
大話目標檢測經典模型(RCNN、Fast RCNN、Faster RCNN)
目標檢測是深度學習的一個重要應用,就是在圖片中要將裡面的物體識別出來,並標出物體的位置,一般需要經過兩個步驟:
1、分類,識別物體是什麼
2、定位,找出物體在哪裡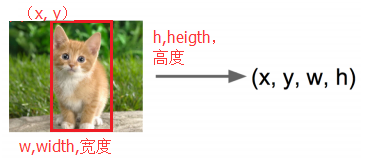
除了對單個物體進行檢測,還要能支援對多個物體進行檢測,如下圖所示: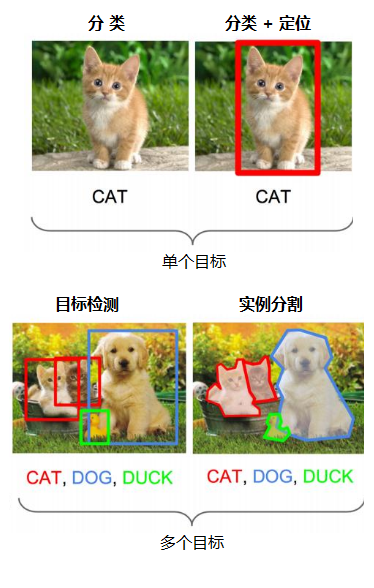
這個問題並不是那麼容易解決,由於物體的尺寸變化範圍很大、擺放角度多變、姿態不定,而且物體有很多種類別,可以在圖片中出現多種物體、出現在任意位置。因此,目標檢測是一個比較複雜的問題。
最直接的方法便是構建一個深度神經網路,將影象和標註位置作為樣本輸入,然後經過CNN網路,再通過一個分類頭(Classification head)的全連線層識別是什麼物體,通過一個迴歸頭(Regression head)的全連線層迴歸計算位置,如下圖所示: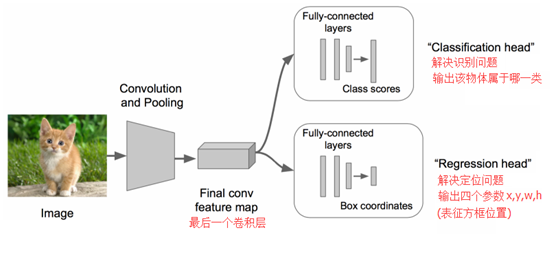
但“迴歸”不好做,計算量太大、收斂時間太長,應該想辦法轉為“分類”,這時容易想到套框的思路,即取不同大小的“框”,讓框出現在不同的位置,計算出這個框的得分,然後取得分最高的那個框作為預測結果,如下圖所示:

根據上面比較出來的得分高低,選擇了右下角的黑框作為目標位置的預測。
但問題是:框要取多大才合適?太小,物體識別不完整;太大,識別結果多了很多其它資訊。那怎麼辦?那就各種大小的框都取來計算吧。
如下圖所示(要識別一隻熊),用各種大小的框在圖片中進行反覆擷取,輸入到CNN中識別計算得分,最終確定出目標類別和位置。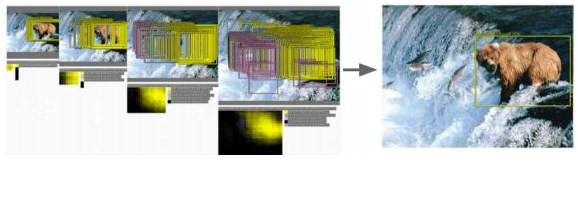
這種方法效率很低,實在太耗時了。那有沒有高效的目標檢測方法呢?
一、R-CNN 橫空出世
R-CNN(Region CNN,區域卷積神經網路)可以說是利用深度學習進行目標檢測的開山之作,作者Ross Girshick多次在PASCAL VOC的目標檢測競賽中折桂,2010年更是帶領團隊獲得了終身成就獎,如今就職於Facebook的人工智慧實驗室(FAIR)。
R-CNN演算法的流程如下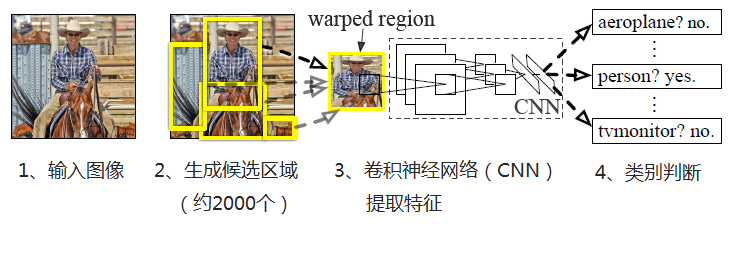
1、輸入影象
2、每張影象生成1K~2K個候選區域
3、對每個候選區域,使用深度網路提取特徵(AlextNet、VGG等CNN都可以)
4、將特徵送入每一類的SVM 分類器,判別是否屬於該類
5、使用迴歸器精細修正候選框位置
下面展開進行介紹
1、生成候選區域
使用Selective Search(選擇性搜尋)方法對一張影象生成約2000-3000個候選區域,基本思路如下:
(1)使用一種過分割手段,將影象分割成小區域
(2)檢視現有小區域,合併可能性最高的兩個區域,重複直到整張影象合併成一個區域位置。優先合併以下區域:
- 顏色(顏色直方圖)相近的
- 紋理(梯度直方圖)相近的
- 合併後總面積小的
- 合併後,總面積在其BBOX中所佔比例大的
在合併時須保證合併操作的尺度較為均勻,避免一個大區域陸續“吃掉”其它小區域,保證合併後形狀規則。
(3)輸出所有曾經存在過的區域,即所謂候選區域
2、特徵提取
使用深度網路提取特徵之前,首先把候選區域歸一化成同一尺寸227×227。
使用CNN模型進行訓練,例如AlexNet,一般會略作簡化,如下圖: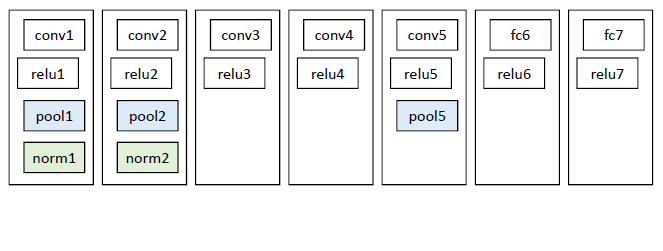
3、類別判斷
對每一類目標,使用一個線性SVM二類分類器進行判別。輸入為深度網路(如上圖的AlexNet)輸出的4096維特徵,輸出是否屬於此類。
4、位置精修
目標檢測的衡量標準是重疊面積:許多看似準確的檢測結果,往往因為候選框不夠準確,重疊面積很小,故需要一個位置精修步驟,對於每一個類,訓練一個線性迴歸模型去判定這個框是否框得完美,如下圖:
R-CNN將深度學習引入檢測領域後,一舉將PASCAL VOC上的檢測率從35.1%提升到53.7%。
二、Fast R-CNN大幅提速
繼2014年的R-CNN推出之後,Ross Girshick在2015年推出Fast R-CNN,構思精巧,流程更為緊湊,大幅提升了目標檢測的速度。
Fast R-CNN和R-CNN相比,訓練時間從84小時減少到9.5小時,測試時間從47秒減少到0.32秒,並且在PASCAL VOC 2007上測試的準確率相差無幾,約在66%-67%之間。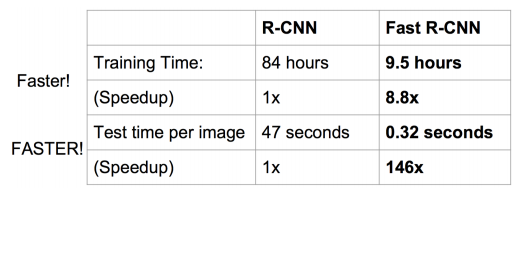
Fast R-CNN主要解決R-CNN的以下問題:
1、訓練、測試時速度慢
R-CNN的一張影象內候選框之間存在大量重疊,提取特徵操作冗餘。而Fast R-CNN將整張影象歸一化後直接送入深度網路,緊接著送入從這幅影象上提取出的候選區域。這些候選區域的前幾層特徵不需要再重複計算。
2、訓練所需空間大
R-CNN中獨立的分類器和迴歸器需要大量特徵作為訓練樣本。Fast R-CNN把類別判斷和位置精調統一用深度網路實現,不再需要額外儲存。
下面進行詳細介紹
1、在特徵提取階段,通過CNN(如AlexNet)中的conv、pooling、relu等操作都不需要固定大小尺寸的輸入,因此,在原始圖片上執行這些操作後,輸入圖片尺寸不同將會導致得到的feature map(特徵圖)尺寸也不同,這樣就不能直接接到一個全連線層進行分類。
在Fast R-CNN中,作者提出了一個叫做ROI Pooling的網路層,這個網路層可以把不同大小的輸入對映到一個固定尺度的特徵向量。ROI Pooling層將每個候選區域均勻分成M×N塊,對每塊進行max pooling。將特徵圖上大小不一的候選區域轉變為大小統一的資料,送入下一層。這樣雖然輸入的圖片尺寸不同,得到的feature map(特徵圖)尺寸也不同,但是可以加入這個神奇的ROI Pooling層,對每個region都提取一個固定維度的特徵表示,就可再通過正常的softmax進行型別識別。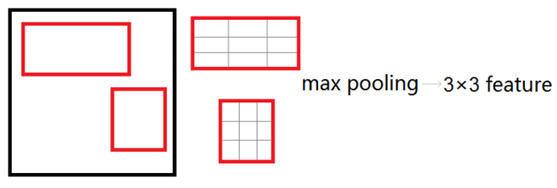
2、在分類迴歸階段,在R-CNN中,先生成候選框,然後再通過CNN提取特徵,之後再用SVM分類,最後再做迴歸得到具體位置(bbox regression)。而在Fast R-CNN中,作者巧妙的把最後的bbox regression也放進了神經網路內部,與區域分類合併成為了一個multi-task模型,如下圖所示: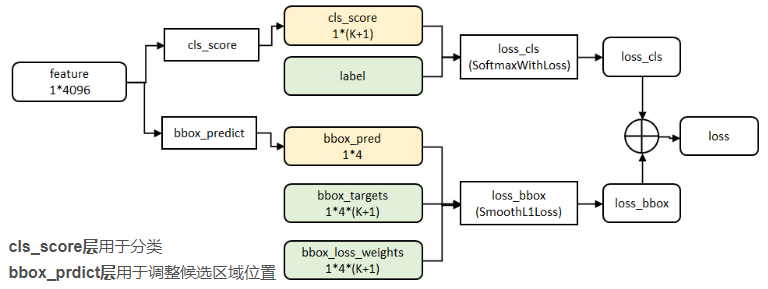
實驗表明,這兩個任務能夠共享卷積特徵,並且相互促進。
Fast R-CNN很重要的一個貢獻是成功地讓人們看到了Region Proposal+CNN(候選區域+卷積神經網路)這一框架實時檢測的希望,原來多類檢測真的可以在保證準確率的同時提升處理速度。
三、Faster R-CNN更快更強
繼2014年推出R-CNN,2015年推出Fast R-CNN之後,目標檢測界的領軍人物Ross Girshick團隊在2015年又推出一力作:Faster R-CNN,使簡單網路目標檢測速度達到17fps,在PASCAL VOC上準確率為59.9%,複雜網路達到5fps,準確率78.8%。
在Fast R-CNN還存在著瓶頸問題:Selective Search(選擇性搜尋)。要找出所有的候選框,這個也非常耗時。那我們有沒有一個更加高效的方法來求出這些候選框呢?
在Faster R-CNN中加入一個提取邊緣的神經網路,也就說找候選框的工作也交給神經網路來做了。這樣,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網路框架之內。如下圖所示: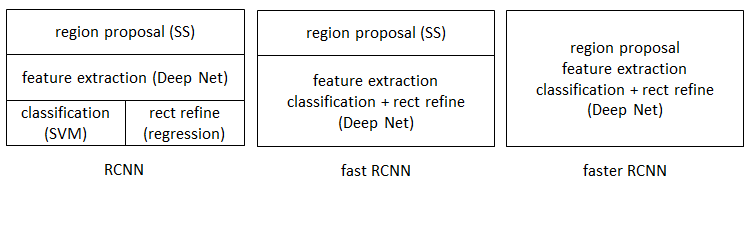
Faster R-CNN可以簡單地看成是“區域生成網路+Fast R-CNN”的模型,用區域生成網路(Region Proposal Network,簡稱RPN)來代替Fast R-CNN中的Selective Search(選擇性搜尋)方法。
如下圖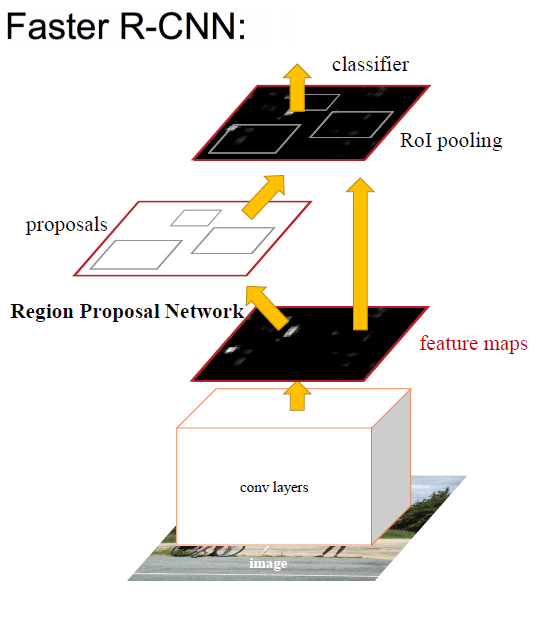
RPN如下圖: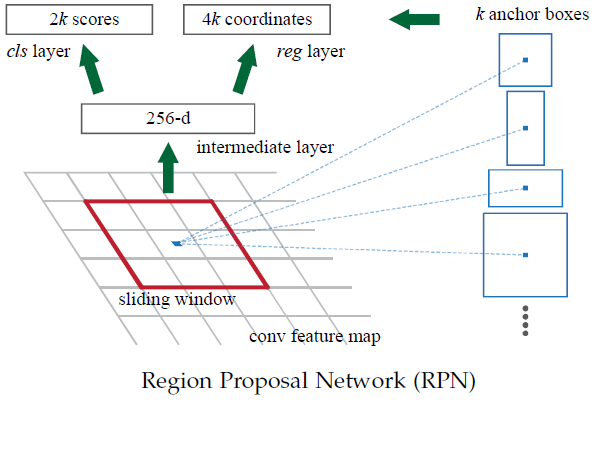
RPN的工作步驟如下:
- 在feature map(特徵圖)上滑動視窗
- 建一個神經網路用於物體分類+框位置的迴歸
- 滑動視窗的位置提供了物體的大體位置資訊
- 框的迴歸提供了框更精確的位置
Faster R-CNN設計了提取候選區域的網路RPN,代替了費時的Selective Search(選擇性搜尋),使得檢測速度大幅提升,下表對比了R-CNN、Fast R-CNN、Faster R-CNN的檢測速度:
總結
R-CNN、Fast R-CNN、Faster R-CNN一路走來,基於深度學習目標檢測的流程變得越來越精簡、精度越來越高、速度也越來越快。基於region proposal(候選區域)的R-CNN系列目標檢測方法是目標檢測技術領域中的最主要分支之一。
牆裂建議
2014至2016年,Ross Girshick 等人發表了關於R-CNN、Fast R-CNN、Faster R-CNN的經典論文《Rich feature hierarchies for accurate object detection and semantic segmentation》、《Fast R-CNN》、《Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks》,在這些論文中對目標檢測的思想、原理、測試情況進行了詳細介紹,建議閱讀些篇論文以全面瞭解目標檢測模型。
請關注本人公眾號“大資料與人工智慧Lab”(BigdataAILab),然後回覆“論文”關鍵字可線上閱讀這些經典論文。
推薦相關閱讀