
Spark 偽分散式 & 全分散式 安裝指南
http://my.oschina.net/leejun2005/blog/394928
0、前言
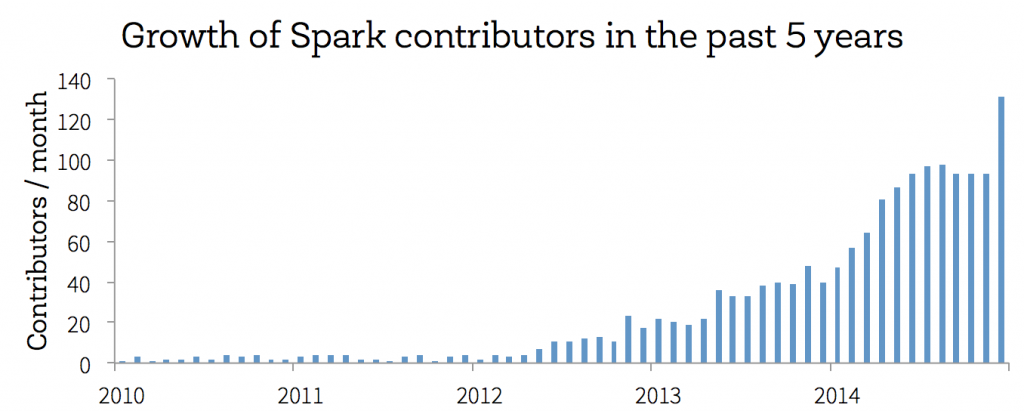
3月31日是 Spark 五週年紀念日,從第一個公開發布的版本開始,Spark走過了不平凡的5年:從剛開始的默默無聞,到13年的鵲起,14年的大爆發。Spark核心之上有分散式的機器學習,SQL,streaming和圖計算庫。
4月1日 spark 官方正式宣佈 對Spark重構,更好支援手機等移動終端。Databricks創始人之一hashjoin透漏了相關的重構方法:利用Scala.js專案把Spark程式碼編譯成JavaScript,然後利用Safari / Chrome在手機上執行。一個程式碼可以支援Android / iOS。但是考慮到效能關係,可能需要重寫底層的網路模組來支援zero-copy。(確定是否愚人節玩笑呢 :) )
ok,言歸正傳。Spark目前支援多種分散式部署方式:一、Standalone Deploy Mode;二、Amazon EC2 ;三、Apache Mesos;四、Hadoop YARN。第一種方式是單獨部署(可單機或叢集),不需要有依賴的資源管理器,其它三種都需要將spark部署到對應的資源管理器上。

除了部署的多種方式之外,較新版本的Spark支援多種hadoop平臺,比如從0.8.1版本開始分別支援Hadoop 1 (HDP1, CDH3)、CDH4、Hadoop 2 (HDP2, CDH5)。目前Cloudera公司的CDH5在用CM安裝時,可直接選擇Spark服務進行安裝。
目前Spark最新版本是1.3.0,本文就以1.3.0版本,來看看如何實現Spark 單機偽分散式以及分散式叢集的安裝。
1、安裝環境
Spark 1.3.0需要JDK1.6或更高版本,我們這裡採用jdk 1.6.0_32;
Spark 1.3.0需要Scala 2.10或更高版本,我們這裡採用scala 2.11.6;
記得配置下 scala 環境變數:
?| 1 2 3 |
vim /etc/profile
export SCALA_HOME=/home/hadoop/software/scala-2.11.4
export PATH=$SCALA_HOME/bin:$PATH
|
2、偽分散式安裝
2.1 解壓縮、配置環境變數即可
直接編輯 /etc/profile 或者 ~/.bashrc 檔案,然後加入如下環境變數:
?| 1 2 3 4 5 6 7 8 9 10 |
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SCALA_HOME=/home/hadoop/software/scala-2.11.4
export JAVA_HOME=/home/hadoop/software/jdk1.7.0_67
export SPARK_MASTER=localhost
export SPARK_LOCAL_IP=localhost
export HADOOP_HOME=/home/hadoop/software/hadoop-2.5.2
export SPARK_HOME=/home/hadoop/software/spark-1.2.0-bin-hadoop2.4
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin
|
2.2 讓配置生效
source /etc/profile
source ~/.bashrc
2.3 啟動spark
進入到SPARK_HOME/sbin下,執行:
start-all.sh
[root@centos local]# jps
7953 DataNode
8354 NodeManager
8248 ResourceManager
8104 SecondaryNameNode
10396 Jps
7836 NameNode
7613 Worker
7485 Master
有一個Master跟Worker程序 說明啟動成功
可以通過http://localhost:8080/檢視spark叢集狀況
2.4 兩種模式執行Spark例子程式
2.4.1 Spark-shell
此模式用於interactive programming,具體使用方法如下(先進入bin資料夾)
| 1 2 3 4 5 6 7 8 9 10 |
./spark-shell
...
scala> val days = List("Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday")
days: List[String] = List(Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday)
scala> val daysRDD =sc.parallelize(days)
daysRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:14
scala>daysRDD.count()
scala>res0:Long =7
|
2.4.2 執行指令碼
執行Spark自帶的example中的SparkPi,在
這裡要注意,以下兩種寫法都有問題
./bin/run-example org.apache.spark.examples.SparkPi spark://localhost:7077
./bin/run-example org.apache.spark.examples.SparkPi local[3]
local表示本地,[3]表示3個執行緒跑
這樣就可以:
| 1 2 3 4 5 6 |
./bin/run-example org.apache.spark.examples.SparkPi 2 spark://192.168.0.120:7077
15/03/17 19:23:56 INFO scheduler.DAGScheduler: Completed ResultTask(0, 0)
15/03/17 19:23:56 INFO scheduler.DAGScheduler: Stage 0 (reduce at SparkPi.scala:35) finished in 0.416 s
15/03/17 19:23:56 INFO spark.SparkContext: Job finished: reduce at SparkPi.scala:35, took 0.501835986 s
Pi is roughly 3.14086
|
3、全分散式叢集安裝
其實叢集安裝方式也很簡單。
3.1 新增環境變數
?| 1 2 3 4 5 6 7 8 9 10 11 |
cd spark-1.3.0
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vi ./conf/spark-env.sh 新增以下內容:
export SCALA_HOME=/usr/lib/scala-2.10.3
export JAVA_HOME=/usr/java/jdk1.6.0_31
export SPARK_MASTER_IP=10.32.21.165
export SPARK_WORKER_INSTANCES=3
export SPARK_MASTER_PORT=8070
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_PORT=8092
export SPARK_WORKER_MEMORY=5000m
|
SPARK_MASTER_IP這個指的是master的IP地址;SPARK_MASTER_PORT這個是master埠;SPARK_MASTER_WEBUI_PORT這個是檢視叢集執行情況的WEB UI的埠號;SPARK_WORKER_PORT這是各個worker的埠號;SPARK_WORKER_MEMORY這個配置每個worker的執行記憶體。
-
vi ./conf/ slaves 每行一個worker的主機名(最好是用 host 對映 IP 成主機名),內容如下:
10.32.21.165
10.32.21.166
10.32.21.167
-
設定 SPARK_HOME 環境變數,並將 SPARK_HOME/bin 加入 PATH:
vi /etc/profile ,新增內容如下:
export SPARK_HOME=/usr/lib/spark-1.3.0
export PATH=$SPARK_HOME/bin:$PATH
然後將配置以及安裝檔案同步到各節點上,並讓環境變數生效。
3.2 啟動spark叢集
執行 ./sbin/start-all.sh
如果start-all方式無法正常啟動相關的程序,可以在$SPARK_HOME/logs目錄下檢視相關的錯誤資訊。其實,你還可以像Hadoop一樣單獨啟動相關的程序,在master節點上執行下面的命令:
在Master上執行:./sbin/start-master.sh
在Worker上執行:./sbin/start-slave.sh 3 spark://10.32.21.165:8070 --webui-port 8090
然後檢查程序是否啟動,執行jps命令,可以看到Worker程序或者Master程序。然後可以在WEB UI上檢視http://masterSpark:8090/可以看到所有的work 節點,以及他們的 CPU 個數和記憶體等資訊。
3.3 Local模式執行demo
比如:./bin/run-example SparkLR 2 local 或者 ./bin/run-example SparkPi 2 local
這兩個例子前者是計算線性迴歸,迭代計算;後者是計算圓周率
3.4 shell 互動式模式
./bin/spark-shell --master spark://10.32.21.165:8070 , 如果在conf/spark-env.sh中配置了MASTER(加上一句export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}),就可以直接用 ./bin/spark-shell啟動了。
spark-shell作為應用程式,是將提交作業給spark叢集,然後spark叢集分配到具體的worker來處理,worker在處理作業的時候會讀取本地檔案。
這個shell是修改了的scala shell,開啟一個這樣的shell會在WEB UI中可以看到一個正在執行的Application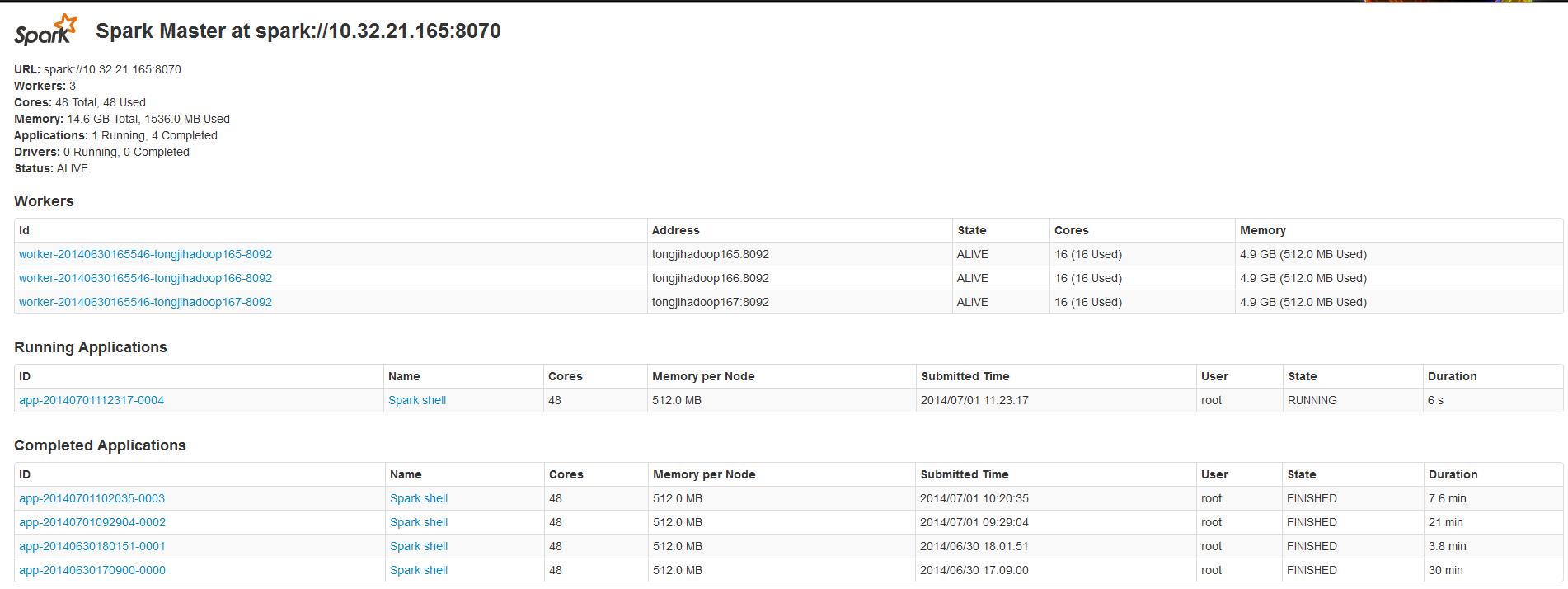
4、一個 scala & spark 例子
這個例子首先用 shell 生成 150,000,000 個隨機數,然後用 spark 統計每個隨機數頻率,以觀察隨機數是否均勻分佈。
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
getNum(){
c=1
while [[ $c -le 5000000 ]]
do
echo $(($RANDOM/500))
((c++))
done
}
for i in `seq 30`
do
getNum > ${i}.txt &
done
wait
echo "--------------- DONE -------------------"
cat [0-9]*.txt > num.txt
|
| 1 2 3 4 5 |
val file = sc.textFile("hdfs://10.9.17.100:8020/tmp/lj/num.txt")
val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
//count.collect().sortBy(_._2)
//count.sortBy(-_._2).saveAsTextFile("hdfs://10.9.17.100:8020/tmp/lj/spark/numCount")
count.sortBy(_._2).map(x => x._1 + "\t" + x._2).saveAsTextFile("hdfs://10.9.17.100:8020/tmp/lj/spark/numCount")
|
| 1 2 3 4 5 6 7 8 9 10 11 12 |
hadoop fs -cat hdfs://10.9.17.100:8020/tmp/lj/spark/numCount/p*|sort -k2n
65 1228200
55 2285778
59 2285906
7 2286190
24 2286344
60 2286554
37 2286573
22 2286719
...
13 2291903
43 2292001
|
5、題外話:擁抱 Scala
scala 如下幾個特性,或許值得你去學習這門新語言:
-
它最終也會編譯成Java VM程式碼,看起來象不象Java的殼程式?- 至少做為一個Java開發人員,你會鬆一口氣
-
它可以使用Java包和類 - 又放心了一點兒,這樣不用擔心你寫的包又得用另外一種語言重寫一遍
-
更簡潔的語法和更快的開發效率 - 比起java臃腫不堪的指令式語言,scala 函式式風格會讓你眼前一亮
-
spark 在 scala shell 基礎之上提供互動式 shell 環境讓 spark 除錯方便,比起笨重的 Java MR,一念天堂一念地獄。
6、Refer:
[1] 在Hadoop2.2基礎上安裝Spark(偽分散式)
[2] Spark一:Spark偽分散式安裝
[3] Spark-1.0.0 standalone分散式安裝教程