
ES建立索引的過程
ES中建立索引的詳細分析
總覽
ES 建立索引最終都會呼叫 org/elasticsearch/index/engine/InternalEngine.java 中下面的方法:
public IndexResult index(Index index) throws IOException {注意這裡的index中包含有要寫入的doc,該方法的執行流程圖如下:
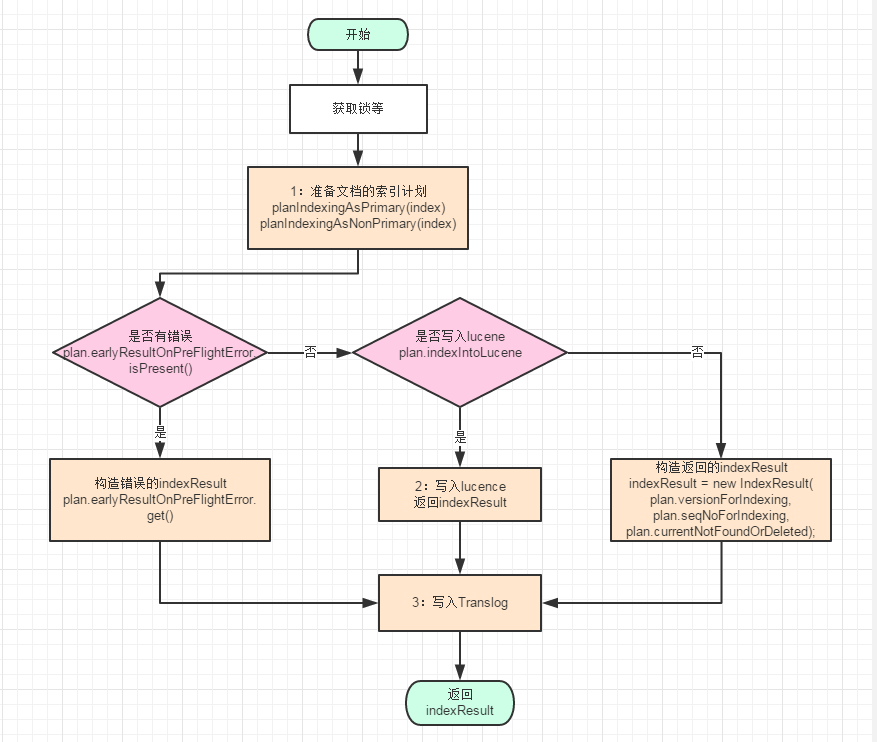
注意:結合上邊的流程圖來看程式碼,先對整體有個全域性的認識,再深入到各個部分深入分析。切勿在對整體不甚瞭解的情況下,深入到程式碼細節,切記,切記。
準備文件的索引計劃
準備索引計劃根據是否為主節點分別呼叫:planIndexingAsPrimary和planIndexingAsNonPrimary函式,接下來我們看下planIndexingAsPrimary的邏輯(位於org/elasticsearch/index/engine/InternalEngine.java
private IndexingStrategy planIndexingAsPrimary(Index index) throws IOException {這個方法最終返回一個4個IndexingStrategy(索引的策略)中的一個,四個索引的策略分別如下:
- optimizedAppendOnly
- skipDueToVersionConflict
- processNormally
- overrideExistingAsIfNotThere
不同的策略對應不同的處理邏輯,前面三個是常用的,流程圖如下:
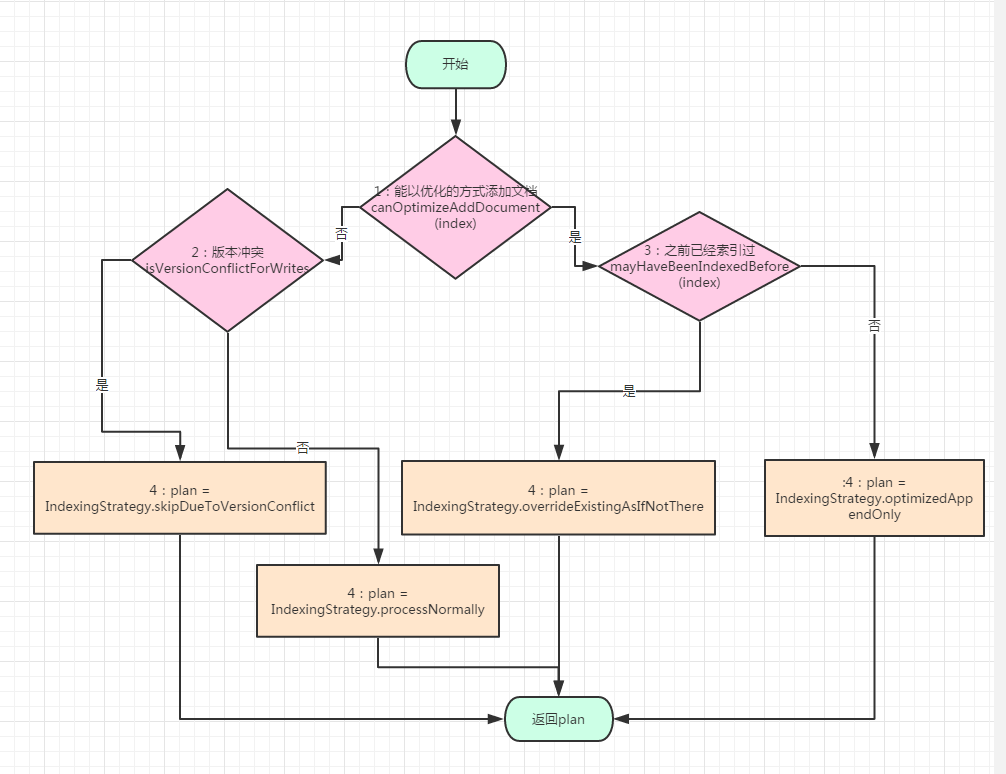
對於1的說明:canOptimizeAddDocument函式中只判斷autoGeneratedIdTimestamp變數是否不等於-1;如果不等於-1意味著這個這個文件有一個自動生成的id,就意味著這個文件能以optimized的方式加入到索引中。
對於2的說明:為了判斷版本是否衝突,首先會根據文件id從記憶體中的map中獲取versionValue,獲取不到則從磁碟中獲取,如果還獲取不到說明之前沒有索引過這個文件,則不存在版本衝突的問題。獲取到versionValue後會和index.version()進行比較,看是否存在版本衝突。index.version()是在傳送索引命令時指定的引數。
對於3的說明:maxUnsafeAutoIdTimestamp用於記錄之前處理的文件的autoGeneratedIdTimestamp的最大值,如果不是retry,且autoGeneratedIdTimestamp小於maxUnsafeAutoIdTimestamp,說明之前已經索引過,反之則沒建立過索引【這兒存在一個問題,分散式情況下,如何保證到達的順序(小的autoGereratedIdTimestamp先處理),如果這個id是在到達本機之後才生成的就不存在這個問題(如果是一個程序生成才不存在這個問題,多個程序還是存在這個問題)
對於4的說明:這四種策略最終都會建立一個IndexingStrategy物件。
final boolean currentNotFoundOrDeleted; 這個文件不存在or已經被刪除(versionValue.isDelete())
final boolean useLuceneUpdateDocument; 使用lucene更新文件
final long seqNoForIndexing; lucene中從0開始自增的文件編號
final long versionForIndexing; 版本號
final boolean indexIntoLucene; 與useLuceneUpdateDocument相對,這個是直接寫入而非更新
final Optional<IndexResult> earlyResultOnPreFlightError; 之前的錯誤資訊至此,總覽圖中的1準備文件的索引計劃就分析完成了。
索引寫入lucene
接著開始分析總覽中的 ——2:寫入lucene返回indexResult。
ing
參考文件:
https://segmentfault.com/a/1190000011272749