
大話文字檢測經典模型:Pixel-Anchor
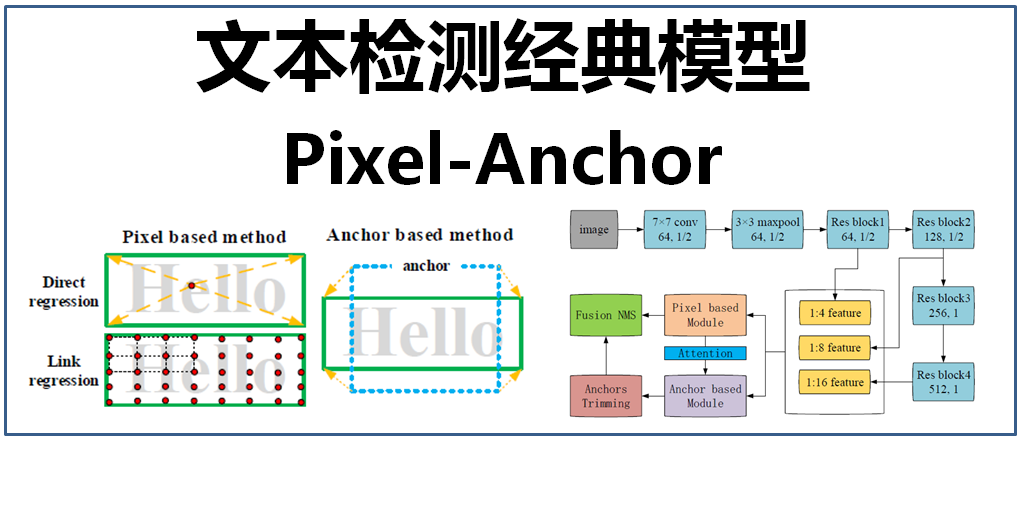
文字檢測是深度學習中一項非常重要的應用,在前面的文章中已經介紹過了很多文字檢測的方法,包括CTPN(詳見文章:大話文字檢測經典模型CTPN)、SegLink(詳見文章:大話文字檢測經典模型SegLink)、EAST(詳見文章:大話文字檢測經典模型EAST)、PixelLink(詳見文章:大話文字檢測經典模型PixelLink),這些文字檢測方法主要分為兩類,一類是基於畫素級別的影象語義分割方法(pixel-based),另一類是採用通用目標檢測(使用錨點)的方法(anchor-based),這兩種方法的優劣如下:
- 基於畫素級別的影象語義分割方法(pixel-based):通過影象語義分割獲得可能的文字畫素,通過畫素點進行迴歸或對文字畫素進行聚合得到文字框位置,經典的檢測模型有PixelLink、EAST等。該方法具有較高的精確率,但對於小尺度的文字由於畫素過於稀疏而導致檢測率不高(除非對影象進行大尺度放大)。
- 採用通用目標檢測(使用錨點)的方法(anchor-based):在通用物體檢測的基礎上,通過設定較多數量的不同長寬比的錨來適應文字尺度變化劇烈的特性,以達到文字定位的效果,經典的檢測模型有CTPN、SegLink等。該方法對文字尺度本身不敏感,對小尺度文字的檢測率高,但是對於較長且密集的文字行而言,錨匹配方式可能會無所適從(需要根據實際調整不同大小的網路感受野,以及錨的寬高比)。另外,由於該方法是基於文字整體的粗粒度特徵,而不是基於畫素級別的精細特徵,因此,檢測精度往往不如基於畫素級別的文字檢測。
pixel-based、anchor-based方法示意圖如下:
那麼有沒有將pixel-based和anchor-based兩種方法的優點結合在一起的檢測方法呢?
答案是有的,這就是本文要介紹的端到端深度學習文字檢測方法 Pixel-Anchor
1、Pixel-Anchor網路結構
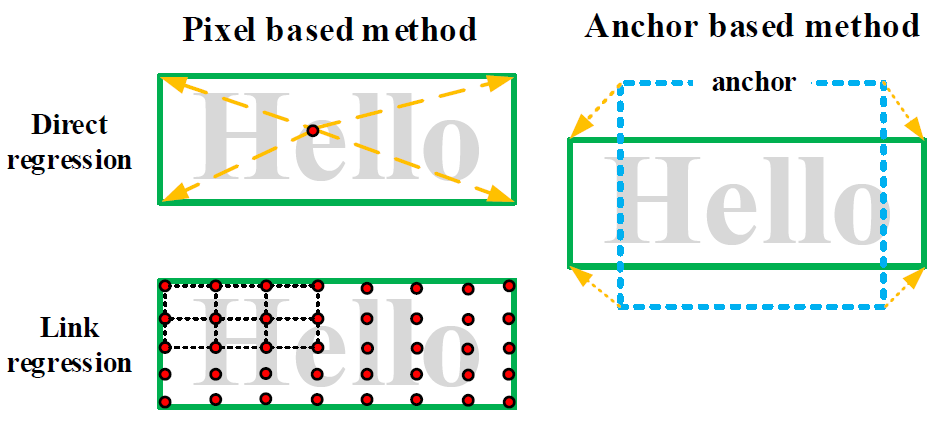
Pixel-Anchor的網路結構如下圖所示:

該網路採用ResNet-50作為網路的主幹結構(ResNet網路的介紹詳見文章:大話CNN經典模型ResNet),提取出1/4, 1/8, 1/16的feature map(特徵圖)出來,作為畫素級別語義分割模組(Pixel based Module)和錨檢測迴歸模組(Anchor based Module)的基礎特徵,通過特徵共享的方式把畫素級別語義分割和錨檢測迴歸放入到一個網路之中,其中,pixel-based模組得到的輸出結果通過注意力機制送入到anchor-based模組中(注意力機制的介紹詳見文章:
下面分別對畫素級別語義分割模組(Pixel based Module)和錨檢測迴歸模組(Anchor based Module)進行介紹。
2、畫素級別語義分割模組(Pixel based Module)
該模組的結構如下:
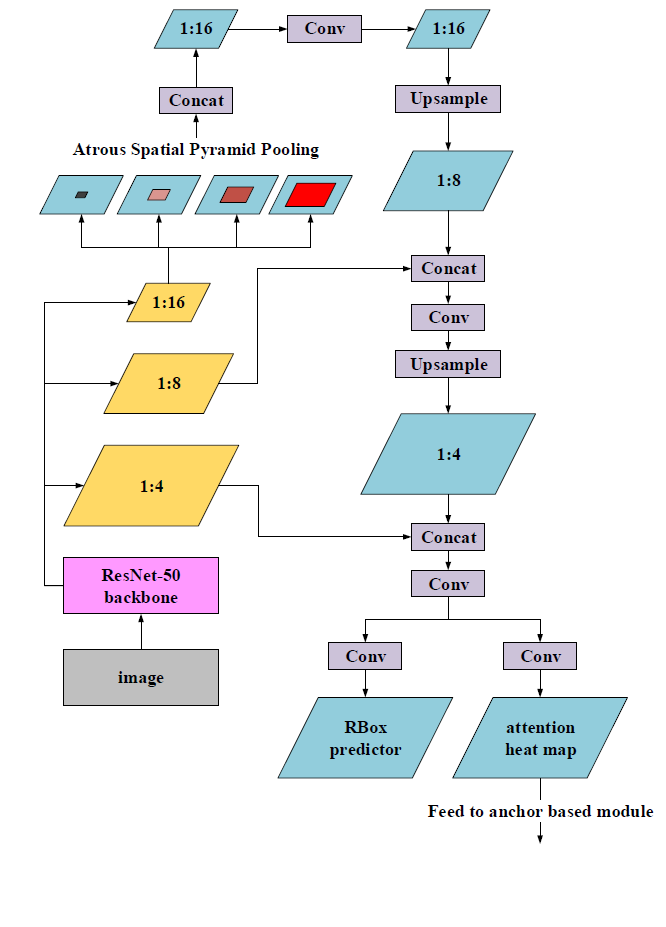
該結構將FPN(特徵金字塔網路)、ASPP(Atrous Spatial Pyramid Pooling,膨脹空間金字塔池化)操作組合在一起進行特徵提取和處理。
輸入影象首先經過ResNet-50主幹網路分別提取出1/4, 1/8, 1/16的feature map(特徵圖)形成特徵金字塔。在1/16的feature map(特徵圖)中,為了既不犧牲特徵空間解析度,又可擴大特徵感受野,採用了ASPP(Atrous Spatial Pyramid Pooling,膨脹空間金字塔池化)方法,這是一種低代價(low cost)的增加網路感受野的方法。那什麼是ASPP方法呢?
ASPP是利用Atrous Convolution(膨脹卷積),將不同擴張率的擴張卷積特徵結合到一起(如取最大值),如下圖:
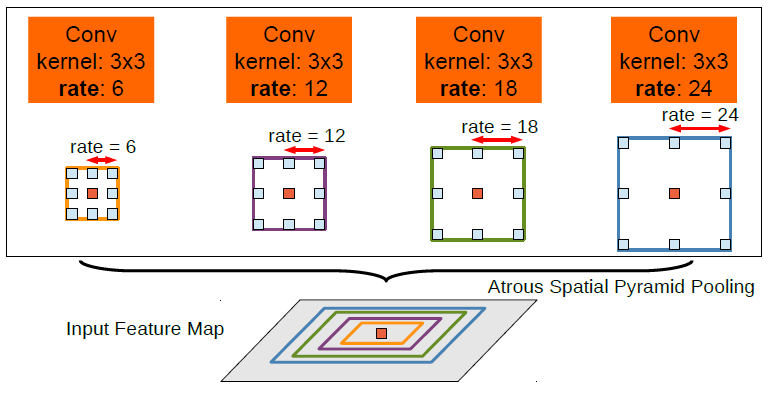
在這個pixel-based模組中設定ASPP的膨脹率為{3, 6, 9, 12, 15, 18}。接著作一次卷積操作(Conv),再用因子為2倍的雙線性插值進行上取樣(Upsample),特徵圖變為1/8,並和來自網路主幹的1/8特徵圖進行拼接(concat)。接下來重複一次,先做卷積(Conv),再進行上取樣(Upsample),特徵圖變為1/4,並和來自網路主幹的1/4特徵圖進行拼接(concat)。最後輸出兩部分:旋轉框預測器(RBox predictor)和注意力熱力圖(attention heat map)。
- 旋轉框預測器(RBox predictor)的結果包括6個通道,分別是每個畫素是文字的可能性、該畫素到所在文字邊界框的上下左右距離、文字邊界框的旋轉角度。
- 注意力熱力圖(attention heat map)包括一個通道,表示每個畫素是文字的可能性,將輸出到anchor-based模組。
3、錨檢測迴歸模組(Anchor based Module)
該模組的結構如下圖:
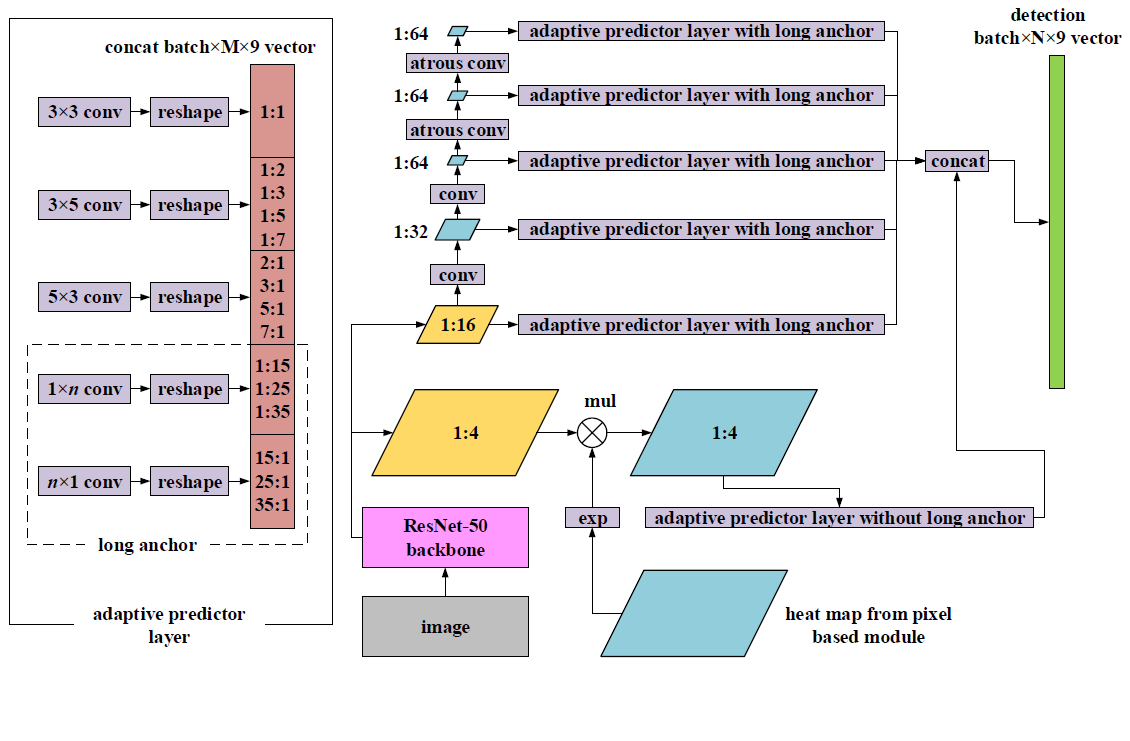
先看該圖的右半部分,該模組主要是針對輸入影象在ResNet-50中提取的1/4特徵圖、1/16特徵圖進行操作。
- 對於1/4特徵圖,由於其處於底層,具有一定的解析度,對於檢測較小的文字具有一定優勢,另外,為了增加該層的語義資訊,還與pixel-based模組輸出的注意力熱力圖(attention heat map)進行exp操作(exponential)和點乘,exp操作使每個畫素成為正樣本文字的概率對映到[1.0,e]範圍之內,既可保留背景資訊,又加強檢測資訊,可很大程度上減少錯誤檢測。
- 對於1/16特徵圖,為了獲取更大的感受野、獲得多尺度資訊,進一步進行特徵提取,分別為1/32特徵圖、1/64特徵圖、1/64特徵圖、1/64特徵圖,其中,為避免出現很小的特徵圖,在後面兩個特徵圖中,採用了atrous conv(膨脹卷積),以實現解析度不變,並能獲得較大感受野,這四層特徵圖在其後都加入APL層(adaptive predictor layer,自適應預測層)。
APL層(adaptive predictor layer,自適應預測層),見上圖的左半部分,該層分別為不同的卷積核搭配不同的寬高比錨,以適應不同尺度、不同角度的文字。主要分為以下5類:
- a)、正方形anchors:寬高比=1:1,卷積濾波器大小為3x3,主要為了檢測方正規整的文字;
- b)、中等水平anchors:寬高比={1:2,1:3,1:5,1:7},卷積濾波器大小為3x5,主要為了檢測水平傾斜的文字;
- c)、中等垂直anchors:寬高比={2:1,3:1,5:1,7:1},卷積濾波器大小為5x3,主要為了檢測垂直傾斜的文字;
- d)、長的水平anchors:寬高比={1:15,1:25,1:35},卷積濾波器大小為1xn,主要為了檢測水平長行的文字;
- e)、長的垂直anchors:寬高比={15:1,25:1,35:1},卷積濾波器大小為nx1,主要為了檢測豎排長行的文字。
經過以上APL層之後,將得到的proposal(候選框)進行拼接,從而預測最終的四邊形區域。
為了實現對密集文字的檢測,作者還提出了anchor density(錨密度),如下圖:
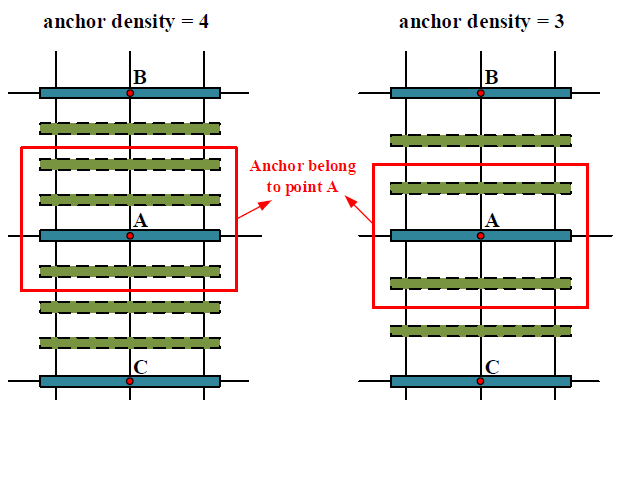
每個anchor(錨點)通過複製出一些偏移量以更好地覆蓋密度文字,主要有:
- 正方形anchor在水平和垂直方向都進行復制
- 水平anchor在垂直方向複製
- 垂直anchor在水平方向複製
4、後處理
在推導階段,採用融合NMS(非極大值抑制)方法獲得最終的檢測結果,用anchor-based模組檢測小文字和長文字,用pixel-based模組檢測中等大小的文字。在anchor-based模組,1/4特徵圖上的所有anchor(錨點)和在其它特徵圖上的所有長anchor(錨點)都會被保留下來,這些anchors足夠覆蓋小文字,而對於長文字、大角度文字,不具有檢測能力;在pixel-based模組,將小於10畫素,以及寬高比不在[1:15, 15:1]範圍內的文字過濾掉。最終,收集所有保留的候選文字框,通過融合NMS方法獲得最終的檢測結果。
5、Pixel-Anchor檢測效果
Pixel-Anchor在小文字、大角度文字、長文字行,以及自然場景文字檢測中,均取得了比較好的效果,如下圖:
(1)小文字檢測效果

(2)大角度文字檢測效果

(3)長文字行檢測效果

(4)自然場景文字檢測效果(基於ICDAR 2015)

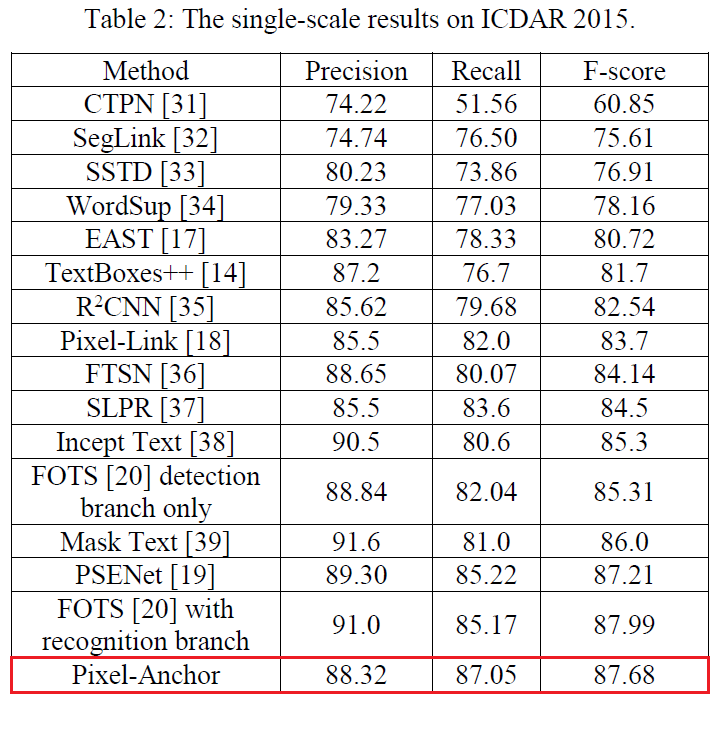
經在ICDAR 2015資料集上進行測試,並與CTPN、SegLink、EAST、Pixel-Link等方法進行對比,Pixel-Anchor方法的檢測效果非常不錯,如下表:
6、總結
Pixel-Anchor作為一個端對端的深度神經網路框架,對各種尺度、角度的文字均有很不錯的檢測效果,主要有兩大創新點:
- 第一是把畫素級別的影象語義分割以及基於錨的檢測迴歸方法通過共享基礎特徵、注意力機制高效融合在一起,使文字檢出率高、精準度高,實現可端到端訓練的檢測網路。
- 第二是在錨點檢測迴歸這個模組中引入了APL層(Adaptive Predictor Layer,自適應預測層),該層根據各特徵圖感受野的不同,調整錨的長寬比、卷積核的形狀以及錨的空間密度,以高效地獲取各特徵圖上的文字檢測結果,適應性更強。
推薦相關閱讀
1、AI 實戰系列
- 【AI實戰】手把手教你文字識別(文字檢測篇:MSER、CTPN、SegLink、EAST 等)
- 【AI實戰】手把手教你文字識別(入門篇:驗證碼識別)
- 【AI實戰】快速掌握TensorFlow(一):基本操作
- 【AI實戰】快速掌握TensorFlow(二):計算圖、會話
- 【AI實戰】快速掌握TensorFlow(三):激勵函式
- 【AI實戰】快速掌握TensorFlow(四):損失函式
- 【AI實戰】搭建基礎環境
- 【AI實戰】訓練第一個模型
- 【AI實戰】編寫人臉識別程式
- 【AI實戰】動手訓練目標檢測模型(SSD篇)
- 【AI實戰】動手訓練目標檢測模型(YOLO篇)
2、大話深度學習系列
- 【精華整理】CNN進化史
- 大話文字識別經典模型(CRNN)
- 大話文字檢測經典模型(CTPN)
- 大話文字檢測經典模型(SegLink)
- 大話文字檢測經典模型(EAST)
- 大話文字檢測經典模型(PixelLink)
- 大話文字檢測經典模型(Pixel-Anchor)
- 大話卷積神經網路(CNN)
- 大話迴圈神經網路(RNN)
- 大話深度殘差網路(DRN)
- 大話深度信念網路(DBN)
- 大話CNN經典模型:LeNet
- 大話CNN經典模型:AlexNet
- 大話CNN經典模型:VGGNet
- 大話CNN經典模型:GoogLeNet
- 大話目標檢測經典模型:RCNN、Fast RCNN、Faster RCNN
- 大話目標檢測經典模型:Mask R-CNN
- 大話注意力機制
3、圖解 AI 系列
4、AI 雜談
5、大資料超詳細系列