擬合的實驗資料,也就是,residuals誤差函式
# 除了P之外的其他引數都打包到args中
plsq = leastsq(residuals, p0, args=(y1, x))
# 除了初始值之外,還呼叫了args引數,用於指定residuals中使用到的其他引數
# (直線擬合時直接使用了X,Y的全域性變數),同樣也返回一個元組,第一個元素為擬合後的引數陣列;
# 這裡將 (y1, x)傳遞給args引數。Leastsq()會將這兩個額外的引數傳遞給residuals()。
# 因此residuals()有三個引數,p是正弦函式的引數,y和x是表示實驗資料的陣列。
# 擬合的引數
print("擬合引數", plsq[0])
# 擬合引數 [ 10.6359371 0.3397994 0.50520845]
# 發現跟實際值有差距,但是從下面的擬合圖形來看還不錯,說明結果還是 堪用 的。
# 順便畫張圖看看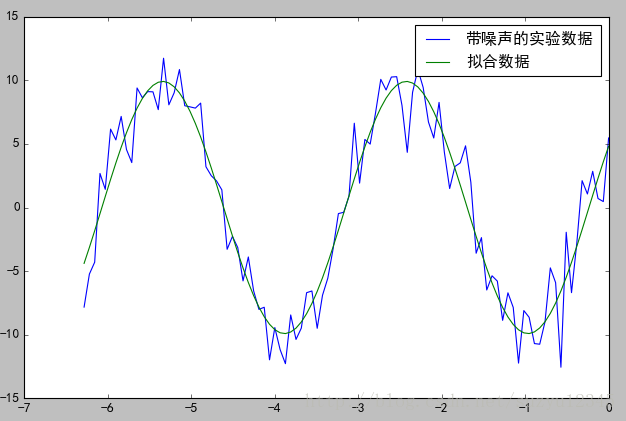
l-bfgs-b
bfgs演算法很厲害啊, BFGS演算法是使用較多的一種擬牛頓方法,是由Broyden,Fletcher,Goldfarb,Shanno四個人分別提出的,故稱為BFGS校正,BFGS演算法被認為是數值效果最好的擬牛頓法,並且具有全域性收斂性和超線性收斂速度。
廢話不多說,這裡也不講原理了,上例子吧。
# Non-Linear Least-Squares Fitting
在查 scipy.optimize資料的時候,發現了 lmfit,其官網資料也說了,這個模組是對scipy.optimize的封裝,使其更加好用。lmfit的資料更加齊全,也有很多例子,在看lmfit的時候,對scipy.optimize的理解更加深刻了。
如果只是簡單地說,lmfit對scipy.optimize的待求解引數進行了字典方式的包裝,即使在外面改了東西,裡面的計算邏輯不需要修改,或者將改動降低到最小。
具體的使用方法,和scipy.optimize也很相似,或者說基本一致吧。
下面是一個簡單的例子:
from lmfit import minimize, Parameters
def residual(params, x, data):
# 誤差函式
amp = params['amp']
pshift = params['phase']
freq = params['frequency']
decay = params['decay']
model = amp * sin(x * freq + pshift) * exp(-x*x*decay)
return (data-model)
# 定義待求解的引數,以及初值,引數的數值範圍
params = Parameters()
params.add('amp', value=10, vary=False)
params.add('decay', value=0.007, min=0.0)
params.add('phase', value=0.2)
params.add('frequency', value=3.0, max=10)
# 生成輸入x和輸出y
x = np.linspace(0, 15, 301)
data = (5. * np.sin(2 * x - 0.1) * np.exp(-x*x*0.025) +
np.random.normal(size=len(x), scale=0.2) )
# 求解引數
out = minimize(residual, params, args=(x, data), method ='leastsq')
out.params
Parameters([('amp', <Parameter 'amp', value=10 (fixed), bounds=[-inf:inf]>),
('decay', <Parameter 'decay', value=0.09861 +/- 0.00626, bounds=[0.0:inf]>),
('phase', <Parameter 'phase', value=-0.27096 +/- 0.0399, bounds=[-inf:inf]>),
('frequency', <Parameter 'frequency', value=2.06691 +/- 0.0262, bounds=[-inf:10]>)])注意:
lmfit 要求除了leastsq外,其他的優化方法均要求 residual函式返回的是list或者array,而不知一個值,即要求返回的不是 residual返回的是 (data-model)。
lmfit支援的優化方法
由於lmfit是對scipy.optimize的包裝,所以scipy支援的優化方法lmfit中也支援,通過method引數指定。
lmfit支援的優化方法如下:
method (str, optional) –
Name of the fitting method to use. Valid values are:
leastsq: Levenberg-Marquardt (default)least_squares: Least-Squares minimization, using Trust Region Reflective method by defaultdifferential_evolution: differential evolutionbrute: brute force methodnelder: Nelder-Meadlbfgsb: L-BFGS-Bpowell: Powellcg: Conjugate-Gradientnewton: Newton-Congugate-Gradientcobyla: Cobylatnc: Truncate Newtontrust-ncg: Trust Newton-Congugate-Gradientdogleg: Doglegslsqp: Sequential Linear Squares Programming
In most cases, these methods wrap and use the method of the same name from scipy.optimize, or use scipy.optimize.minimize with the same method argument.
Thus `leastsq‘ will use scipy.optimize.leastsq, while ‘powell‘ will use scipy.optimize.minimizer(…., method=’powell’)
For more details on the fitting methods please refer to the SciPy docs.
後話
優化是一門大學問,以後慢慢完善吧。