
長短時記憶網路LSTM
因為迴圈神經網路很難訓練的原因,這導致了它在實際應用中,很難處理長距離的依賴。我們將介紹一種改進之後的迴圈神經網路:長短時記憶網路(Long Short Term Memory Network, LSTM),它成功的解決了原始迴圈神經網路的缺陷,成為當前最流行的RNN,在語音識別、圖片描述、自然語言處理等許多領域中成功應用。但不幸的一面是,LSTM的結構很複雜,因此,我們再介紹一種LSTM的變體:GRU (Gated Recurrent Unit)。 它的結構比LSTM簡單,而效果卻和LSTM一樣好,因此,它正在逐漸流行起來。
原始RNN的隱藏層只有一個狀態,即h,它對於短期的輸入非常敏感。那麼,假如我們再增加一個狀態,即c,讓它來儲存長期的狀態,那麼問題不就解決了麼?如下圖所示:
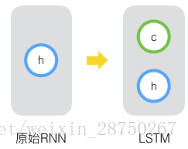
新增加的狀態c,稱為單元狀態(cell state)。我們把上圖按照時間維度展開:
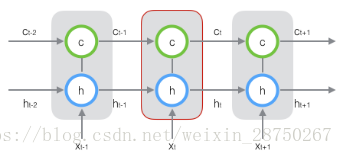
上圖僅僅是一個示意圖,我們可以看出,在t時刻,LSTM的輸入有三個:當前時刻網路的輸入值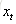

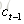

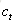
LSTM的關鍵,就是怎樣控制長期狀態
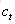
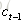
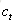
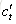
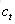
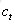
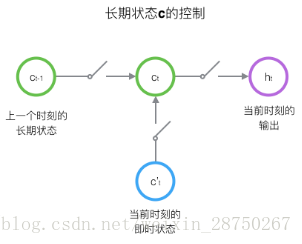
接下來,我們要描述一下,輸出

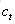 的具體計算方法。
的具體計算方法。
LSTM前向計算:
門的概念:假設W是該門的權重向量,b是偏置項,則: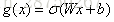
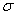

遺忘門:它決定了上一時刻的單元狀態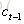
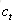
輸入門:它決定了針對當前輸入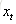
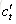

輸出門
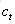 有多少輸出到LSTM的當前輸出值
有多少輸出到LSTM的當前輸出值 。
。
這幾個門與上述的開關相配合來計算當前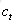

如上圖所示:這三個門: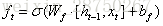

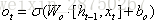
輸入都為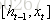
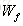
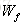
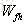
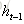
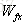
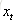
針對於當前輸入的單元狀態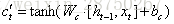
則所求的: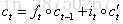

LSTM訓練演算法:
LSTM的訓練演算法仍然是反向傳播演算法,對於這個演算法,我們已經非常熟悉了。主要有下面三個步驟:
1.前向計算每個神經元的輸出值,對於LSTM來說,即
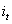
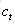


2.反向計算每個神經元的誤差項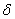
3.根據相應的誤差項,計算每個權重的梯度。
誤差項沿時間的反向傳遞:
在t時刻,LSTM的輸出值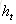

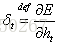

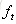
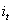

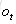

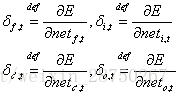
推導過程參見部落格,最後得到公式:

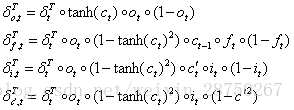
那麼我們就得到誤差項向前傳遞到任意時刻k的公式:
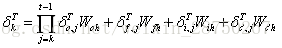
將誤差傳遞到上一層:
我們假設當前為第l層,定義l-1層的誤差項是誤差函式對l-1層加權輸入的導數,即:
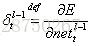

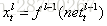
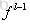
推導過程不再多說,得到: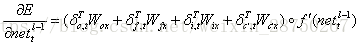
權重梯度計算:
對於
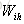
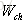
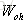

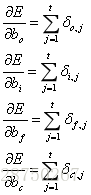
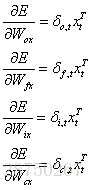
以上就是LSTM訓練演算法全部公式。
GRU:
事實上LSTM存在很多變體,在眾多的LSTM變體中,GRU (Gated Recurrent Unit)也許是最成功的一種。它對LSTM做了很多簡化,同時卻保持著和LSTM相同的效果。因此,GRU最近變得越來越流行。GRU對LSTM做了兩個大改動:
- 將輸入門、遺忘門、輸出門變為兩個門:更新門(Update Gate)
和重置門(Reset Gate)
。
- 將單元狀態與輸出合併為一個狀態:
。
GRU示意圖:

由示意圖可知,GRU前向計算公式為: