
HIve 和 MySQL 的區別 轉載部落格
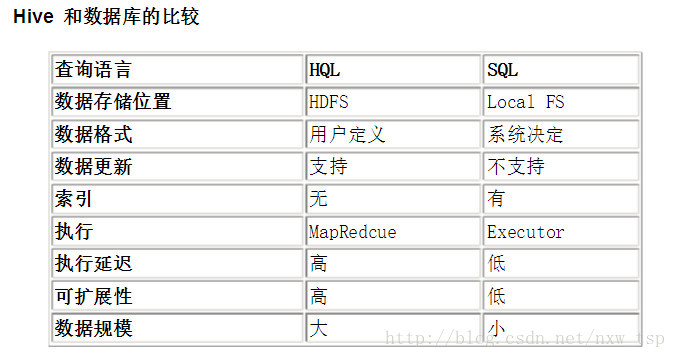
注: Local FS :Local File System ,本地檔案系統
資料更新:這一行 HQL 不支援,SQL 支援
資料更新:這一行 HQL 不支援,SQL 支援
資料更新:這一行 HQL 不支援,SQL 支援
-
查詢語言。由於 SQL 被廣泛的應用在資料倉庫中,因此,專門針對 Hive 的特性設計了類 SQL 的查詢語言 HQL。熟悉 SQL 開發的開發者可以很方便的使用 Hive 進行開發。
-
資料儲存位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的資料都是儲存在 HDFS 中的。而資料庫 則可以將資料儲存在本地檔案系統中。
-
資料格式。Hive 中沒有定義專門的資料格式,資料格式可以由使用者指定,使用者定義資料格式需要指定三 個屬性:列分隔符(通常為空格、”\t”、”\x001″)、行分隔符(”\n”)以及讀取檔案資料的方法(Hive 中預設有三個檔案格式 TextFile,SequenceFile 以及 RCFile)。由於在載入資料的過程中,不需要從使用者資料格式到 Hive 定義的資料格式的轉換,因此,Hive 在載入的過程中不會對資料本身進行任何修改,而只是將資料內容複製或者移動到相應的 HDFS 目錄中。而在資料庫中,不同的資料庫有不同的儲存引擎,定義了自己的資料格式。所有資料都會按照一定的組織儲存,因此,資料庫載入資料的過程會比較耗時。
-
資料更新。由於 Hive 是針對資料倉庫應用設計的,而資料倉庫的內容是讀多寫少的。因此,Hive 中不 支援對資料的改寫和新增,所有的資料都是在載入的時候中確定好的。而資料庫中的資料通常是需要經常進行修改的,因此可以使用 INSERT INTO … VALUES 新增資料,使用 UPDATE … SET 修改資料。
-
索引。之前已經說過,Hive 在載入資料的過程中不會對資料進行任何處理,甚至不會對資料進行掃描, 因此也沒有對資料中的某些 Key 建立索引。Hive 要訪問資料中滿足條件的特定值時,需要暴力掃描整個資料,因此訪問延遲較高。 由於 MapReduce 的引入, Hive 可以並行訪問資料,因此即使沒有索引,對於大資料量的訪問,Hive 仍然可以體現出優勢。資料庫中,通常會針對一個或者幾個列建立索引,因此對於少量的特定條件的資料的訪問,資料庫可以有很高的效率,較低的延遲。由於資料的訪問延遲較高,決定了 Hive 不適合線上資料查詢。
-
執行。Hive 中大多數查詢的執行是通過 Hadoop 提供的 MapReduce 來實現的(類似 select * from tbl 的查詢不需要 MapReduce)。而資料庫通常有自己的執行引擎。
-
執行延遲。之前提到,Hive 在查詢資料的時候,由於沒有索引,需要掃描整個表,因此延遲較高。另外 一個導致 Hive 執行延遲高的因素是 MapReduce 框架。由於 MapReduce 本身具有較高的延遲,因此在利用 MapReduce 執行 Hive 查詢時,也會有較高的延遲。相對的,資料庫的執行延遲較低。當然,這個低是有條件的,即資料規模較小,當資料規模大到超過資料庫的處理能力的時候,Hive 的平行計算顯然能體現出優勢。
-
可擴充套件性。由於 Hive 是建立在 Hadoop 之上的,因此 Hive 的可擴充套件性是和 Hadoop 的可擴充套件性是 一致的(世界上最大的 Hadoop 叢集在 Yahoo!,2009年的規模在 4000 臺節點左右)。而資料庫由於 ACID 語義的嚴格限制,擴充套件行非常有限。目前最先進的並行資料庫 Oracle 在理論上的擴充套件能力也只有 100 臺左右。
-
資料規模。由於 Hive 建立在叢集上並可以利用 MapReduce 進行平行計算,因此可以支援很大規模的 資料;對應的,資料庫可以支援的資料規模較小。