
大話文字檢測經典模型:EAST
自然場景的文字檢測是當前深度學習的重要應用,在之前的文章中已經介紹了基於深度學習的文字檢測模型CTPN、SegLink(見文章:大話文字檢測經典模型CTPN、大話文字檢測經典模型SegLink)。典型的文字檢測模型一般是會分多個階段(multi-stage)進行,在訓練時需要把文字檢測切割成多個階段(stage)來進行學習,這種把完整文字行先分割檢測再合併的方式,既影響了文字檢測的精度又非常耗時,對於文字檢測任務上中間過程處理得越多可能效果會越差。那麼有沒有又快、又準的檢測模型呢?
一、EAST模型簡介
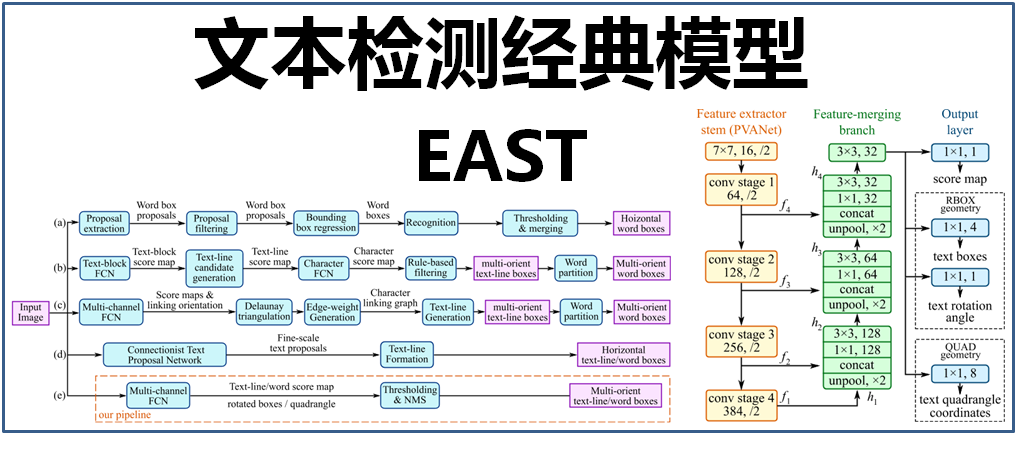
本文介紹的文字檢測模型EAST,便簡化了中間的過程步驟,直接實現端到端文字檢測,優雅簡潔,檢測的準確性和速度都有了進一步的提升。如下圖:
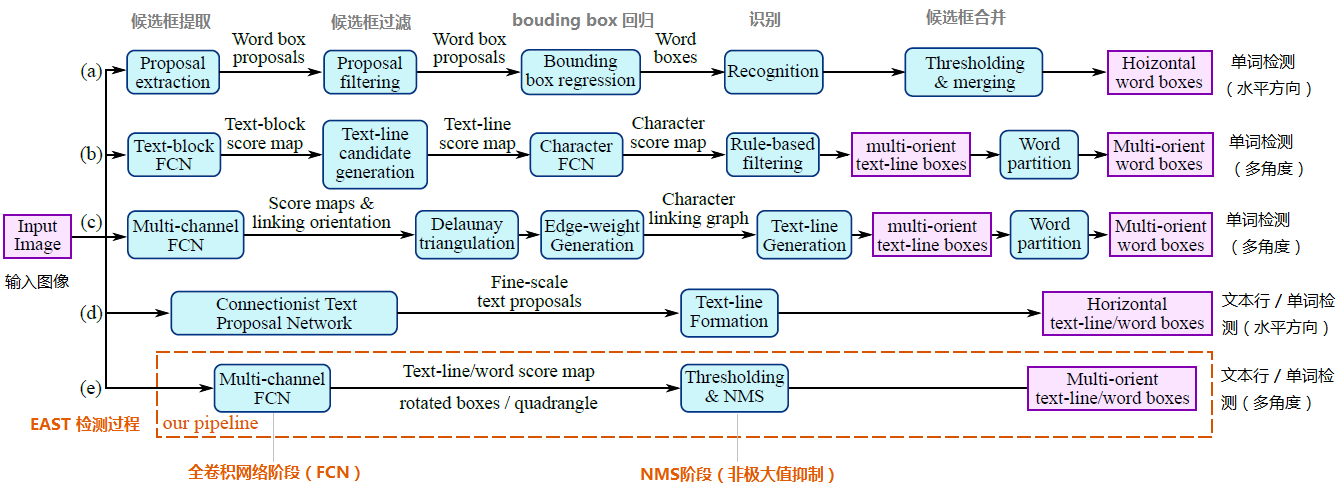
其中,(a)、(b)、(c)、(d)是幾種常見的文字檢測過程,典型的檢測過程包括候選框提取、候選框過濾、bouding box迴歸、候選框合併等階段,中間過程比較冗長。而(e)即是本文介紹的EAST模型檢測過程,從上圖可看出,其過程簡化為只有FCN階段(全卷積網路)、NMS階段(非極大抑制),中間過程大大縮減,而且輸出結果支援文字行、單詞的多個角度檢測,既高效準確,又能適應多種自然應用場景。(d)為CTPN模型,雖然檢測過程與(e)的EAST模型相似,但只支援水平方向的文字檢測,可應用的場景不如EAST模型。如下圖:

二、EAST模型網路結構
EAST模型的網路結構,如下圖:
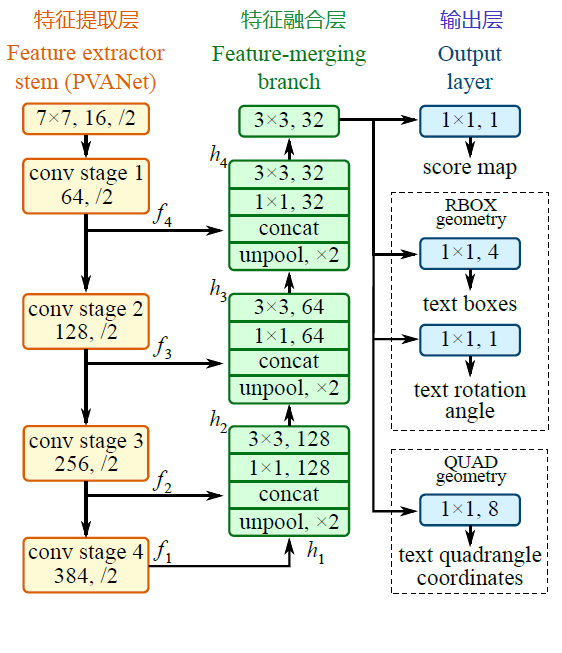
EAST模型的網路結構分為特徵提取層、特徵融合層、輸出層三大部分。
下面展開進行介紹:
1、特徵提取層
基於PVANet(一種目標檢測的模型)作為網路結構的骨幹,分別從stage1,stage2,stage3,stage4的卷積層抽取出特徵圖,卷積層的尺寸依次減半,但卷積核的數量依次增倍,這是一種“金字塔特徵網路”(FPN,feature pyramid network)的思想。通過這種方式,可抽取出不同尺度的特徵圖,以實現對不同尺度文字行的檢測(大的feature map擅長檢測小物體,小的feature map擅長檢測大物體)。這個思想與前面文章介紹的SegLink模型很像;
2、特徵融合層
將前面抽取的特徵圖按一定的規則進行合併,這裡的合併規則採用了U-net方法,規則如下:
- 特徵提取層中抽取的最後一層的特徵圖(f1)被最先送入unpooling層,將影象放大1倍
- 接著與前一層的特徵圖(f2)串起來(concatenate)
- 然後依次作卷積核大小為1x1,3x3的卷積
- 對f3,f4重複以上過程,而卷積核的個數逐層遞減,依次為128,64,32
- 最後經過32核,3x3卷積後將結果輸出到“輸出層”
3、輸出層
最終輸出以下5部分的資訊,分別是:
- score map:檢測框的置信度,1個引數;
- text boxes:檢測框的位置(x, y, w, h),4個引數;
- text rotation angle:檢測框的旋轉角度,1個引數;
- text quadrangle coordinates:任意四邊形檢測框的位置座標,(x1, y1), (x2, y2), (x3, y3), (x4, y4),8個引數。
其中,text boxes的位置座標與text quadrangle coordinates的位置座標看起來似乎有點重複,其實不然,這是為了解決一些扭曲變形文字行,如下圖:
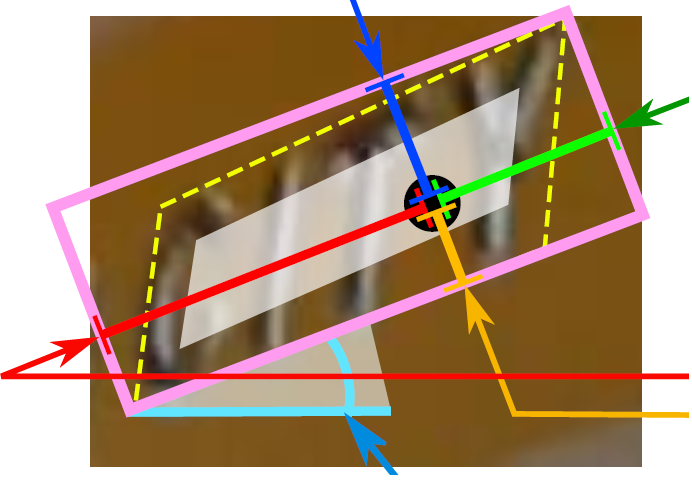
如果只輸出text boxes的位置座標和旋轉角度(x, y, w, h,θ),那麼預測出來的檢測框就是上圖的粉色框,與真實文字的位置存在誤差。而輸出層的最後再輸出任意四邊形的位置座標,那麼就可以更加準確地預測出檢測框的位置(黃色框)。
三、EAST模型效果
EAST文字檢測的效果如下圖,其中,部分有仿射變換的文字行的檢測效果(如廣告牌)

EAST模型的優勢在於簡潔的檢測過程,高效、準確,並能實現多角度的文字行檢測。但也存在著不足之處,例如(1)在檢測長文字時的效果比較差,這主要是由於網路的感受野不夠大;(2)在檢測曲線文字時,效果不是很理想
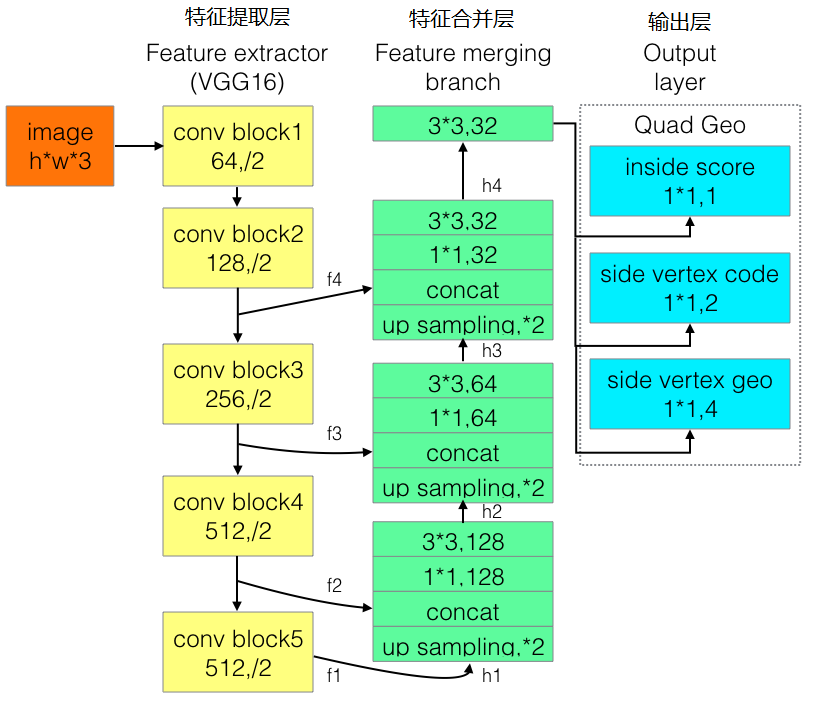
四、Advanced EAST
為改進EAST的長文字檢測效果不佳的缺陷,有人提出了Advanced EAST,以VGG16作為網路結構的骨幹,同樣由特徵提取層、特徵合併層、輸出層三部分構成。經實驗,Advanced EAST比EAST的檢測準確性更好,特別是在長文字上的檢測。
網路結構如下:
牆裂建議
2017年,Xinyu Zhou 等人發表了關於EAST的經典論文《 EAST: An Efficient and Accurate Scene Text Detector 》,在論文中詳細介紹了EAST的技術原理,建議閱讀該論文以進一步瞭解該模型。
推薦相關閱讀
- 【AI實戰】手把手教你文字識別(入門篇:驗證碼識別)
- 【AI實戰】快速掌握TensorFlow(一):基本操作
- 【AI實戰】快速掌握TensorFlow(二):計算圖、會話
- 【AI實戰】快速掌握TensorFlow(三):激勵函式
- 【AI實戰】快速掌握TensorFlow(四):損失函式
- 【AI實戰】搭建基礎環境
- 【AI實戰】訓練第一個模型
- 【AI實戰】編寫人臉識別程式
- 【AI實戰】動手訓練目標檢測模型(SSD篇)
- 【AI實戰】動手訓練目標檢測模型(YOLO篇)
- 【精華整理】CNN進化史
- 大話文字識別經典模型(CRNN)
- 大話文字檢測經典模型(CTPN)
- 大話文字檢測經典模型(SegLink)
- 大話文字檢測經典模型(EAST)
- 大話卷積神經網路(CNN)
- 大話迴圈神經網路(RNN)
- 大話深度殘差網路(DRN)
- 大話深度信念網路(DBN)
- 大話CNN經典模型:LeNet
- 大話CNN經典模型:AlexNet
- 大話CNN經典模型:VGGNet
- 大話CNN經典模型:GoogLeNet
- 大話目標檢測經典模型:RCNN、Fast RCNN、Faster RCNN
- 大話目標檢測經典模型:Mask R-CNN
- 27種深度學習經典模型
- 淺說“遷移學習”
- 什麼是“強化學習”
- AlphaGo演算法原理淺析
- 大資料究竟有多少個V
- Apache Hadoop 2.8 完全分散式叢集搭建超詳細教程
- Apache Hive 2.1.1 安裝配置超詳細教程
- Apache HBase 1.2.6 完全分散式叢集搭建超詳細教程
- 離線安裝Cloudera Manager 5和CDH5(最新版5.13.0)超詳