
Coursera機器學習-第五週-Neural Network BackPropagation
Cost Function and Backpropagation
假設有樣本m個。
當遇到二分問題時,
遇到K分類問題時,
例如遇到5分類問題時,輸出並不是
我們先看Logistic Regression Cost Function:
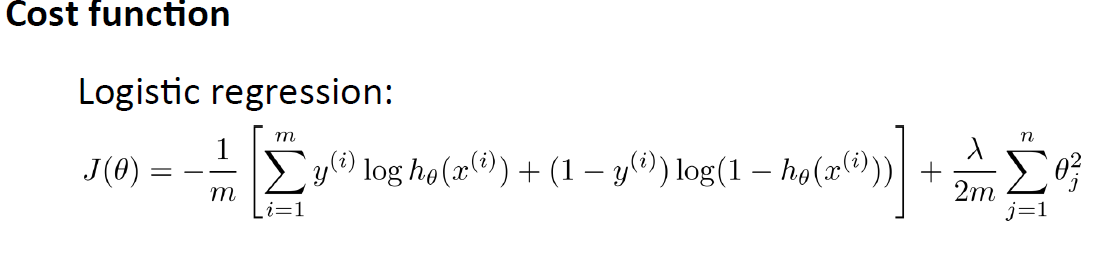
m表示樣本個數,前半部分表示假設與樣本之間的誤差之和,後半部分是正則項(不包括bias terms)
logistic regression一般用於二分類,所以cost function寫成上式,那麼神經網路的Cost Function如何寫呢?它可是K分類(
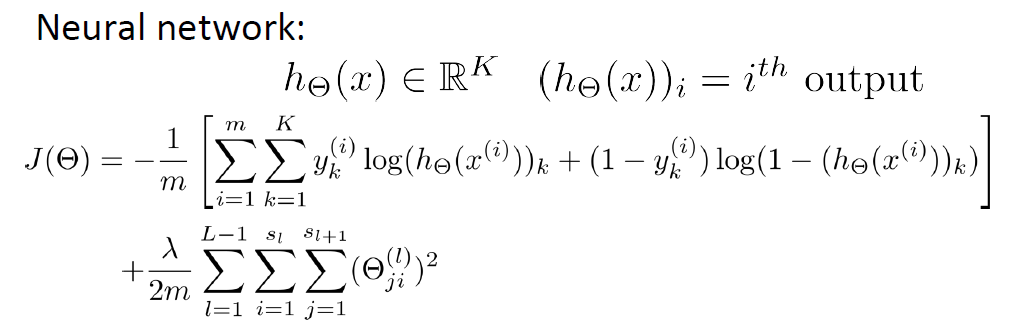
其實,就是在上述的基礎之上,對每個類的輸出進行加和,後半部分是對bias項所有引數的平方和(不包括bias terms)
從第四周的課程當中,我們已經瞭解到了向前傳播(Forward Propagation),向後傳播(BackPropagation)無非是方向相反罷了。
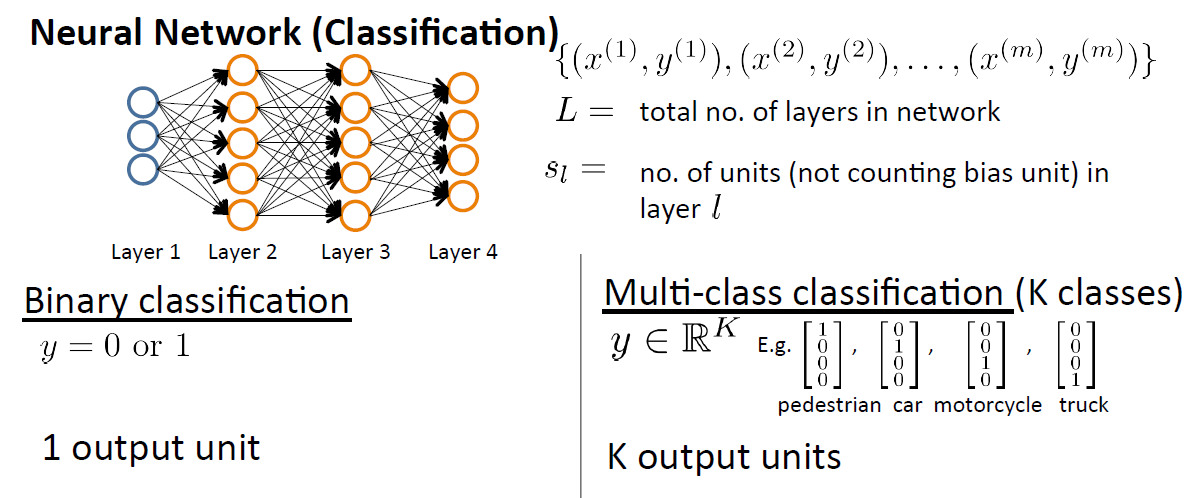
先簡述一下BP神經網路,下圖是神經網路的示意圖:
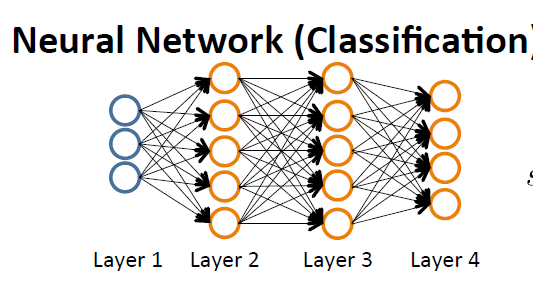
Layer1,相當於外界的刺激,是刺激的來源並且將刺激傳遞給神經元,因此把Layer1命名為輸入層(Input Layer)。Layer2-Layer3,表示神經元相互之間傳遞刺激相當於人腦裡面,因此命名為隱藏層(Hidden layers)。Layer4,表示神經元經過多層次相互傳遞後對外界的反應,因此Layer4命名為輸出層(Output Layer)。
簡單的描述就是,輸入層將刺激傳遞給隱藏層,隱藏層通過神經元之間聯絡的強度(權重)和傳遞規則(啟用函式)將刺激傳到輸出層,輸出層整理隱藏層處理的後的刺激產生最終結果。若有正確的結果,那麼將正確的結果和產生的結果進行比較,得到誤差,再逆推對神經網中的連結權重進行反饋修正,從而來完成學習的過程。這就是BP神經網的反饋機制,也正是BP(Back Propagation)名字的來源:運用向後反饋的學習機制,來修正神經網中的權重,最終達到輸出正確結果的目的!
那麼,演算法是如何實現的呢?如何向後傳播呢?
在BackPropagation中,定義了一個:

表示l層節點j的殘差,殘差是指實際觀察值與估計值(擬合值)之間的差。
那麼
由上面提到的定義:殘差是指實際觀察值與估計值(擬合值)之間的差,那麼對於Layer4而言
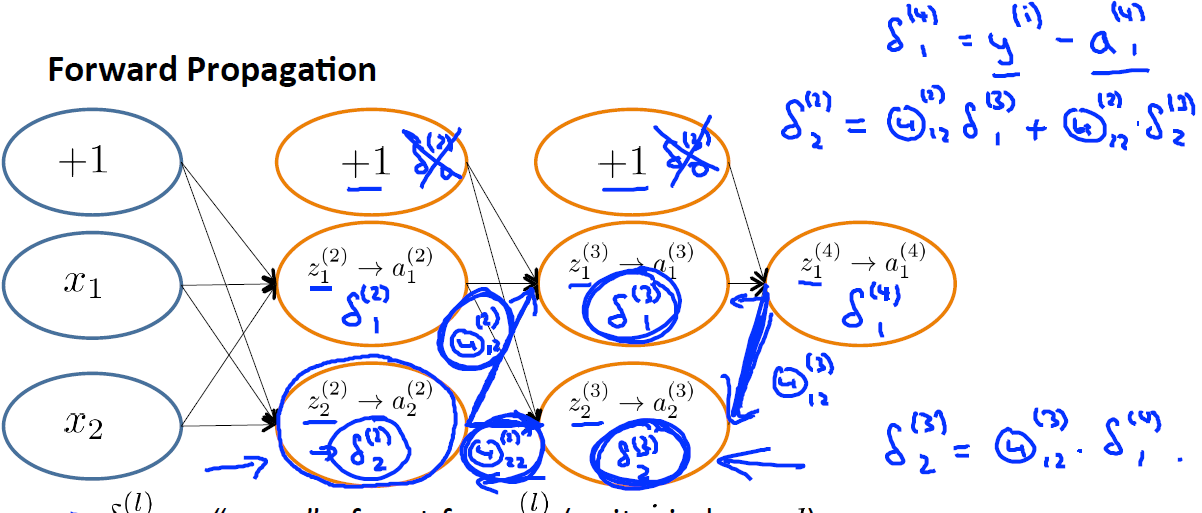
Forward Propagation:
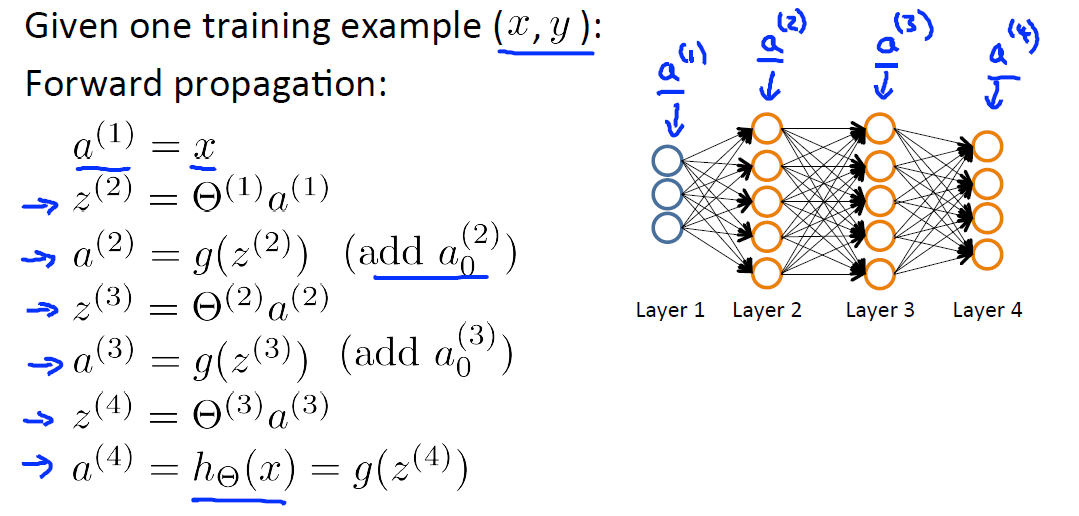
對於
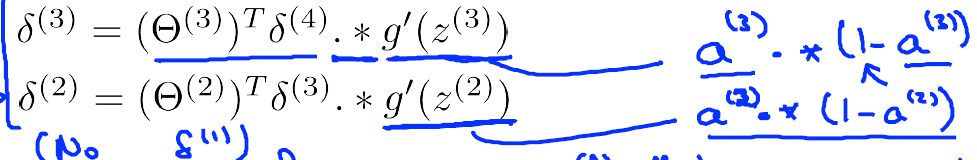
由此,我們得到計算

ps:最後一步之所以寫+=而非直接賦值是把Δ看做了一個矩陣,每次在相應位置上做修改。
從後向前此計算每層依的δ,用Δ表示全域性誤差,每一層都對應一個Δ(l)。再引入D作為cost function對引數的求導結果。下圖左邊j是否等於0影響的是否有最後的bias regularization項。左邊是定義,右邊可證明(比較繁瑣)。

Backpropagation in Practice
1.向前傳播 Forward propagation,得到每個權重
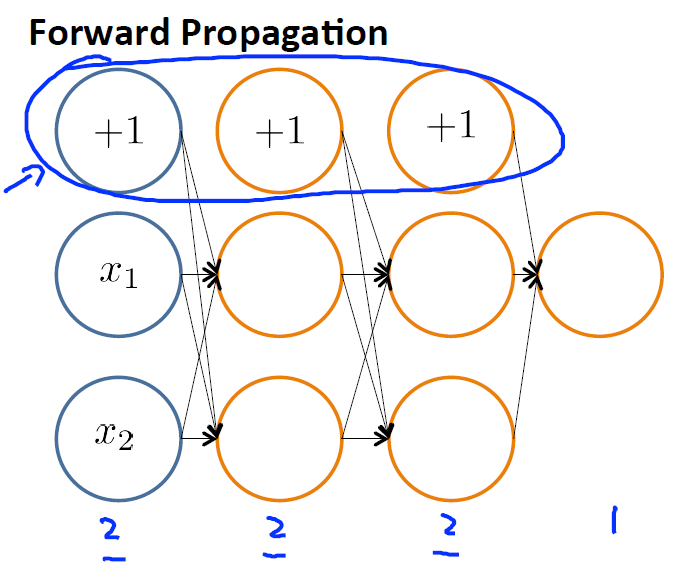
PS:bias units 並不算在內。所以1,2,3層的神經元個數為2,而不是3
2.簡化神經網路的代價函式(去除正則項,即
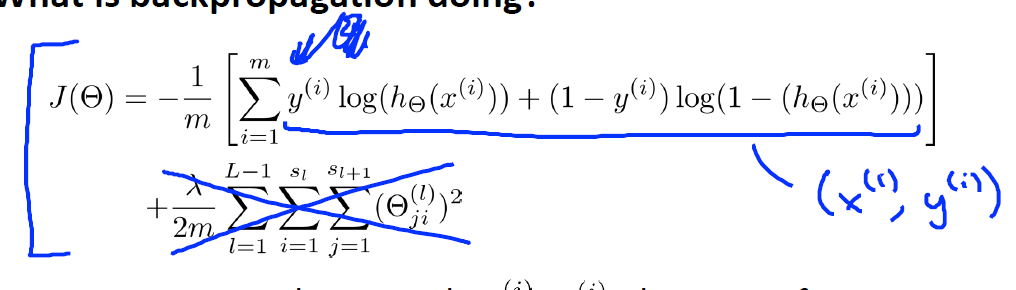
我們僅關注一個樣本
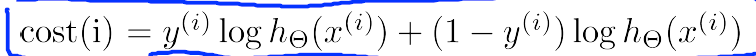
3.計算誤差
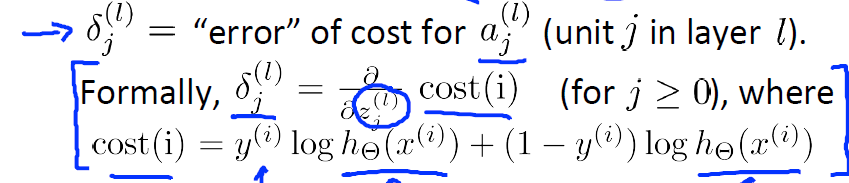
BP演算法主要是從輸出層反向計算各個節點的誤差的,故稱之為反向傳播演算法,對於上例,計算的過程如下圖所示:
換句話說, 對於每一層來說,
這節主要是講引數的向量化,以及將其還原

具體不懂可以實踐一下。
神經網路中的引數很多,如何檢測自己所編寫的程式碼是否正確?
對於下面這個
對於每個引數的求導公式如下圖所示

由於在back-propagation演算法中我們一直能得到J(Θ)的導數D(derivative),那麼就可以將這個近似值與D進行比較,如果這兩個結果相近就說明code正確,否則錯誤,如下圖所示:

實現時的注意點:
- 首先實現反向傳播演算法來計算梯度向量DVec;
- 其次實現梯度的近似gradApprox;
- 確保以上兩步計算的值是近似相等的;
- 在實際的神經網路學習時使用反向傳播演算法,並且關掉梯度檢查。
特別重要的是:
一定要確保在訓練分類器時關閉梯度檢查的程式碼。如果你在梯度下降的每輪迭代中都執行數值化的梯度計算,你的程式將會非常慢。
如何初始化引數向量or矩陣。通常情況下,我們會將引數全部初始化為0,這對於很多問題是足夠的,但是對於神經網路演算法,會存在一些問題,以下將會詳細的介紹。
對於梯度下降和其他優化演算法,對於引數

看下圖,如果將引數全設定為0
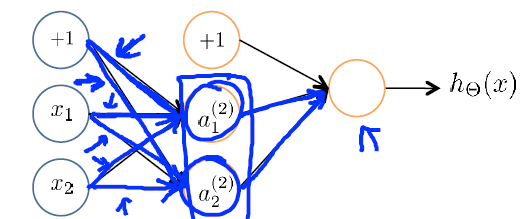
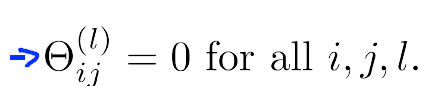
會導致一個問題,例如對於上面的神經網路的例子,如果將引數全部初始化為0,在每輪引數更新的時候,與輸入單元相關的兩個隱藏單元的結果將是相同的,
因此,我們需要隨機初始化:

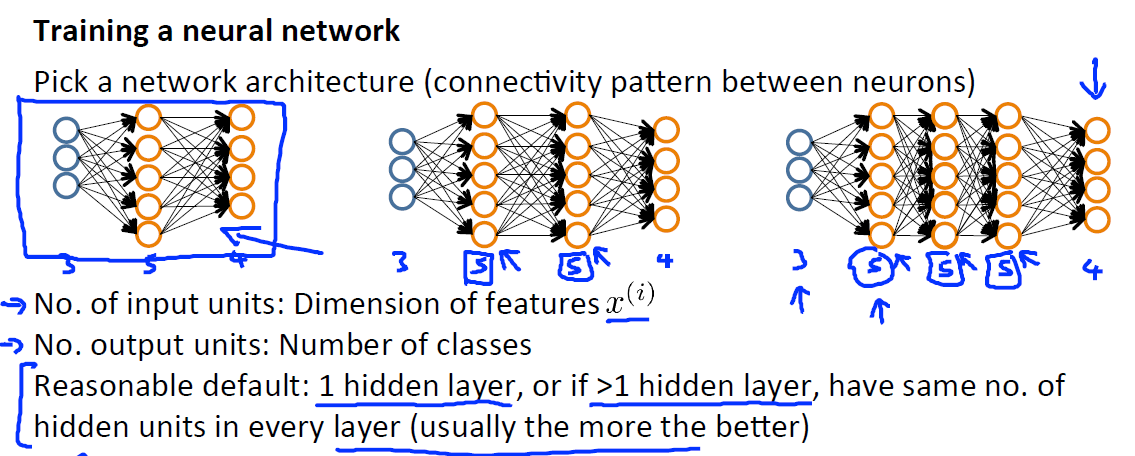
首先需要確定一個神經網路的結構-神經元的連線模式, 包括:
輸入單元的個數:特徵
輸出單元的格式:類的個數
隱藏層的設計:比較合適的是1個隱藏層,如果隱藏層數大於1,確保每個隱藏層的單元個數相同,通常情況下隱藏層單元的個數越多越好。


在確定好神經網路的結構後,我們按如下的步驟訓練神經網路:
隨機初始化權重引數;
實現:對於每一個
x(i) 通過前向傳播得到hθ(x(i)) ;實現:計算代價函式
J(θ) ;實現:反向傳播演算法用於計算偏導數