
《A Self-Attention Setentence Embedding》閱讀筆記及實踐
阿新 • • 發佈:2019-02-15
演算法原理
本文利用self-attention的方式去學習句子的embedding,表示為二維矩陣,而不是一個向量,矩陣中的每一行都表示句子中的不同部分。模型中使用了self-attention機制和一個特殊的regularization term。
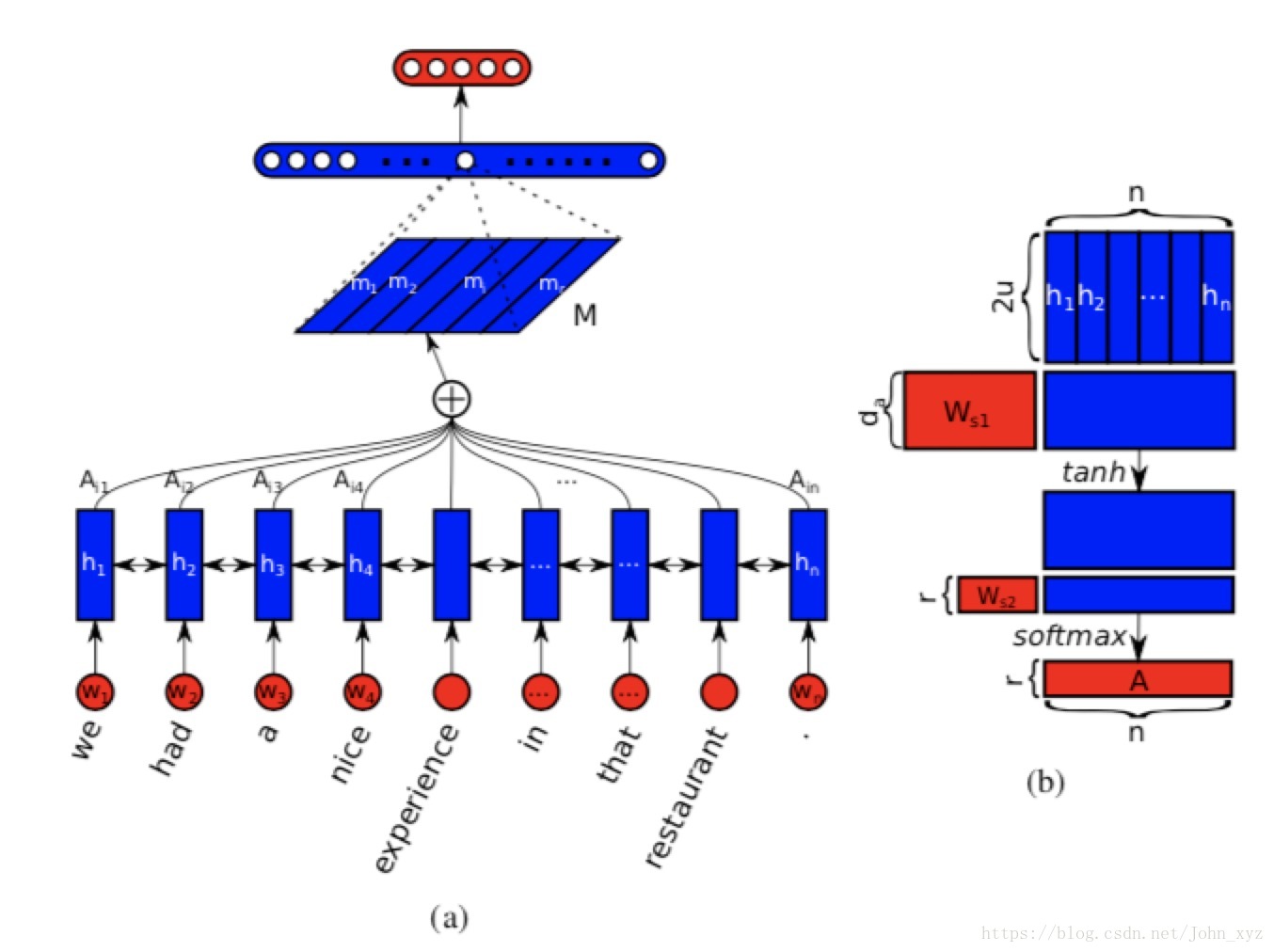
假設我們有一個句子, 包含個單詞
每個都是維的詞向量,所以是一個二維的矩陣,形狀為(n,d)。
上圖中的圖(a)是整個模型的流程,圖(b)是計算self-attention的過程。具體的。為了得到單詞之間的相關性,使用雙向LSTM處理這個句子:
將和級連在一起,得到隱狀態(hidden state)。讓每一個單向LSTM隱狀態單元數是, 那麼的形狀就是
我們的目的是為了將變長的句子編碼成固定長度的向量或者矩陣。可以使用中個LSTM隱向量的線性組合來表示。因此我們引入了self-attention機制。
所謂的self-attention,就是不同的詞有不同的重要性,這個重要性也是根據單詞和句子本身計算得到的。上圖中的圖(b)解釋了self-attention的計算過程. 將整個LSTM的隱狀態作為輸入,輸出權重向量
其中權重矩陣的形狀是,是長度為的一維向量。因為的形狀是,得到向量的最終長度為,因為函式可以保證最終和為1,最後將LSTM的隱狀態和計算得到的向量加權求和,就可以得到句子的表示

這種向量表示一般專注於句子的某個方面。為了實現attention的多樣性, 即我們想提取出個不同的attention,不同的attention方案可以學習到不同側重點的句子表示,可以用如下公式計算: