
Spark中reduce和reducebykey
阿新 • • 發佈:2019-02-16
首先我們先講講兩個函式在功能上的作用與區別是什麼,然後我們再深入討論兩個函式在內部機理有什麼不同。
reduce(binary_function)
reduce將RDD中元素前兩個傳給輸入函式,產生一個新的return值,新產生的return值與RDD中下一個元素(第三個元素)組成兩個元素,再被傳給輸入函式,直到最後只有一個值為止。
具體過程,RDD有1 2 3 4 5 6 7 8 9 10個元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
reduceByKey(binary_function)
reduceByKey就是對元素為KV對的RDD中Key相同的元素的Value進行binary_function的reduce操作,因此,Key相同的多個元素的值被reduce為一個值,然後與原RDD中的Key組成一個新的KV對。
那麼講到這裡,差不多函式功能已經明瞭了,而reduceByKey的是如何執行的呢?下面這張圖就清楚了揭示了其原理:
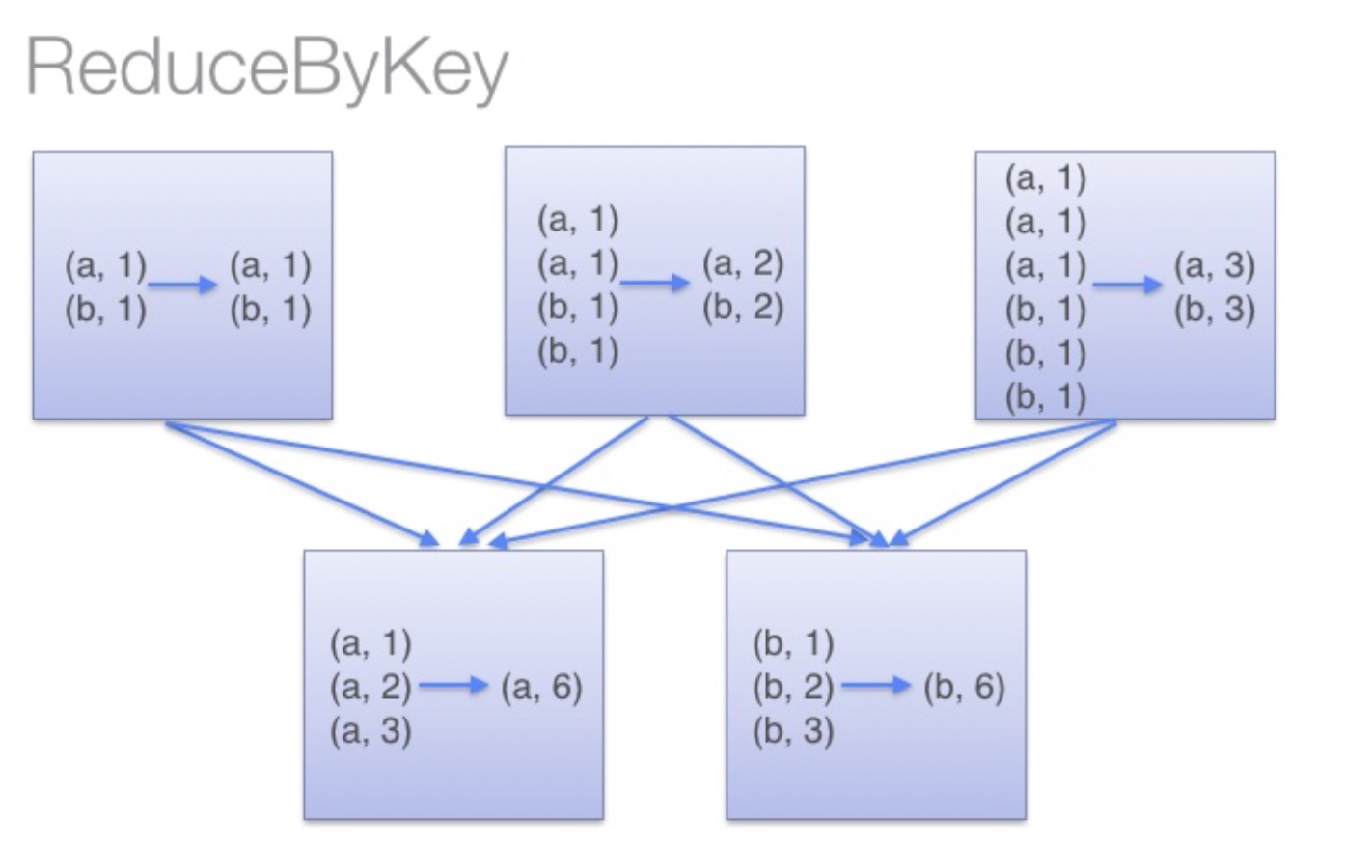
亦即,它會在資料搬移以前,提前進行一步reduce操作。
可以實現同樣功能的還有GroupByKey函式,但是,groupbykey函式並不能提前進行reduce,也就是說,上面的處理過程會翻譯成這樣:
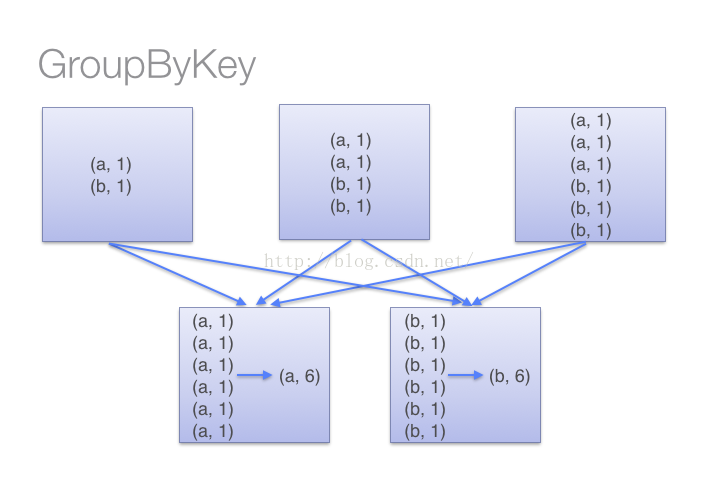
所以在處理大規模應用的時候,應該使用reduceByKey函式。