
使用感知機進行二類分類的線性分類模型測試(minst資料集)
遂手動實現跑了一遍,再次記錄過程中遇到的一些問題。
首先在anaconda環境下配置所需要的資料分析及圖片處理包:
pandas(python的資料分析模組 Powerful python data analysis toolkit)
numpy(矩陣處理)
scikit-learn (封裝機器學習模組 在此例項中用來拆分資料集)
cv2 (OpenCV影象處理自帶python介面)
前三個可到anaconda中搜索找到並安裝:
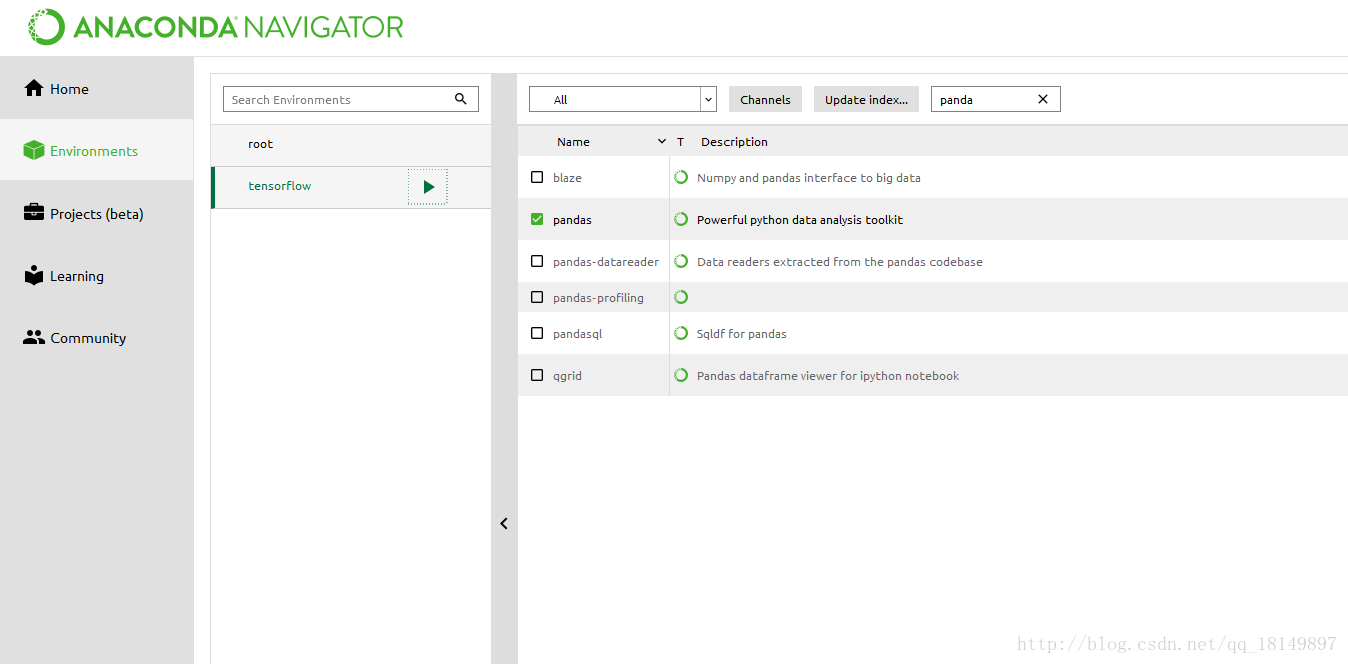
在安裝第四個的時候出現問題:
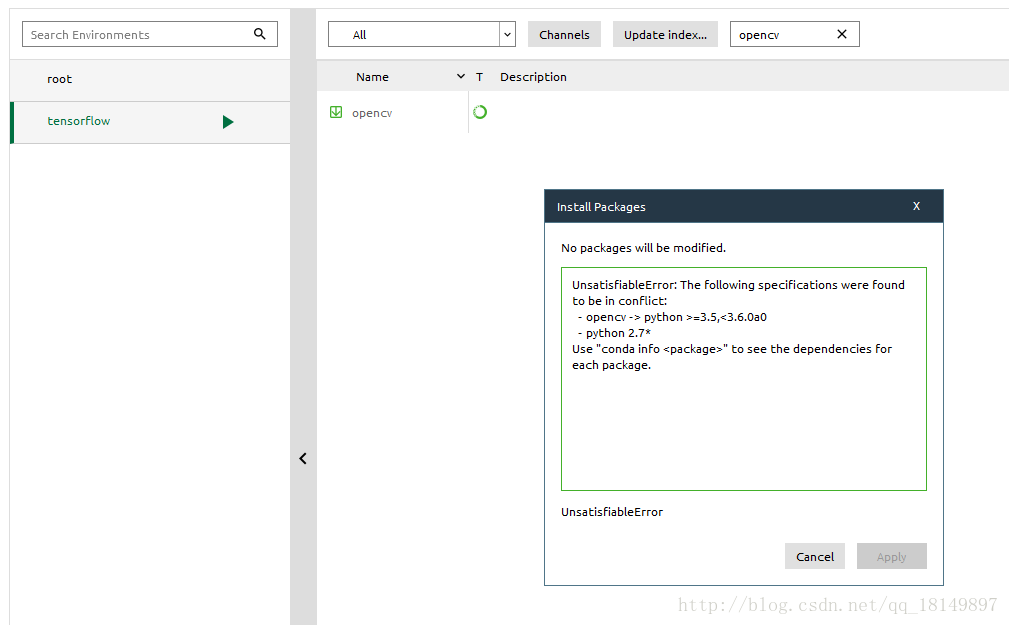
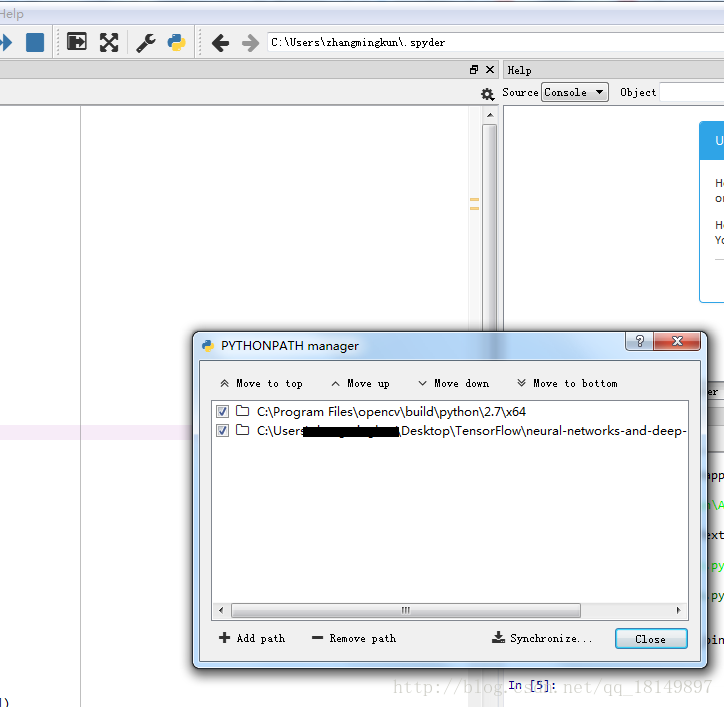
網上找了半天沒搞明白,所以直接在單獨安裝了openCV,在OpenCV官網
上下載安裝,並使用spyder自帶的python依賴包管理器指向並同步,然後解決。
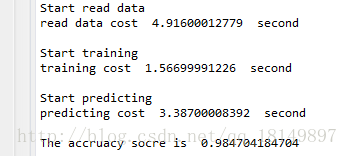
然後執行程式碼,結果:
相關推薦
使用感知機進行二類分類的線性分類模型測試(minst資料集)
遂手動實現跑了一遍,再次記錄過程中遇到的一些問題。 首先在anaconda環境下配置所需要的資料分析及圖片處理包: pandas(python的資料分析模組 Powerful python data analysis toolkit) num
基於Darknet框架訓練分類器(cifar10資料集)+windows
參考 https://pjreddie.com/darknet/train-cifar/ 1 下載資料集 https://pjreddie.com/media/files/cifar.tgz 在該網址下下載cifar資料集,並解壓在darknet.exe
TensorFlow學習筆記(4)--實現多層感知機(MNIST資料集)
前面使用TensorFlow實現一個完整的Softmax Regression,並在MNIST資料及上取得了約92%的正確率。現在建含一個隱層的神經網路模型(多層感知機)。 import tensorflow as tf import numpy as np
電影評論分類:二分類問題(IMDB資料集)
IMDB資料集是Keras內部整合的,初次匯入需要下載一下,之後就可以直接用了。 IMDB資料集包含來自網際網路的50000條嚴重兩極分化的評論,該資料被分為用於訓練的25000條評論和用於測試的25000條評論,訓練集和測試集都包含50%的正面評價和50%的負
用Keras進行手寫字型識別(MNIST資料集)
資料 首先載入資料 from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() 接下來,看
ML:教你聚類並構建學習模型處理資料(附資料集)
本文將根據41個描述性分類特徵的維度,運用無監督主成分分析(PCA)和層次聚類方法對觀測進行分組。將資料聚類可以更好地用簡單的多元線性模型描述資料或者識別更適合其他模型的異常組。此方法被編寫在python類中,以便將來能實現類似網格搜尋的引數優化。 結果與討論 本專案
TensorFlow學習筆記(1):使用softmax對手寫體數字(MNIST資料集)進行識別
使用softmax實現手寫體數字識別完整程式碼如下: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input
Python機器學習庫sklearn裡利用感知機進行三分類(多分類)的原理
from IPython.display import Image %matplotlib inline # Added version check for recent scikit-learn 0.18 checks from distutils.vers
多層感知機MLP的gluon版分類minist
MLP_Gluon
筆記︱風控分類模型種類(決策、排序)比較與模型評估體系(ROC/gini/KS/lift)
轉載自素質雲部落格。本筆記源於CDA-DSC課程,由常國珍老師主講。該訓練營第一期為風控主題,培訓內容十分緊湊,非常好,推薦:CDA資料科學家訓練營 —————————————————————————————————————————— 一、風控建
tensorflow實現多層感知機進行手寫字識別
logits=multilayer_perceptron(X) #使用交叉熵損失 loss_op=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=Y))
我的Keras使用總結(2)——構建影象分類模型(針對小資料集)
Keras基本的使用都已經清楚了,那麼這篇主要學習如何使用Keras進行訓練模型,訓練訓練,主要就是“練”,所以多做幾個案例就知道怎麼做了。 在本文中,我們將提供一些面向小資料集(幾百張到幾千張圖片)構造高效,實用的影象分類器的方法。 1,熱身練習——CIFAR10 小圖片分類示例(Sequentia
分類和迴歸的區別(在CNN中)
兩者的本質相同,分類和迴歸的區別在於輸出變數的型別。 定量——連續——迴歸 定性——離散——分類 用於迴歸:最後一層有m個神經元,每個神經元輸出一個標量,m個神經元的輸出可以看作向量V,現全部連到一個神經元上,則這個神經元的輸出為wx+b,是一個連續值,可以處理迴歸問題 用於分類:現
小專案(文字資料分析)--新聞分類任務
1.資料 import pandas as pd import jieba #資料(一小部分的新聞資料) df_news = pd.read_table('val.txt',names=['category','theme','URL','content'],encoding='ut
關於多臺虛擬機進行自動化部署的問題匯總(小白做筆記記錄之用,大神請繞路~)
title ssh ide pan col 存在 timeout 文件中 boot.s 首先貼上shell腳本代碼(代碼的前提條件是 1.首先已經在各臺虛擬機上都配置了repo的本地yum軟鏈接,源服務器起名min2 2.通過yum 下載scp軟件 (用於跨機器進行文件傳輸
【Keras】使用Keras開發的流程(IMDB資料集電影評論二分類)
Keras簡介 \quad\quad Keras是一個Python深度學習框架,是一個模型級的庫,為開發深度學習模型
機器學習分類演算法之K近鄰(K-Nearest Neighbor)
一、概念 KNN主要用來解決分類問題,是監督分類演算法,它通過判斷最近K個點的類別來決定自身類別,所以K值對結果影響很大,雖然它實現比較簡單,但在目標資料集比例分配不平衡時,會造成結果的不準確。而且KNN對資源開銷較大。 二、計算 通過K近鄰進行計算,需要: 1、載入打標好的資料集,然
多分類(softmax處理iris資料集)
# -*- coding: utf-8 -*- # @Time : 2018/12/14 10:08 # @Author : WenZhao # @Email : [email protected] # @File : iris.py # @Software: PyC
深度學習框架tensorflow學習與應用4(MNIST資料集分類的簡單版本示例)
資料集 我們要訓練機器學習, 那麼就要用到訓練資料. 這次我們使用MNIST_data資料集 在程式中要匯入該資料集, 語句:mnist = input_data.read_data_sets("MNIST_data", one_hot=True)one_hot 意思是把資料集變成[
用基於center loss的人臉識別模型對LFW人臉資料集進行評測(c++)
接上一篇博文,這篇博文主要是進行人臉識別中的第③和第四個步驟:特徵提取以及相似度計算。 center loss是2016的一篇ECCV論文中提出來的,A Discriminative Feature Learning Approach for De